





CopyRight 2009-2020 © All Rights Reserved.版权所有: 中国海关未经授权禁止复制或建立镜像

基于LSTM神经网络模型对大宗矿产资源放行风险预测研究
作者:张彦彬1 苏 杨1 许亚春3 彭速标1 徐国江2 刘阳丽2 钟志光1 萧达辉1
张彦彬1 苏 杨1 许亚春3 彭速标1 徐国江2 刘阳丽2 钟志光1 萧达辉1
摘 要 本文旨在研究准确预测大宗矿产资源的放行风险,采用海关2016年至2020年的进口大宗矿产资源通关数据,选取22个特征值,基于TensorFlow框架,建立了LSTM神经网络时间序列模型,并将该模型用于预测大宗矿产资源的放行风险等级。通过F1-score评价该模型的预测精度,该模型的F1-score值为87.9%,研究表明该模型预测结果满意,适用于大宗矿产资源的放行风险的预测。
关键词 大宗矿产资源;预测模型;LSTM;放行风险;检验监管。
Risk Prediction of Bulk Mineral Resources Release
Based on LSTM Neural Network
ZHANG Yan-Bin1 SU Yang1 XU Ya-Chun3 PENG Su-Biao1 XU Guo-Jiang2
LIU Yang-Li2 ZHONG Zhi-Guang1 XIAO Da-Hui1
Abstract The purpose of this paper is to accurately predict the release risk of bulk mineral resource.The customs clearance data of imported bulk mineral resources from 2016 to 2020 are used to establish an LSTM neural network time series model. The model is based on the TensorFlow framework. In the model, 22 characteristic values are selected. The release risk level of the bulk mineral resource is predicted with the model. The prediction accuracy of the model is assessed by using F1-score and F1-score value 87.9% is got. The research shows that the prediction results of the model are satisfactory, which is suitable for the prediction of release risk of bulk mineral resources.
Keywords bulk mineral resource; prediction model; LSTM; release risk; inspection and supervision
前言
随着国际经济形势的巨变,海关监管工作量在迅速增长。为了进一步提高通关便利化水平,海关总署改变传统监管模式,制定了部分大宗矿产资源“先放后检”的监管模式,实现港口货物快速验放。对于新监管模式,需要考虑以下问题[1]:一是对于重点商品的分析与监控,对主要涉税和涉证商品,影响关税征管、通关监管、海关统计等质量和执法水平的各种因素进行风险分析;二是对于重点企业进行深度守法状况评估与监控,建立守法评估的基础指标、对于企业守法状况进一步探索研究。
目前,国内外学者已经在报关单风险分析、审计风险识别、企业风险评估等领域进行了相关理论研究和业务实践,采用的方法包括:聚类分析、关联规则、主成分分析、logistic回归、决策树等。比如在报关单风险分析中,使用Q聚类模型对申报货物进行聚类,提炼出需要重点把控的申报货物[2];在审计风险识别中,使用关联规则对企业业务活动进行分析,甄别异常企业[3];在企业风险评估中,采用主成分分析精简企业通关风险相关指标[4]。但是放行风险评估需要综合考量多方面要素,并基于实际通关中现场查验、布控等不同环节中所产生的风险值、风险点的比重以及环节之间的复杂关系做出判断。上述经典方法能挖掘数据浅层关系,但在放行风险评估方面尚未达到很好的效果。并且随着国际贸易的迅猛发展,海关所面临的各种监管风险也大大增加,传统的机器学习方法失去了优势,已有研究应用LSTM的神经网络深度学习模型进行新的尝试,获得了更好的效果。
