





CopyRight 2009-2020 © All Rights Reserved.版权所有: 中国海关未经授权禁止复制或建立镜像

大数据流计算特点及“单一窗口”适用场景探讨
作者:孙学忠1 胡 伟1*
孙学忠1 胡 伟1*
摘 要 大数据已经成为技术创新和应用的热点。大数据流计算是当前大数据分析技术的主要技术之一。准确理解和把握流计算概念及特征,对于企业做大数据流计算技术选型具有一定的现实意义。要准确理解流计算,需从数据流、处理模式及场景三个维度来把握。流处理模式和批处理、事务处理存在一些差异。本文结合“单一窗口”典型的业务场景,对流计算的适用场景进行分析,最后对流计算产品选型给出建议。
关键词 大数据;流计算;批处理;有向无环图;单一窗口
Probe into Characteristics of Big Data Stream Computing and Applicable Scenarios of "Single Window"
SUN Xue-Zhong1 HU Wei1*
Abstract Big data has become a hot spot of technology innovation and application. Big data stream computing is one of the main technologies of big data analysis. It is of practical significance for enterprises to understand the concept and characteristics of stream computing. To understand stream computing accurately, we need to grasp it from three dimensions: data flow, processing mode and scenario. There are some differences between flow processing mode and batch processing and transaction processing. Combined with the typical business scenarios of Single Window, this paper analyzes the applicable scenarios of stream computing, and finally gives suggestions for the selection of stream computing products.
Keywords big data; stream computing; batch computing; directed acyclic graph(DAG); single window
前言
2015年8月国务院发布《促进大数据发展行动纲要》[1],标志着我国已将大数据视为战略资源并上升为国家战略,各行各业以大数据应用创新为切入点构建新一代信息化系统。当前,各地方正在兴起的“智慧城市”“ 智慧交通”等项目,其共同点都是围绕大数据处理与分析开展的应用探索,其中一些项目已经取得了一定的社会和经济效益[2-5]。
大数据技术是从大量的、不同类型的数据中快速获得有价值信息的技术。更快更完整地获取数据,更快更充分地挖掘出数据价值,已经成为大数据时代各行各业的共识[6]。大数据流处理技术因为能够对数据进行实时处理、分析和反馈,已成为当前大数据分析技术的热点之一 ,业内主流的流计算引擎包括Storm、Millwheel、Samza和 Flink等。
在日常开展“单一窗口”大数据平台相关建设工作时,由于部分技术人员对流计算概念及特点了解不够全面和准确,对流计算引擎适用场景缺乏认识,在整体规划设计中无法准确评估流计算产品的适用性、可靠性和兼容性。因此,准确理解和把握流计算概念及特征,对于做好大数据流计算技术选型具有一定的指导意义。
