CopyRight 2009-2020 © All Rights Reserved.版权所有: 中国海关未经授权禁止复制或建立镜像

基于X射线衍射特征提取的铜精矿原产地识别方法
作者:闵红 刘倩 王巧玲 周海明 刘曙 邢彦军
闵红 刘倩 王巧玲 周海明 刘曙 邢彦军
Abstract Copper concentrates from different sources exhibit variations in their phase composition and elemental content. Developing a method for identifying the origin of imported copper concentrates provides a means for origin verification-based risk control strategies, aiding in the screening of copper concentrate quality and expeditious release by the customs. This study establishes an approach for origin identification of copper concentrates based on X-ray diffraction (XRD) characteristics. In XRD spectrum classification modeling, data redundancy and collinearity will significantly affect the classification performance and robustness of the model. Thus, data dimensionality reduction and feature extraction become effective techniques to improve the accuracy of classification modeling. This research collects XRD spectra of 138 batches of copper concentrates originating from three major source countries and compares principal component analysis (PCA) and random forest feature importance methods for extracting feature data from XRD spectra, ultimately constructing a random forest classification model. The results indicate that the random forest classification model built using the top 34 feature-importance-ranked variables achieves an accuracy of 94.28%. Compared with the principal component load threshold, this approach not only reduces the number of input feature variables effectively but also delivers a superior classification performance. XRD analysis technology has the advantages of fast analysis speed and good stability. By combining random forest feature extraction and classification algorithms, this approach facilitates the identification of the origin of copper concentrates.
Keywords copper concentrates; X-ray diffraction spectrum; feature extraction; random forest; origin identification
我国电力、空间制冷、电子、建筑等行业的快速发展,对铜原料的需求不断增长,近年来我国成为世界上最主要的铜消费国之一。由于自有铜矿资源的限制,我国需要大量进口铜精矿以满足应用需求[1],国际铜研究小组(International Copper Study Group,ICSG)统计数据表明,2022年中国铜精矿进口量居世界首位[2]。进口铜精矿来源广、质量差异大,放射性超标、有害元素超标、以废充矿等问题一旦发生,将对生态环境、人民健康产生巨大危害,因此,进口铜精矿质量安全风险一直是我国检验监管部门的重点监管内容。为了缩短通关时长、促进贸易便利化,近年来我国不断优化进口矿产品的检验监管模式,但对铜精矿仍保留有毒有害元素批批检测的监管要求。开发铜精矿风险监控的技术手段,建立风险可控的铜精矿快速验放策略,有利于助力智慧海关建设、提升海关履行把关服务能力。