LSTM(Long-Short Term Memory)神经网络模型能协调历史记忆单元中的信息分配,有很强的时间序列学习能力和信息选择能力[5]。该模型主要针对具有时序特性的海量数据做预测判断,已在煤矿瓦斯预测,人体活动行为识别,城市道路短时交通状态预测,电气火灾预测等其他领域应用,能有效解决长序列训练过程中梯度消失与爆炸问题,并能保证较高的精度。海关报关历史记录同样是时序特征数据,其具有时间间隔长、关系复杂等特征,因此采用LSTM模型进行探索研究。
本研究着眼于大数据对海关矿产品类大宗矿产资源放行风险预警分析的探索。根据海关历史报关数据实际情况,借助数据分析技术筛选放行风险预测影响因素,通过企业历史申报的货物特征以及检验检疫结果对企业某次申报货物的放行风险预测,采用LSTM神经网络模型对新申报货物的放行风险进行预测,经过数据清洗、特征选取、建模与实例验证过程,对海关报关风险问题提供验证模型,为寻求有利于风险规避的有效方案提供参考。
1 数据清洗
本次以广州海关2016年至2020年进口法检矿产类大宗矿产资源报关报检数据为研究对象,综合考虑数据缺失、模型需求等情况,初步选择报检日期等作为输入变量,预测某报关企业某批报关货物是否检验合格,共5169条样本数据,25个特征。所有特征具体情况如下:
按表1“清洗方法”对数据进行清洗,分别处理成连续变量和分类变量。其中“检验时间间隔”等于“检毕日期”减“开检日期”。
“特殊检验检疫要求”与“现场情况描述”是字符型段落数据,从“特殊检验检疫要求”中匹配“滞期费未确定”和“价格未确定”目标字段,若存在目标字段则认为该货物检验检取值为1,否则取值为0。从“现场情况描述”中匹配“短重”“不合格”“低于实际申报”“标超”“退运”“夹杂”等目标字段,若存在目标字段则取值为1,否则取值为0。
另外,多分类变量(变量所含类别大于2)进一步处理为虚拟编码。假如变量含有k个类别,则设置k-1个取值0/1的哑变量,例如:入境口岸有36个,则设置35个哑变量 :

2 特征选取
2.1 相关性分析
通过相关性分析研究变量之间的关系,筛选强相关变量。一般而言,相关系数小于0,则变量之间呈现负相关关系,反之呈正相关关系。相关系数绝对值越大,变量相关性越强。由于本文所用数据字段缺失,数值缺失问题较严重,本文认定该特征相关系数绝对值0.2即为相关特征。
(1)研究连续变量与二分类变量:通过斯皮尔曼相关性系数和相关系数热力图知,货物重量、货物总值、索赔截止日期、特殊检验检疫要求、现场情况描述、检验时间间隔与放行风险指标(检验结果评定、检疫结果评定、集装箱检疫结果、货物评定、检验检疫结果代码)呈现负相关,而是否二次检验与放行风险指标呈现正相关关系。以上结论与实际情况相符,但由于数据缺失进行随机填充的手段降低了变量相关性。变量间或许存在交叉效应,需要更进一步的分析与挖掘。
(2)研究多分类变量:通过肯德尔相关性系数贸易国别、启运国家与放行风险指标相关性较小,施检部门代码与施检机构代码现实意义相似,经过相关系数矩阵发现这两个变量相关性十分强。于是剔除贸易国别、启运国家、施检部门代码特征,只选择其余变量作更进一步的研究。
2.2 特征关联性分析
通过特征关联分析研究变量的显著性和关联程度,使用方差分析、Kruskal-Wallis检验、logistic回归、图表分析等方法进行货物产地、矿种、施检时长与检验结果评定指标之间的关联性分析。由于检疫结果评定中不合格占比很小,故不考虑检疫结果评定指标。
2.2.1 货物产地分析
根据表2、表3方差分析和Kruskal-Wallis检验分析得出原产国对检验结果有显著影响。
为了更直观地展现原产国对检验结果的显著影响,绘制提琴图进行辅助描述:
如图2,以原产国编号分别为17与43为例。来自不同原产国的货物,检验结果合格率的分布存在很大差异。左边蓝色部分和右边黄色部分分别表示来自原产国17和原产国43的货物检验结果合格率分布情况。发现来自原产国17的货物,检验结果合格率分布较广,主要集中在较低值;来自原产国43的货物,检验结果合格率分布较为集中,主要聚集在较高值。且在方差分析中,P值很小,表示“原产国”对检验结果有显著影响。