本文从不同维度对流计算概念进行介绍,对其应用特点进行说明,并对典型的业务场景进行适用性分析,为大数据平台建设中流计算产品的技术选型提供参考建议。
1 流计算简述
1.1 概念
流计算指按照时间顺序无限增加的数据序列,时刻都有新的数据加入,数据一边流入,一边被计算[6-8]。概念本身含有三个要素:数据流、处理模式及应用场景,即对于连续不断、无限增加的数据(数据流),采用实时计算处理技术(处理模式),实现对数据的实时分析及结果展现(场景),其概念如图1所示。
图1 流计算概念图示
Fig. 1 Diagram of stream computing concept
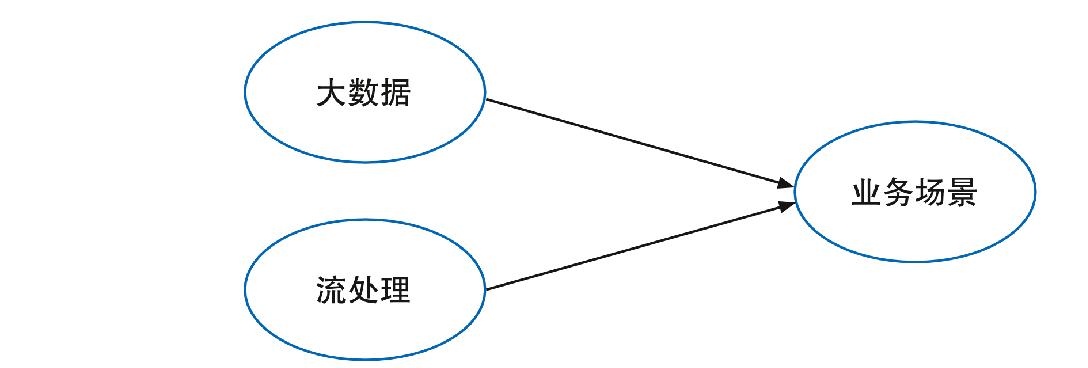
其中,数据是前提和基础,处理技术是手段,业务场景是目标。因此,要准确理解流计算,需要把握这三个维度的内涵和特点。
1.2 数据流的特征
数据流是流计算的前提和基础,依照当前的研究情况,流计算中的数据具有如下特征[7]:
(1)无限性:流式数据可以抽象为一个无穷的数据序列,只要数据源处于活动状态,数据就会一直产生并持续增加下去,潜在的数据量是无限的。
(2)无序性:流式数据可以来源于不同的系统,各来源数据到达流计算平台的时间是随机的,具有不同的时间序列,流计算系统本身无法控制。
(3)实时性:流式数据的价值随着时间的流逝而降低,需结合业务场景对数据的处理结果做实时更新,确保数据能反馈最新的信息,提供最大的价值。
(4)突发性:流式数据的产生依赖于数据源和网路传输,由于不同数据源各自的状态不同,数据产生速度和质量各异,同时网络延迟也会对数据的到达顺序产生影响,这些因素使得流式数据具有突发性。
1.3 流处理模式的特征
在信息技术中,“计算”是数据的存、取、传输、运算等所有需要计算机处理的功能集合。计算模式是数据处理过程的抽象,通常由三部分组成:计算任务的描述方法、计算任务的执行机构以及计算任务在执行机构上的运行方法[9]。流处理属于数据流处理模式[9-10]。
流计算处理模式如图2所示。
图2 流计算处理模式图
Fig. 2 Diagram of streaming process pattern
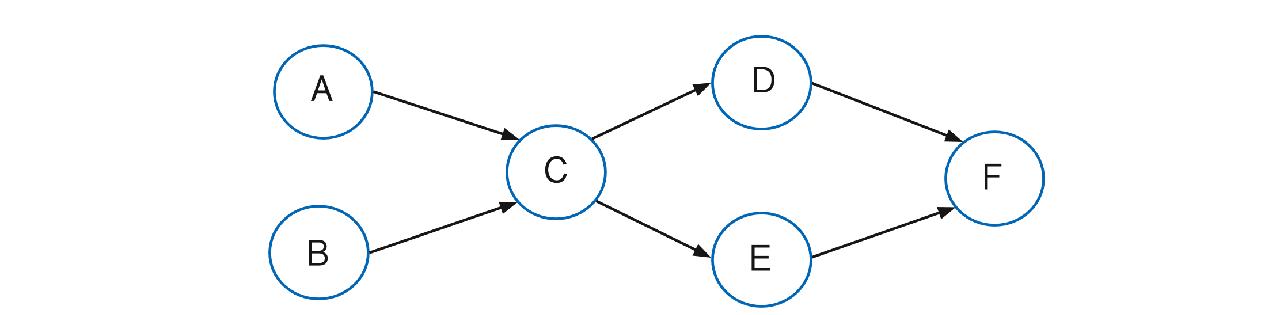
流计算模式的本质是一个DAG(有向无环图),图中 A~B代表数据处理节点,黑色箭头代表数据的流向,节点间通过消息队列传递数据。“无环”是指处理节点不会再去处理已经处理过的数据。
结合图2进行分析,流计算模式具有以下特征:
(1)数据处理是单向、无环的。数据单方向流入系统,系统对数据的处理也是单向的,即已经被处理过的数据不会被送回之前的处理环节再做处理。“旧”数据如果因为业务场景而需要重新进入系统再做处理时,会带上新的时间戳,作为“新”数据进入系统,而不是从历史数据中找出该数据再做处理。
(2)数据处理通常是并发的。数据进入流处理系统后会保存在消息队列中,通常会有多个处理节点同时对数据进行计算,以提升数据处理的效率。
(3)数据处理是异步的。由于数据进入系统的次序不可预测,流处理系统采用消息队列等机制缓冲数据,避免因数据未及时处理导致系统阻塞的情况。
以上特征中,单向、无环是流处理最重要、最容易与其他数据处理模式相区别的特征。
1.4 业务场景
通过对流计算特征分析可知,流计算适用于数据量大、实时性高的数据分析场景。结合图2 可以看出,流计算在业务层面是单向、非闭环的,即业务场景中不会存在对于历史数据的修改、更新和删除等操作。
2 流计算模式与其他处理模式的比较
“单一窗口”当前业务主要是事务处理类应用和部分大数据分析类业务。事务处理主要是解决传统的交易性应用场景,其产品主要是关系型数据库,如Oracle、MySQL等。大数据分析类业务,业内主流的大数据分析技术是流处理和批处理,典型的产品如Hadoop、Spark等[11]。
为方便后续场景分析,以下对流计算与批处理、事务处理的差异做一些比较。
2.1 流式计算和批量计算
(1)批量计算处理的是静态的、持久的、大量的数据,批处理的数据通常是已保存在计算机磁盘上,数据全集参与计算,数据不会再有修改和增减。流计算处理的是动态的、变化的数据,待处理的数据通常在内存中且时刻发生变化。每一次参与计算的是新增的数据,而不是全量数据。