矿产品作为地质性产品,在特定的环境条件下形成的矿产品具有区域性的地质特征,其物相结构、放射性、有毒有害元素含量因产地不同而不同,铜精矿质量风险因子与原产地之间存在一定关联。通过开展铜精矿原产地验证,能够快速筛查进口铜精矿风险,为铜精矿风险控制下的快速验放提供技术支撑。利用光谱图谱的指纹特征结合化学计量学被证明是产地溯源可行的技术手段[3-5]。X射线衍射光谱能够给出样品的物相结构信息且样品前处理过程简单,在海关实验室中应用广泛,但传统的物相结构解析需要借助专业的软件和实验人员的经验。随机森林分类方法是一种简单且易于实现的机器学习算法,与传统的分类算法相比具有抗噪性能良好和分类精度高的优点[6-7]。此外,随机森林对于变量显著性评估的能力可以应用于消除光谱数据的冗余及共线性对模型分类性能和稳健性的影响[8]。Sheng等[9]采用激光诱导击穿光谱与随机森林相结合的方法,对10个不同品级的铁矿进行鉴定与分类,随机森林分类的平均预测准确率为100%。Tang等[10]采集了3种不同类型矿渣(平炉渣、转炉渣和高钛渣)样品的激光诱导击穿光谱,光谱预处理后采用随机森林特征重要性的方法提取光谱的重要变量,通过利用输入变量的重要性提高了样品分类模型的性能。
本文采集了来自智利、秘鲁、墨西哥3个国家138批进口铜精矿代表性样品,使用X射线衍射仪采集铜精矿X射线衍射谱图数据,通过主成分分析和随机森林提取原始谱图数据的特征数据,利用特征数据进行随机森林建模分类,进一步比较不同特征提取方法建立的分类模型对铜精矿原产地识别的准确性。
1 实验部分
1.1 样品收集
根据GB/T 14263—2010《散装浮选铜精矿取样、制样方法》,在进口铜精矿卸货过程中采集代表性样品,制备粒度不大于100 μm化学分析样。样品主要来自智利、秘鲁和墨西哥3个国别不同矿区共计138个样本。
1.2 样品分析方法
取适量试样均匀装入样品框中,用玻璃片把粉末压紧、压平至与样品框表面成一个平面。将试样片放入X射线衍射仪样品台上进行分析。测试仪器为德国布鲁克公司D 8 Focus X 射线衍射仪,测量使用Cu Kα线,采用连续扫描模式,工作电压为40 kV,电流为40 mA,扫描范围为5°~75°,步长为0.5°/步,扫描速度为0.5 s/步。