使用logistic回归进行分析。若变量系数估计值为负数,则该原产国与检验结果呈负相关关系,即来自该原产国的货物检验不及格率较高。反之呈正相关关系,即来自该原产国的货物检验及格率较高,且显著性越高,结论可信度越高;系数绝对值越大,关联性越强。
原产国与检验结果的logistic回归中多个哑变量显著,即哑变量对检验结果影响明显。
其中Pr(>|z|)表示变量不显著的概率(落入拒绝域的概率),Pr(>|z|)越小,显著性越高;“*”表示变量显著性,“*”数量越多,显著性越高。
观察logistic回归分析结果,可以总结:a)原产国33、53与检验结果呈现负相关,检验及格率较低;b)原产国10、31与检验结果呈现正相关,检验及格率较高。经查验,分析与实际数据情况较为吻合。例如,原产国53货物检验记录中存在3条合格,8条不合格;原产国10货物检验记录中存在163条合格,25条不合格。
2.2.2 矿种分析
通过方差分析,Kruskal-Wallis检验发现矿种是影响检验结果的重要因素。logistic回归分析得出结果:a)铜矿、铅矿、锌矿与检验评定指标呈现正相关,系数都为正数,即铜矿的检验合格率较高;b)铬矿和锰矿与检验评定指标呈现负相关,系数都为负数,即铬矿和锰矿的检验合格率较低。经查验,实际数据与分析较为相符,比如铬矿的检验记录中存在21条不及格,1条及格,检验合格率较低。
2.2.3 施检时长分析
分析图3、图4发现,检验检疫合格的报关记录施检时间分布集中,多数聚集在0~5天检验检疫不合格的分布情况范围较为宽广,普遍分布在0~30天。得出与相关性分析相符的结论:施检时间越长,放行风险,检验不合格风险越大。施检时间超过5天的存在一定检验检疫风险。
本小节通过方差分析、Kruskal-Wallis检验、logistic回归、图表分析等方法,对货物产地、矿种、施检时长与检验结果评定指标之间的关联性进行分析,发现上述变量对货物检验结果具有显著分辨力。
2.3 特征选取结果
根据2.2小节分析结果,将剩余22个相关性较强的变量(表1中带星号的变量),输入放行风险评估模型,并进行更深入的研究探索。
3 建模与实例验证
3.1 构建LSTM神经网络
长短期记忆网络LSTM是循环神经网络RNN的一种。循环神经网络RNN对历史序列的信息记忆并应用于当前输出的计算中,即序列的输出与前一状态的输出相关。而长短期记忆网络LSTM有能力向单元状态中移除或添加信息,通过门结构来管理,包括遗忘门,输入门,输出门,其结构如图3所示。其中,X为输入,t为当前时刻,h为隐含层状态,当前信息g通过融合当前输入X和上一时刻隐藏层ht-1信息来计算。长短期记忆网络LSTM的算法公式如下:
ft=σ(Wfxxt+Wfhht-1+bf)
it=σ(Wixxt+Wihht-1+bi)
gt=φ(Wgxxt+Wghht-1+bg)
ot=σ(Woxxt+Wohht-1+bo)
st=gt ⊙ it+st-1 ⊙ ft
ht=φ(st) ⊙ ot
其中,ft表示遗忘门;it表示输入门;ot表示输出门;gt表示记忆单元;st为传给下一个LSTM block的输出结果;ht为传给下一层神经元的输出结果;σ表示激活函数sigmoid;φ表示激活函数tanh;Wx(包括Wfx、Wix、Wgx、Wox)为输入层的参数;Wh(包括Wfh、Wih、Wgh、Woh)为隐含层输入的参数;xt为输入层输入值;ht-1为上一时刻隐含层输入值;b(包括bf、bi、bg、bo)为常数。
本文所构造LSTM网络包含两层LSTM和一层全连接层Dense,两层LSTM的隐藏层神经元个数为64,全连接层Dense的神经元个数为1。其中图6展示了深度网络框架情况,而表5则详细介绍了网络的输入输出:
以下部分将介绍模型训练的细节。由于LSTM需要输入具有时间序列性质的数据,而实际数据形如“企业”-“报验时间”-“报验企业货物特征”,若对每个企业范围的数据按报验时间排序,并把一个企业的所有数据当作一个时间序列,将会产生如下问题:一是时间序列数据量不足;二是长短期记忆网络LSTM对于相对较长的序列(300项以上)记忆效果不足,而实际数据中存在较长的序列。
为了解决上述问题的,本文对数据做滑窗处理。对每个企业范围的数据进行固定次数t=3的滑窗,每个窗口序列伴随一个标签特征(取值0/1,表示是否检验检疫合格),该标签特征表示根据前2次报验情况与本次报验情况推断本次报验检验检疫及格的概率。滑窗处理后共有4525条数据,最终输入LSTM模型的数据维度为:(s,t,feature_num),s=4525,t=3,feature_num=21.