(2)批处理计算任务采取调度批量任务来执行,数据在任务启动前需要先加载到内存或缓存中;流处理的数据是无序无限流入的,到达时间和顺序无法预先掌握,计算任务采取实时并发执行。
(3)批量处理计算的数据量通常很大,时间响应通常为分钟或者小时级别。流式计算数据处理采取数据“即来即算”的模式,响应速度通常为毫秒级别。
2.2 流式计算和事务处理
(1)事务处理对于数据的处理遵循ACID原则,数据的一致性是强制一致性,数据的准确性很高。流处理或者批处理系统对于数据的处理遵循BASE原则,数据的一致性是弱一致性,其准确性相对较弱。
(2)事务处理系统响应时间通常是毫秒级甚至更高,流计算系统的响应速度相比事务系统较低。
(3)事务处理系统通常对数据进行修改、删除等操作。流式计算采用有向无环的处理模式,不会存在对历史数据的修改及删除等操作。
3 典型应用场景探讨
以下结合流计算特征,对“单一窗口”应用中的一些典型场景作适用性分析。
3.1 典型场景分析
(1)场景一:国际贸易“单一窗口”金融服务中,基于某企业过去3年的进出口贸易数据,评估企业的经营情况和融资额度。
分析:“过去3年的数据”表明数是非实时更新的,是静态的。不符合1.2流数据的特征,判定为典型的批处理场景。
(2)场景二:企业使用国际贸易“单一窗口”跨境电子商务进出口系统开展业务,系统时刻都有数据更新,且数据体量很大。
分析:依照1.2 流数据的特征来判定,跨境电商的数据符合流数据的特征。跨境电商系统是一个在线交易系统,对于某票历史交易,存在修改和删除的处理,这些处理要求基于原始的记录(如订单、清单等数据)进行操作,这与1.3流处理特征第(1)条不符。判定跨境电商系统不是流处理系统,它属于事务处理系统。
(3)场景三:“单一窗口”各类业务系统的日志实时分析,以获取服务器运行状况,分析服务器健康状况并告警。
分析:依照1.2 流数据特征判定,日志数据符合流数据特征。所有新的日志数据都被实时处理,且不存在数据的闭环处理(即不存在对某条历史日志的修改及操作),处理采取并行和异步方式,其处理过程符合1.3 流处理的特征,因此判定为典型的流计算场景。
(4)场景四:“单一窗口”平台汇集的水、路、空、铁等各类口岸业务数据,以及各类物流相关数据,如车辆轨迹信息、GIS等,通过数据分析为用户提供全方位单证状态查询及全程物流实时跟踪等服务。
分析:参照1.2流数据特征判定,各类业务数据及物流数据是持续产生的,符合流数据特征。其次,为满足实时状态查询与物流跟踪的业务需求,应对各类数据进行实时处理。有些数据存在修改的可能,比如舱单的申报数据,在处理上存在闭环,不符合1.3流处理特征;对于车辆轨迹等实时物流信息,则不存在数据修改的问题,在处理上不存在闭环,符合1.3流处理特征。在这种场景下,单独的数据处理模式无法满足应用需求,需要将批处理和流计算结合起来,协同配合以满足业务场景需求。
3.2 不同数据流和处理模式配合的问题
每一种数据处理模式都有其擅长处理的应用场景,如果场景和处理模式不匹配,其实现效果通常不够理想,问题会比较突出。
(1)交易数据 VS 流处理。对于场景二,如果采用流计算技术来构建,系统功能也可以实现,但系统性能会存在较大隐患。流计算强调对数据进行实时计算,并对计算结果做实时输出和展示。在流计算模式中,已经处理过的数据如果没有特别的需要,通常是不保存的,原因有两点:一是分析过的数据,其价值已经降低; 二是流式数据趋向于无穷无尽,存储这些数据需要大量的存储设备。场景二中的交易数据都需要保存下来,数据量本身非常庞大,同时由于流计算系统中数据通常是以文件格式存储,在海量文件数据集中找到某一条记录做更新或删除操作,效率必然低下。因此,对于类似跨境电子商务、在线商城、单据申报这类交易量频繁且数据量大的系统,采用数据流计算模式不是最优的选择,需选用分布式或传统的关系数据库来实现。
(2)流数据 VS 批处理。对于场景三,从2.1的比较可知,批处理框架无法处理流数据,这也正是流计算框架产生的主要原因之一。