1.3 数据处理
1.3.1 主成分分析
主成分分析(Principal components analysis,PCA)是基于数据降维思想的一种定性模式识别方法[11],可以有效地对高维数据进行压缩,提取主成分的同时不丢失相关的重要信息,对分析复杂的光谱数据起到重要作用。在主成分分析的模型中,确定主成分的个数常用的方法为累计贡献率,即当前k个成分的累计贡献率达到某一特定值(一般要求80%以上[12])时,则保留前k个成分为主成分。通过主成分分析可以得到3组有效的信息数据,分别是主成分(Score)、方差贡献度(Explained)和载荷(Loading)。
1.3.2 随机森林
随机森林(Random forest,RF)作为一种新的基于决策树的机器学习方法的集成算法,与传统的分类算法相比,克服了分类精度低、拟合过度的缺点。随机森林分类的基本思想:首先,利用有放回的抽样方法从原始训练集抽取K个样本,且每个样本的样本容量都与原始训练集相同;其次,对K个样本分别建立K个决策树模型,得到K种分类结果;最后,根据K种分类结果进行投票表决决定其最优分类,随机森林分类原理如图1所示。
随机森林不仅可以用于分类,还可提取重要特征[13]。用随机森林对研究样本的数据进行特征重要性度量,选择重要性较高的特征。具体步骤如下:首先对每一棵决策树,选择相应的袋外数据(out of bag,OOB)计算袋外数据误差,记为errOOB1;其次随机对袋外数据所有样本的特征X加入噪声干扰(可以随机改变样本在特征X处的值),再次计算袋外数据误差,记为errOOB2;然后假设森林中有N棵树,则特征X的重要性= ∑(errOOB2-errOOB1)/N。这个数值能够说明特征的重要性是因为,如果加入随机噪声后,袋外数据准确率大幅度下降(即errOOB2上升),那么说明这个特征对于样本的预测结果有很大影响,进而说明重要程度比较高。最后,计算每个特征的重要性,并按降序排序,得到一个新的特征集。
2 结果与讨论
2.1 XRD谱图特征
采用X射线衍射分析技术对来自智利、秘鲁和墨西哥不同矿区的138个铜精矿样品进行物相分析。分析发现,样品来源为同一矿区的铜精矿X射线衍射谱图相似,因此选取同一矿区铜精矿中的一个代表性样品,绘制同一国别不同矿区的铜精矿X射线衍射图,如图2所示。