首先将数据集按训练集、测试集、验证集8:1:1的比例划分。即训练集、测试集、验证集的文本数分别为3627、449、449。
在模型的训练过程中,均采用交叉熵损失函数(Cross Entropy Loss Function):

其中y(i)表示第i个样本的真实样本标签,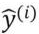 表示第i个样本的模型预测概率。损失函数越小,说明模型预测概率所对应的标签与真实标签越接近,说明模型拟合得越好。例如,假如样本真实标签y(i)为1,即为正样本;假设模型给出的预测该样本为正样本的概率为1,则损失函数L为0;假设模型给出的正样本的概率为0,则L的值为正无穷。因此我们的优化目标是使得L的值接近于0。
表示第i个样本的模型预测概率。损失函数越小,说明模型预测概率所对应的标签与真实标签越接近,说明模型拟合得越好。例如,假如样本真实标签y(i)为1,即为正样本;假设模型给出的预测该样本为正样本的概率为1,则损失函数L为0;假设模型给出的正样本的概率为0,则L的值为正无穷。因此我们的优化目标是使得L的值接近于0。
采用adam优化器进行迭代求解。另外,在模型迭代求解过程中,学习率衰退有助于模型收敛,模型细化,能有效提高模型精度。于是,本实验中采用阶层式的学习率衰退方法。设置学习率初始值是0.001,如果在5个epoch中验证集损失函数值减少,则学习率衰退为原来的十分之一。
3.2 模型评估
3.2.1 实验指标
选择合适的评价指标来判断模型分类效果,目前常用的评价指标有精确率(Precision)、召回率(Recall)、F1-score和准确率(Accuracy),上述评价指标的计算方法基于表6的混淆矩阵。
表6 混淆矩阵
Table 6 Confusion matrix
实际类别 | |||
正向 | 正向 | ||
预测类别 | 正向 | True Positive (TP) | False Positive (FP) |
负向 | False Negative (FN) | True Negative (TN) | |
精确率(Precision),预测为正的样本中,实际为正的样本所占的比例:
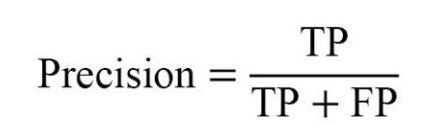
召回率(Recall),实际为正的样本中,被模型预测为正的样本所占的比例:

F1-score,精确率和召回率的调和平均值,由于精确率和召回率往往不能同时取得最大值,所以将这两个指标结合起来,作为对模型性能的综合评价指标。
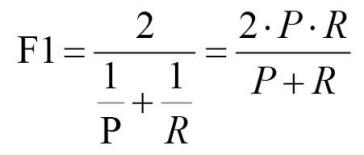
准确率(Accuracy)表示预测正确的比例:
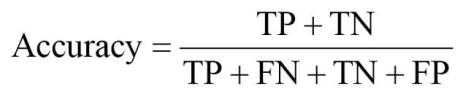
以上四个指标都是在0-1范围取值,取值越大,证明模型效果越好。
本实验所采用数据集实际上是一个不平衡数据集,负类与正类比值接近1:3,其中正类表示标签特征为负数,检验检疫结果不及格的样本,正类则相反。对于不平衡数据,模型往往倾向于牺牲小类样本的准确性来获取高准确率,而一个有效的模型应该尽量全面,同时兼顾小类样本和大类样本。因此一般使用F1-score来衡量模型在不平衡数据集上的效能。本实验主要采用F1-score来评估模型效果,并用precision,recall,Accuracy指标来辅助评价。
另外,受试者工作特征曲线 (receiver operating characteristic curve,简称ROC曲线),又称为感受性曲线(sensitivity curve)。分别以TP、FP为纵坐标和横坐标。ROC曲线描述分类器性能随着分类器阈值的变化而变化的过程,ROC曲线与横坐标包裹的面积在0-1范围取值,取值为0.5时候判定模型为随机分类,识别能力为0,取值越接近于1识别能力越强,取值等于1为完全识别。