(3)批量数据 VS 流计算。流计算模式对于批量数据在资源充分的情况下是可以处理的。当前主流的流计算框架Flink同时支持批处理和流计算[12]。因此,对于场景四,采用Flink作为大数据处理框架是一个可行的选择。
4 关于流计算平台选型建议
信息化系统建设通常有固定的预算规模和实施周期等限制因素,在规划设计时需要通过技术选型来确定实现方案。准确把握流计算的概念及应用场景,可以帮助我们合理选择流计算产品。
结合前面介绍内容在技术选型方面建议如下:
(1)根据自身业务的数据特征,判定其是否为流数据。如果不符合流数据特征,原则上避免选用流计算产品。
(2)业务数据符合流数据特征的需要结合业务场景进行判定。如果业务场景中存在对某条或某批次的历史数据执行修改或者删除操作,在业务处理层面会形成闭环,不符合流处理特征,可以判定为不适用流计算场景。如果不存在数据上的闭环处理,可以初步判定其符合流计算场景。
(3)在数据和场景都符合流计算特征的情况下,基于不同产品会有不同的技术方案。未来流处理和批处理会趋于融合和集成, 比如当前主流的流计算产品Flink和Storm,都能够同时进行批处理和流计算[12],规划中需要结合业务发展实际情况,选择与自身技术规划相一致的产品。
5 结语
大数据已经成为技术与应用创新的热点,是新一代信息化建设的核心。流计算作为当前大数据分析关键技术之一,有其自身的特点和应用场景。准确把握流计算技术的特点及其适用场景,充分分析自身业务应用特征,做好技术选型与业务需求的相对匹配,是建设大数据应用平台的基础与关键。
【该文经CNKI学术不端文献检测系统检测,总文字复制比为2.6%。】
通讯作者:胡伟(1973- ),汉族,大学本科,福建人,技术管理部主任,主要从事大数据架构规划、架构管控、技术管理等工作,E-mail:Huwei@chinaport.gov.cn
1.中国电子口岸数据中心 北京 100088
1. China E-Port data centre, Beijing 100088
参考文献
[1]中华人民共和国国务院.促进大数据发展行动纲要[J].成组技术与生产现代化, 2015, 32(3): 51-58.
[2]李喆,王平莎,张春晖,等.国内智慧交通总体架构建设模式分析[J].交通节能与环保, 2014, 12: 85-88.
[3]王雅琼,杨云鹏,樊重俊.智慧交通中的大数据应用研究[J].物流工程与管理, 2015, 37(5): 107-108.
[4]李德仁,姚远,邵振锋.智慧城市中的大数据.武汉大学学报 信息科学版[J], 2014, 39(6): 631-640.
[5]陈昊,解宇星.福建省石狮市智慧城市管理案例研究[J].电子技术与软件工程, 2019, 23: 199-200.
[6]李圣,黄永忠,陈海勇.大数据流式计算系统研究综述[J].信息工程大学学报, 2016, 17(1): 88-92.
[7]孙大为,张广艳,郑纬民.大数据流式计算:关键技术及系统实例[J].软件学报, 2014, 25(4): 839-862.
[8]祝锡永,庞培培.大数据流式计算系统综述[J].成组技术与生产现代化, 2016, 33(4): 49-54.
[9]袁旭初,付国毕继泽,等.分布式数据流计算系统的数据缓存技术综述 [EB/OL].
http://kns.cnki.net/kcms/detail/10.1321.G2.20200227.1842.004.html, 2020-02-28.
[10]毕倪飞,丁光耀,陈启航,等.数据流计算模型及其在大数据处理中的应用[EB/OL].
http://kns.cnki.net/kcms/detail/10.1321.G2.20200222.1147.008.html, 2020-2-23.
[11]代明竹,高嵩峰.基于Hadoop、Spark及Flink大规模数据分析的性能评价[J].中国电子研究院学报.2018, 13(2): 149-155.
[12]谭勇.Spark和Flink的计算模型对比研究[J]. 计算机产品与流通. 2019.04: 152-153.
(文章类别:CPST-A)