结合X射线衍射物相解析,铜精矿的主要物相是黄铜矿。从图2(a)中看出,智利7个矿区的铜精矿样品的X射线衍射谱图中,除黄铜矿衍射峰强度高之外,黄铁矿的衍射峰强度也很明显。对比图2(b)和2(c)可知,秘鲁和墨西哥矿区铜精矿样品中,除个别样品中黄铁矿的衍射峰强度低,其他样品中基本无黄铁矿的衍射峰。从图2(b)中可看出Toromocho矿区的秘鲁铜精矿样品在2θ为8°~10°位置的衍射峰强度较高。此外,铜精矿中还存在闪锌矿、石英、勃姆石、云母和滑石等物相,但这些物相的衍射峰强度较低。
2.2 主成分分析
2.2.1 利用主成分分析对XRD原始谱图降维
主成分分析的核心思想是降维,实验采集的138个铜精矿样品的衍射原始谱图从5°~75°共有1750个数据点,数据量大,冗余信息多。主成分分析将数据集从138×1750维数据减少到138×137维数据,即有137个主成分数,记为PCx(x = 1,2,3,4, ... ,137)。主成分解释方差贡献率趋势如图3所示,从图中可以看出,随着主成分数的增加,主成分解释方差贡献率增加比率逐渐降低。表1列出了前20个主成分的累计方差贡献率,前20个主成分的累计方差贡献率达到98.86%,基本包含了原始数据的所有信息。
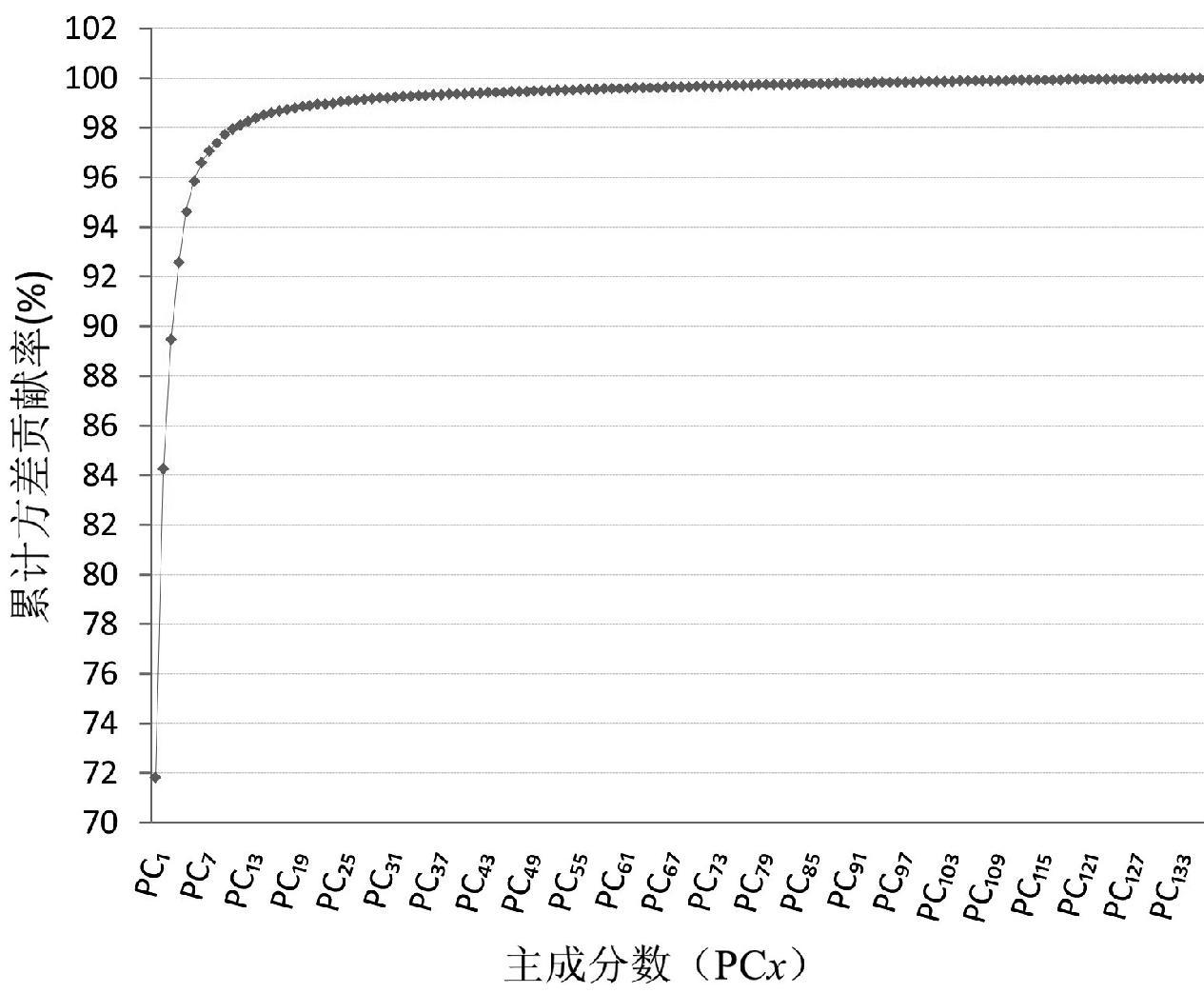
图3 主成分累计方差贡献率
Fig.3 Cumulative variance contribution of principal components
主成分分析也是无监督模式识别的一种分析方法。利用主成分PC1和PC2分别作为横坐标和纵坐标画散点图,如图4所示。在PC1和PC2的主成分得分散点图中可以观察到,3个国家的样本分布过于分散,且重叠部分严重,用无监督的主成分分析进行分类识别的效果不明显。
表1 前20个主成分的方差贡献率
Table 1 Variance contribution of the top 20 principal components
分数 | (%) | (%) | 分数 | (%) | (%) |
PC1 | 71.82 | 71.82 | PC11 | 0.23 | 97.96 |
PC2 | 12.43 | 84.25 | PC12 | 0.16 | 98.12 |
PC3 | 5.21 | 89.46 | PC13 | 0.15 | 98.27 |
PC4 | 3.12 | 92.59 | PC14 | 0.13 | 98.40 |
PC5 | 2.02 | 94.61 | PC15 | 0.11 | 98.51 |
PC6 | 1.22 | 95.83 | PC16 | 0.10 | 98.61 |
PC7 | 0.77 | 96.60 | PC17 | 0.08 | 98.69 |