3.2.2 实验结果
LSTM模型训练过程中的准确率和损失函数值随着模型训练epoch数的变化曲线见图7。可以发现训练集的准确率与损失函数值,在20个 epoch内较大幅度的效果提升,在20个epoch后,出现震荡,模型学习接近极限水平。训练集准确率与损失函数值最终围绕0.750和0.475上下震荡。验证集的准确率与损失函数值,分别在10个和20个epoch内较大幅度的效果提升,最终围绕0.875和0.325上下震荡。可见模型验证集效果比测试集好。
图8显示ROC曲线面积为0.8,远大于0.5,接近于1,表示分类效果显著。
表7展示不同经典机器学习模型BP神经网络、SVM、Logistic回归与双层LSTM(主模型)在测试集的实验结果对比情况。LSTM模型测试集的4个指标均达到不错的表现,几乎都是表现最优秀的,F1-score值在所有比较算法中达到最高。其余算法都是recall值比较高,而precision值较低。recall(召回率)含义为实际为正且预测为正的样本(TP)在实际为正的样本(TP+FN)中所占的比例,正类数量较大的不平衡数据集中recall值通常很大。Precision(精确率)表示实际为正且预测为正的样本(TP)在预测为正的样本(TP+FP)中所占的比例,BP神经网络,SVM和Logistic回归的Precision普遍较低,说明这些算法都比较“偏袒”大类样本(正类样本),容易把小类样本(负类样本)误判。由于F1-score是对于recall和Precision的综合考虑,因此其余算法的F1-score值都低于LSTM,而且说明LSTM模型在不平衡数据集具有良好的效能,即比较适合应用于具有正负类数量不平衡性质的海关放行数据。
另外,本文还构造了单层LSTM加单层全连接层Dense(LSTM隐藏层神经元个数为64,全连接层神经元个数为1)网络作为对照组,与双层LSTM(主模型)进行比较。发现单层LSTM各个指标都劣于双层LSTM。因此认为选择2层LSTM的网络构造是比较合适的方案,能达到一定的效能提升。
3.3 实例验证
使用本文构造的LSTM模型对所有数据进行验证。其中全部数据的F1-score为87.1%,recall为95.4%,precision为80.1%,准确率为78.4%。其中抽出一条样本数据进行详细说明,样本数据情况见表8:
根据表8可知,该货物价格重量较小,检验时间间隔较短,没有被要求索赔,且特殊检验检疫要求与现场情况描述变量中不含有敏感目标字段。另外该货物原产国编号为67,矿种为“锌矿”,上述原产国,矿种的检验检疫及格率都比较高。根据LSTM模型溯源该企业历史记录,分析各个变量间的内联关系,判断得出类似结果,认为该货物放行风险小,放行安全指数高达92.92分(总分为100,超过50分则认定为放行风险小)。同时实际上该批货物检验检疫结果也是合格的(见图9检验检疫结果代码变量取值,其中0表示不及格,1表示及格)。

图9 验证结果截图
Fig.9 Validation results
因此模型预测与实际的检验检疫情况相符。
4 结论
本文以广州海关大宗资源中的矿产品通关数据为典型研究对象,以获取的历史数据为基础,经过数据清洗、特征选取,建立了LSTM神经网络时间序列等模型。研究发现,矿产品通关数据质量和数量影响预测精准度和模型选取,如通过业务数据规范提高数据质量、获取全国矿产品通关数据以增加数据量,可改善研究结果。
通过模型评估和实例验证,建立的LSTM神经网络时间序列模型具有良好的收敛效率和预测精度,可以准确预测放行风险。该模型应用于放行风险的辅助判别中,有助于通过对历史数据与新数据的综合分析,得出客观的放行风险评价。