PC8 | 0.46 | 97.06 | PC18 | 0.06 | 98.75 |
PC9 | 0.34 | 97.40 | PC19 | 0.06 | 98.80 |
PC10 | 0.33 | 97.73 | PC20 | 0.05 | 98.86 |

图4 主成分得分散点图
Fig.4 Scatter plot of principal components
2.2.2 利用主成分建立随机森林分类模型
选取主成分分析得到的137个主成分(138×137维矩阵)作为输入变量,建立随机森林分类模型进行分类,从PC1开始建立随机森林分类模型,每间隔增加一个主成分数,直到训练至PC1~PC137维,得到分类准确率曲线,如图5所示。从图中可看出,随着建模主成分数的增加,分类准确率先增加后降低并稳定在一定的范围,当取PC1~PC16或PC1~PC23建立随机森林分类模型时,分类准确率均可达到91.42%。结合主成分累计方差贡献率(表1)可知前16个主成分解释了XRD原始谱图98.61%的数据信息,因此取前16个主成分(PC1~PC16)建立随机森林分类模型,不仅可以减少变量,还能达到较高的分类准确率。
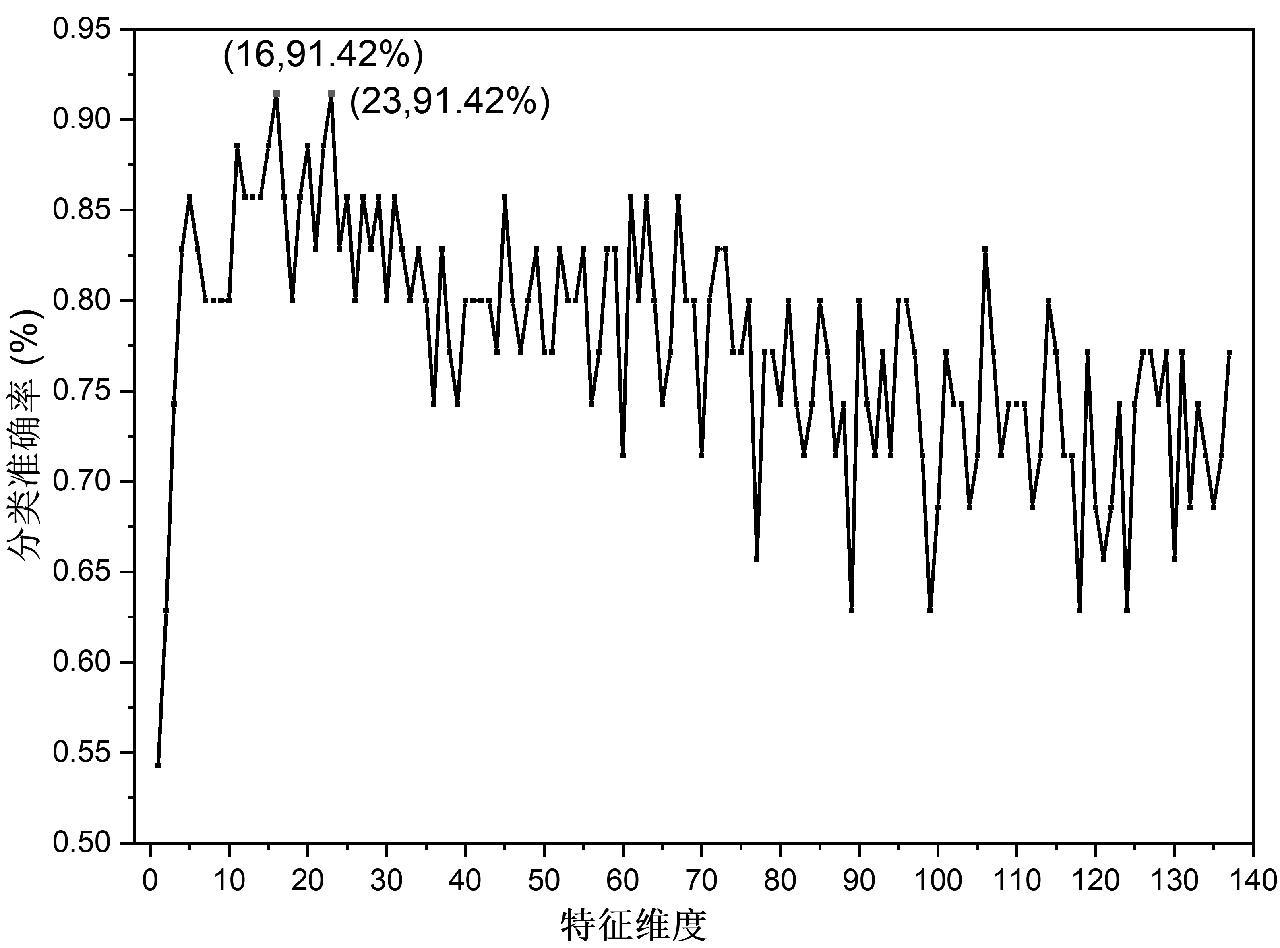
图5 主成分数建立随机森林分类模型准确率
Fig.5 Accuracy of random forest classification model based on principal components
2.2.3 利用主成分载荷阈值提取特征数据
利用主成分建立随机森林分类识别模型,虽然方法操作简单,但不能解释铜精矿X射线衍射谱图的特征。为了提高模型的性能和可解释性,需要提取光谱特征数据[14]。因此采用主成分载荷阈值法对铜精矿X射线衍射光谱数据进行特征提取。
载荷(Loading)是PCA算法中的一个重要结果,是高维数据的协方差矩阵的特征向量,以Loading PCx (x = 1,2,3…137)最大载荷绝对值的1/n作为特征变量选择的阈值,即选取载荷绝对值大于阈值的光谱数据作为特征变量数据[15]
 (1)
(1)
式(1)中,T为阈值;MaxPCx为主成分x的最大载荷绝对值;n为常数,n = 2,3,4,5。
通过2.2.2所述的结果可知,取前16个主成分(PC1~PC16)建立随机森林分类模型具有最高的分类准确率,因此采用前16个主成分利用载荷阈值法提取特征数据。根据式(1)计算,依次从PC1~PC16中挑选XRD谱图的特征线,当n = 5时,前16个主成分一共提取122个特征谱线数据。
本文仅重点对前3个主成分进行特征解释说明,如图6(a)、6(b)和6(c)分别为PC1、PC2和PC3载荷阈值图,图中的横线从上往下依次为当n = 2、n = 3、n = 4和n = 5的阈值,谱图中超过阈值的线即为该谱图中的特征线。从图中可看出,X射线衍射谱图中被选出作为特征谱线的点均为衍射峰强度高的点,且均有对应的物相,图6(a)为主成分PC1选取的载荷阈值图,当n = 5时,共有71个特征线强度大于阈值,这些特征线所对应的物相分别为黄铜矿(Ch)、黄铁矿(Py)、闪锌矿(Sp)和勃姆石(Bo)。图6(b)为主成分PC2选取的载荷阈值图,当n = 5时,共有16个特征线强度大于阈值,这些特征线所对应的物相分别为黄铜矿(Ch)和黄铁矿(Py)。图6(c)为主成分PC3选取的载荷阈值图,当n = 5时,共有14个特征线强度大于阈值,这些特征线所对应物相分别为黄铜矿(Ch)、黄铁矿(Py)和勃姆石(Bo)。
在主成分分析中,主成分PC1包含了所有的原始数据的大部分信息,所以在主成分PC1中可选出的特征线最多。在不同的主成分PCx中选取的特征线强度会有重复出现的情况,出现的次数越多说明该特征谱线越重要,因此对前16个主成分提取的122个特征谱线强度数据进行统计,主成分载荷阈值法提取的特征数据与铜精矿XRD谱图的关系如图7所示。从图中可以看出,122个特征谱线强度分别解释了X射线衍射谱图中的黄铜矿(Ch)、黄铁矿(Py)、闪锌矿(Sp)、斑铜矿(Bor)、勃姆矿(Bo)、石英(Qu)、黑云母(Bi)和滑石(Talc)的衍射峰,说明了利用光谱数据进行分析时,这些衍射峰的强度是很重要的。

图7 载荷阈值法提取特征数据与XRD谱图的关系
Fig.7 Relationship between feature data extracted by load threshold method and XRD spectra
2.2.4 基于主成分载荷阈值法提取特征数据建立随机森林分类模型
根据2.2.3中主成分载荷阈值法提取X射线衍射特征谱线数据的方法,从中选出122个特征谱线数据,作为随机森林分类模型的输入数据,建立随机森林分类模型,最终得到随机森林分类准确率为94.28%,与利用前16个主成分建立随机森林分类模型的91.42%分类准确率相比,采用主成分载荷阈值法提取特征谱线数据对分类准确率有进一步提升的作用。
2.3 随机森林
2.3.1 随机森林特征重要性