未来可扩展该模型的应用范围并持续优化,结合其他的深度学习模型的发展,对大宗矿产资源放行风险预测进行深入探索研究。
【该文经CNKI学术不端文献检测系统检测,总文字复制比为1.1 %。】
海关总署信息化应用创新实验室课题
第一作者:张彦彬(1975-),男,高级工程师,E-mail:zhangyanbin@customs.gov.cn
1.广州海关技术中心 广州 510623 2.广东智源信息技术有限公司 广州 510091 3.中国电子口岸数据中心广州分中心 广州 510360
1. Guangzhou Customs Technology Center, Guangzhou 510623 2. Guangdong Intelsource Information Technology Co. Ltd. , Guangzhou 510091
3. China E-Port Data Center, Guangzhou Branch, Guangzhou 510360
表1 特征字段及清洗方法
Table 1 Feature fields and Cleaning methods
筛选特征字段中文 | 筛选特征字段英文 | 清洗方法 |
报检日期* | DECL_DATE | 2016年12月到2020年3月,处理成连续变量 |
收货人名称* | CONSIGNEE_CNAME | 字符型,263家,处理成多分类变量 |
启运口岸代码* | DESP_PORT_CODE | 字符型,144个,处理成多分类变量 |
申报货物名称* | DECL_GOODS_CNAME | 字符型,152个,处理成多分类变量 |
启运国家 | DESP_CTRY_CODE | 字符型,64个,处理成多分类变量 |
经停口岸* | PORT_STOP_CODE | 字符型,81个,处理成多分类变量 |
入境口岸* | ENTY_PORT_CODE | 字符型,36个,处理成多分类变量 |
贸易国别 | TRADE_COUNTRY_CODE | 字符型,55个,处理成多分类变量 |
货物总值* | TOTAL_VAL_US | 数值型,处理成连续变量 |
重量* | WEIGHT | 数值型,处理成连续变量 |
原产国* | ORI_CTRY_CODE | 字符型,60个,处理成多分类变量 |
开检日期* | INS_BEGIN_DATE | 字符型,处理成连续变量 |
检毕日期* | INSP_END_DATE | 字符型,处理成连续变量 |
施检机构代码* | EXE_INSP_ORG_CODE | 字符型,处理成多分类变量 |
施检部门代码 | EXC_INSP_DEPT_CODE | 字符型,处理成多分类变量 |
检验结果评定* | INSP_RES_EVAL | 数值型,处理成二分类变量,取值0/1 |
检疫结果评定* | QUAR_RES_EVAL | 数值型,处理成二分类变量,取值0/1 |
集装箱检疫结果* | CONT_QUAR_RESULT | 数值型,处理成二分类变量,取值0/1 |
货物评定* | GOODS_EVAL_RESULT | 数值型,处理成二分类变量,取值0/1 |
检验检疫结果代码* | CIQ_RESULT_CODE | 标签特征(Y) |
索赔截止日期* | COUNTER_CLAIM | 字符型,处理成二分类变量,取值0/1 |
是否二次检验* | WHETHER2ND_INS | 数值型,处理成二分类变量,取值0/1 |
特殊检验检疫要求* | SPECL_INSP_QURA_RE | 字符型段落,处理成二分类变量,取值0/1 |
现场情况描述* | SPOT_DESC | 字符型段落,处理成二分类变量,取值0/1 |
检验时间间隔* | / | 从开检日期,检毕日期中产生 |
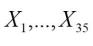
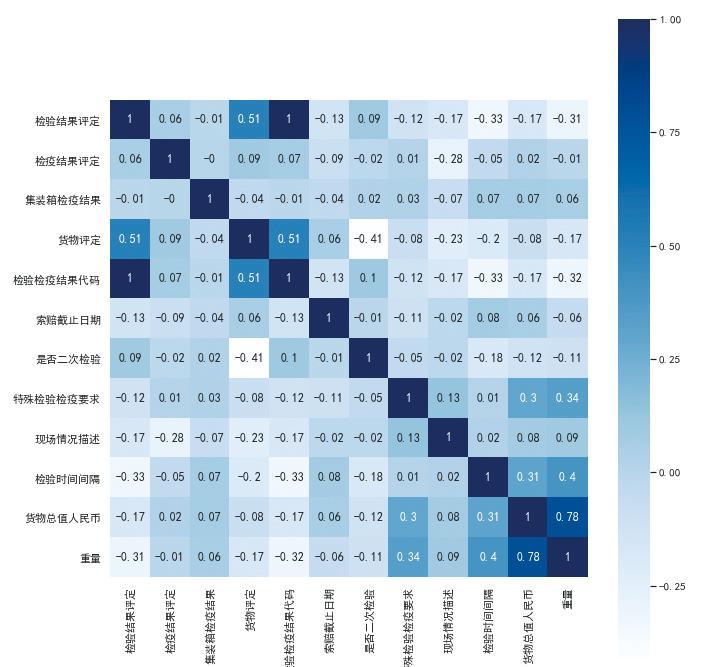
图1 相关系数热力图
Fig.1 Heat map of correlation coefficient
表2 原产国(58个)方差分析结果
Table 2 ANOVA result of country of origin
自由度 | 平方和 | 均方 | F比 | P值 | |
C(原产国) | 57.0 | 24.396229 | 0.428004 | 6.593976 | 2.990861e-32 |
误差 | 429.0 | 27.845679 | 0.064908 |
表3 原产国(58个)Kruskal-Wallis检验结果
Table 3 Kruskal-Wallis test results of country of origin
P-value | P.adj | P.format | P.signif | Method | |
检验结果评定 | 3.142988e-26 | 3.1e-24 | <2e-16 | **** | Kruskal-Wallis |
注:P-value为检验否定原假设的概率,P.adj为调整统计量的P-value,P.format表示四舍五入的P-value水平,P.signif为显著性程度,其中‘****’:0.0001,‘***’:0.001,‘**: 0.01,‘*’:0.05, ‘.’:0.1 ,‘ ’:不显著。 Method是检验方法。
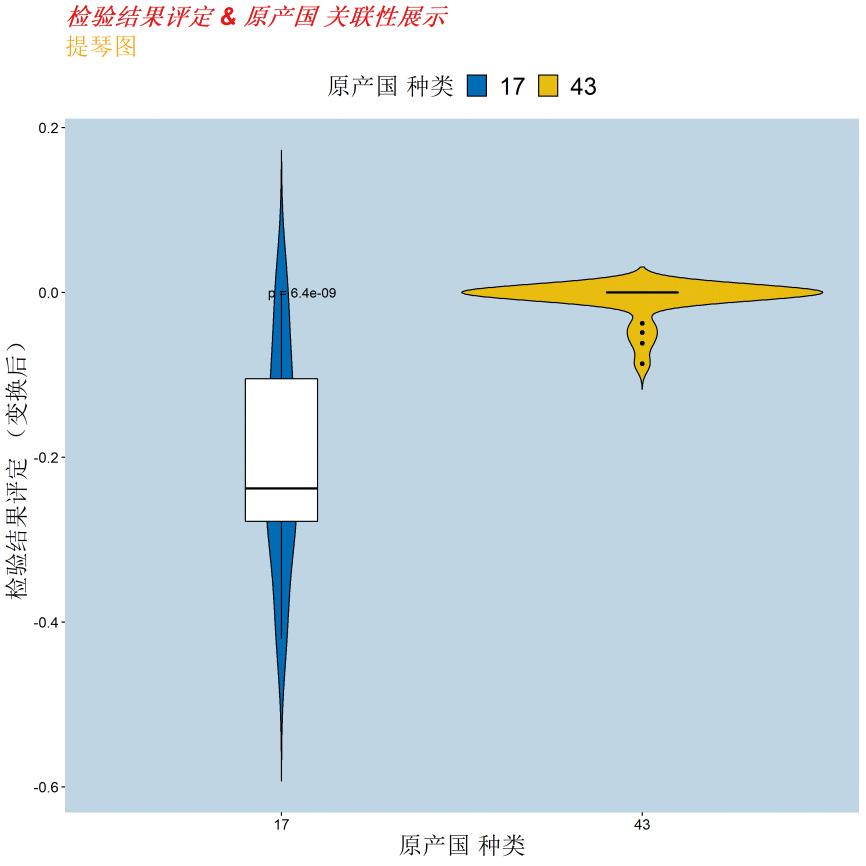
图2 原产国与检验结果的提琴图
Fig.2 Violin diagram of country of origin and inspection results
表4 原产国logistic检验结果的显著性
Table 4 Significance of logistic test results in country of origin
原产国 | Estimate | Std. Error | z value | Pr(>|z|) | 显著性 |
10 | 1.1035 | 0.4098 | 2.6930 | 0.0071 | ** |
31 | 2.5332 | 0.7901 | 3.2060 | 0.0013 | ** |
33 | -0.8714 | 0.3506 | -2.4860 | 0.0129 | * |
53 | -1.8816 | 0.7527 | -2.5000 | 0.0124 | * |
图3 检验检疫不合格的施检时间间隔柱状图
Fig.3 Histogram of inspection time interval for unqualified inspection and quarantine

图4 检验检疫合格的施检时间间隔柱状图
Fig.4 Histogram of inspection time intervals for qualified inspection and quarantine
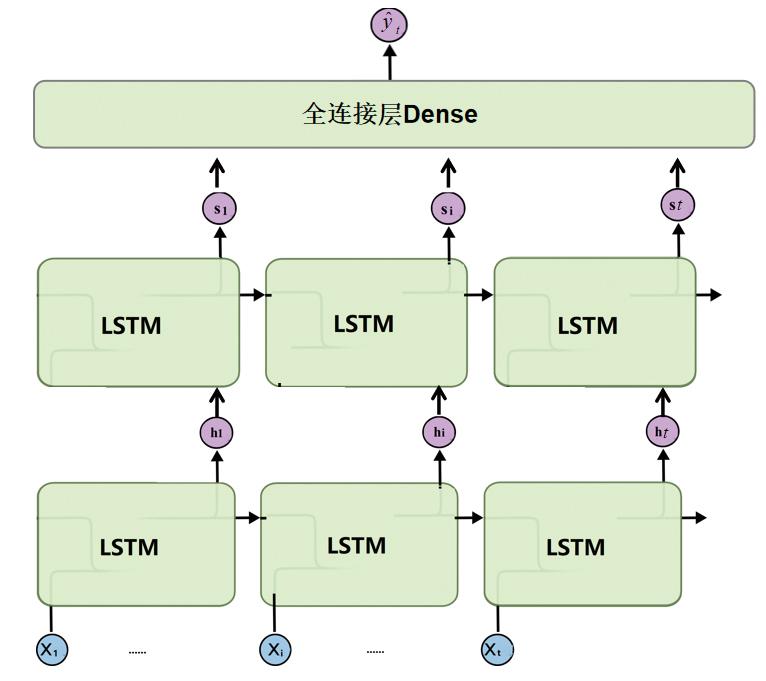
图5 模型算法框架图
Fig.5 Model algorithm framework
表5 网络结构
Table 5 Network structure
网络层 | 描述 |
LSTM_1 | 即输出 |
LSTM_2 | 即输出 |
全连接层 | 即输出 |

图6 滑窗详细处理方法
Fig.6 Sliding window detailed processing method
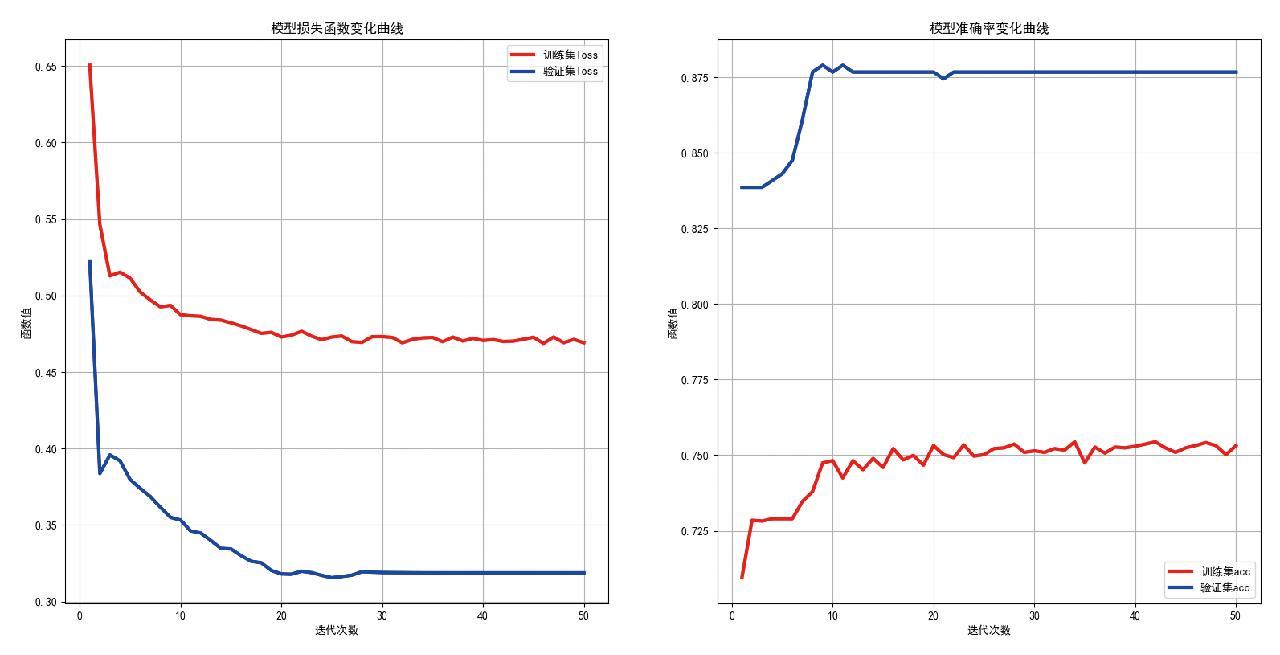
图7 LSTM模型准确率变化曲线
Fig.7 Accuracy curve of the LSTM model

图8 ROC曲线
Fig.8 ROC curve
表7 各个模型测试集准确率对比
Table 7 Comparison of the accuracy of each model test set
model | F1-score | precision | recall | Accuracy |
LSTM(2 layers) | 87.9% | 81.5% | 95.5% | 79.9% |
LSTM(1 layer) | 83.9% | 78.8% | 89.6% | 75.0% |
BP(5-2) | 85.1% | 74.1% | 98.0% | 73.0% |
SVM | 85.3% | 76.8% | 96.0% | 74.2% |
LogisticRegression | 85.2% | 79.0% | 92.5% | 76.5% |
表8 验证数据
Table 8 Verify the data
特征值 | 特征字段 | 特征值 | 特征字段 |
报检号 | ******* | 集装箱检疫结果 | 1 |
货物序号 | 1 | 检验结果评定 | 1 |
报检日期 | 2020-022-12 14:46:05 | 检疫结果评定 | 1 |
申报货物名称 | 锌矿砂(锌精矿) | 货物评定 | 1 |
重量/t | 3 | 施检机构代码 | 36 |
原产国代码 | 67 | 是否二次检验 | 0 |
启运口岸代码 | 20 | 现场情况描述 | 查验未见异常 |
经停口岸代码 | 37 | 特殊检验检疫要求 | 快件 应检商品 |
入境口岸代码 | 12 | 开检日期 | 2020-02-12 |
索赔截止日期 | 无 | 检毕日期 | 2020-02-12 |
收货人名称 | *** | 检验检疫结果代码 | 1 |
货物总值/RMB | 10432127 |
参考文献
[1]陈雄杰. 我国海关风险式通关作业流程研究[D].复旦大学,2009.
[2] Li Y , Sun L . Study and applications of data mining to the structure risk analysis of customs declaration cargo[C]// IEEE International Conference on E-business Engineering. 0.
[3]李胜.基于关联规则的审计特征智能提取的应用研究[D].北京交通大学.2006.
[4]王洪伟,吴家春,蒋馥. 基于粗糙集与主成分分析的属性约简的启发式算法研究[J].管理工程学报,2004.18,(3):87~90.
[5] Sundermeyer, Martin Schlüter, Ralf Ney, Hermann. (2012). LSTM Neural Networks for Language Modeling.
[6]水英豪. 海关便捷通关管理模式研究[D].湖南师范大学,2015.
[7]张紫玄,王昊,朱立平,邓三鸿.中国海关HS编码风险的识别研究[J].数据分析与知识发现,2019,3(01):72-84.
[8]卢金秋. 数据挖掘中的人工神经网络算法及应用研究[D].浙江工业大学,2006.
[9]赵月爱, 秦佳宁. 基于TensorFlow的LSTM神经网络智能电气火灾预测研究[J]. 太原师范学院学报:自然科学版, 2019,18(02):44-48.
[10]赵又霖, 张慧敏. 基于特征工程的网络广告收益转化精准度研究[J]. 武汉理工大学学报(信息与管理工程版), 2018, 040(006):667-673.
(文章类别:CPST-C)