主成分载荷阈值法提取特征谱线数据的过程复杂,且谱线的选取计算过程因常数n选取的不同而产生较大的差异。随机森林在构造决策树节点时会寻找特征进行分裂,抽取特征中选择最优解,因此,随机森林同样具有特征重要性度量的功能。
采用随机森林对X射线衍射光谱数据进行特征重要性数据提取,将X射线衍射光谱数据根据随机森林提取特征重要性的大小依次进行降序排序,重新建立新的数据集。在这组数据中,随机森林特征提取的重要性在0~0.25之间,一共有791个X射线衍射数据点,其余959个X射线衍射数据点的重要性为0,即X射线衍射光谱数据1750个数据点中仅有791个数据点在随机森林分类时起作用。将特征重要性变量数据划分为3个等级,分别记为VI1、VI2、VI3,如图8所示,VI1为特征重要性在0.005~0.25之间,VI2为特征重要性在0~0.005之间,VI3为特征重要性为0。
将138个铜精矿X射线衍射原始数据采用随机森林算法进行特征重要性提取,得到一组随机森林特征变量数据,变量数据的特征重要性越大,对分类模型的贡献越大。随机森林特征变量数据与铜精矿XRD谱图关系如图9所示。从图中可以看出,特征重要性大的数据在铜精矿X射线衍射谱中对应的物相有黄铜矿(Ch)、黄铁矿(Py)、闪锌矿(Sp)、斑铜矿(Bor)、勃姆矿(Bo)、石英(Qu)、黑云(Bi)和滑石(Talc),且重要性最大的特征对应铜精矿X射线衍射谱图中黄铁矿的衍射峰。
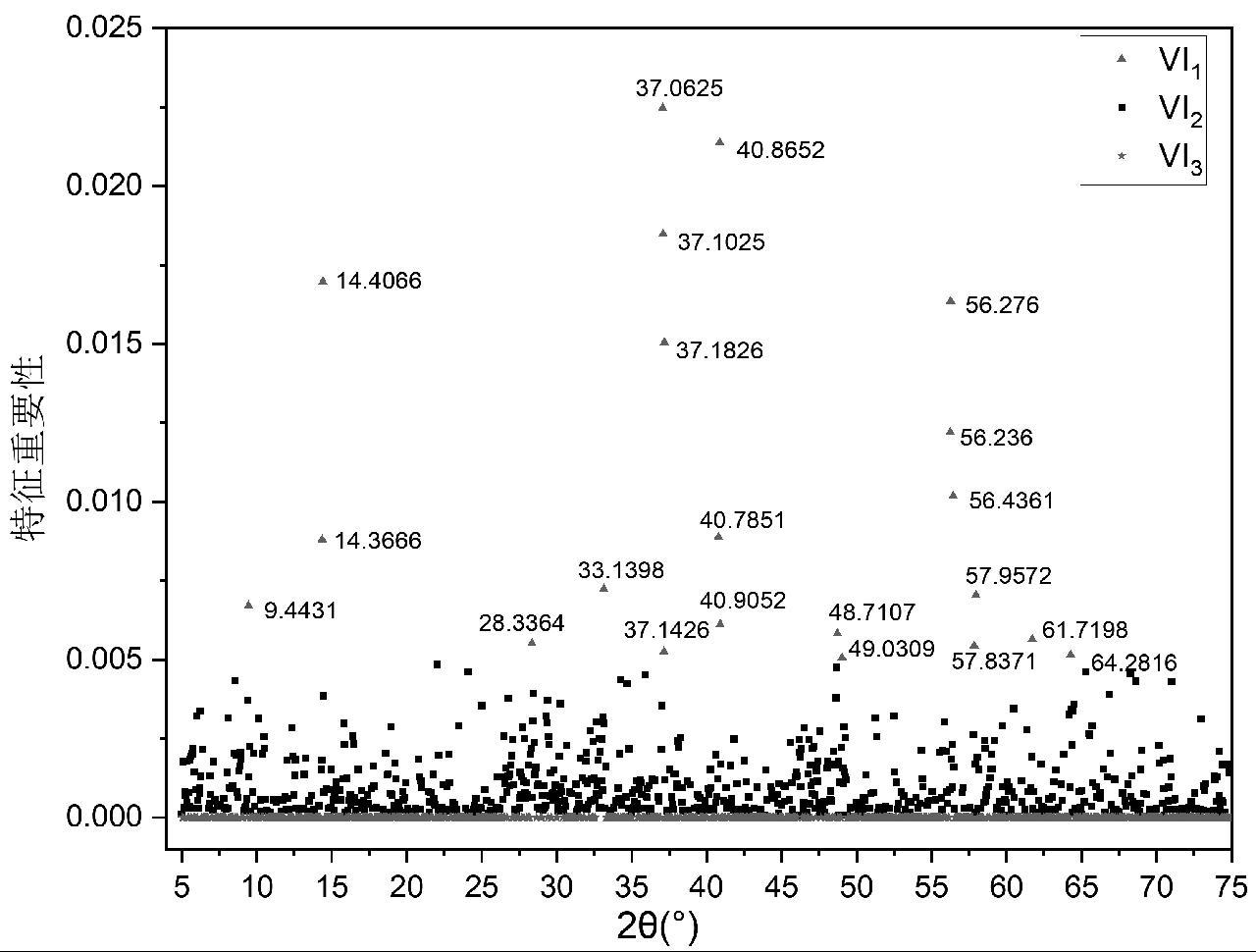
图8 随机森林特征重要性散点图
Fig.8 Scatter plot of random forest feature importance
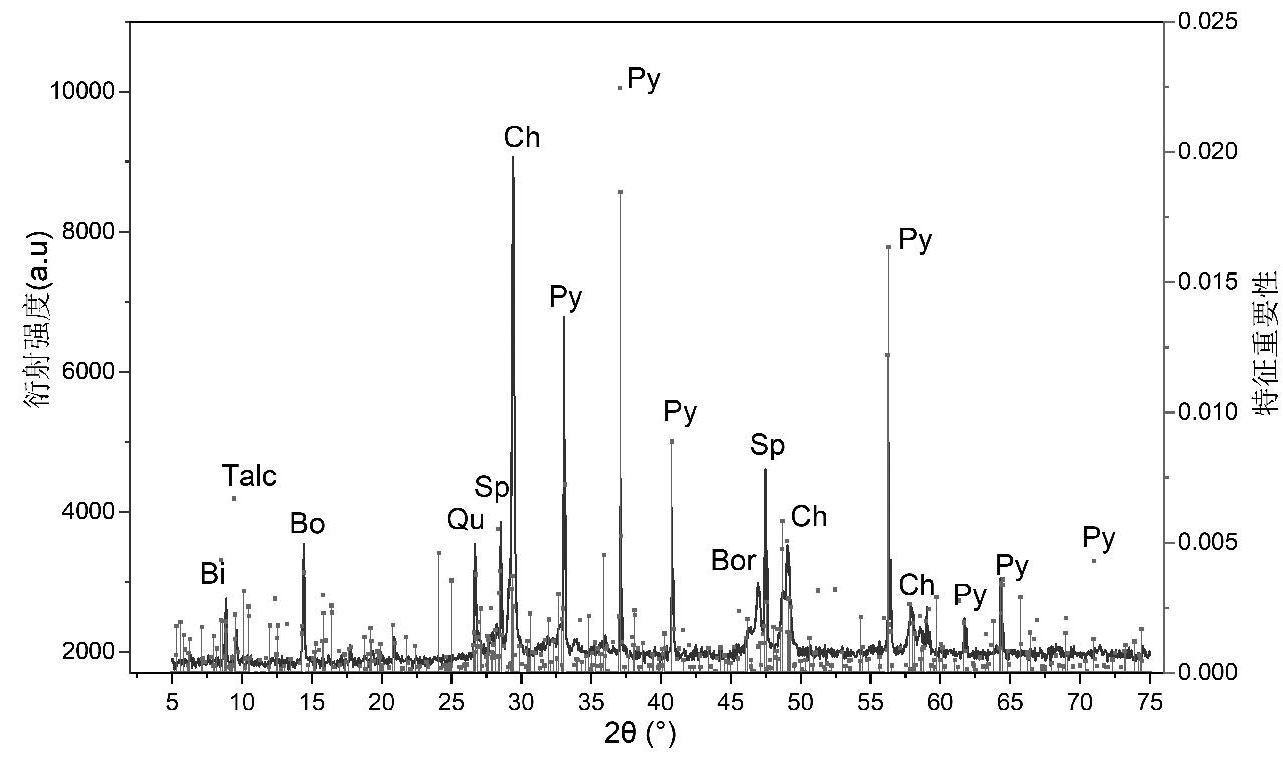
图9 随机森林特征重要性数据与XRD谱图的关系
Fig.9 Relationship between random forest feature importance data and XRD spectra
2.3.2 基于随机森林特征重要性数据建立随机森林分类模型
将138个铜精矿X射线衍射原始数据采用随机森林算法进行特征重要性提取,得到一组随机森林特征重要性数据。将这组数据按照特征重要性的大小依次进行排序,重新建立138×1750维数据,作为输入变量,建立随机森林分类模型。由于计算机建模的迭代次数多,分类模型计算所需时间较长,因此将138×1750维数据按维数为10的间隔建立分类模型,目的是从整体上看分类准确率,然后近一步选取特征重要性变量数据建立分类识别模型。
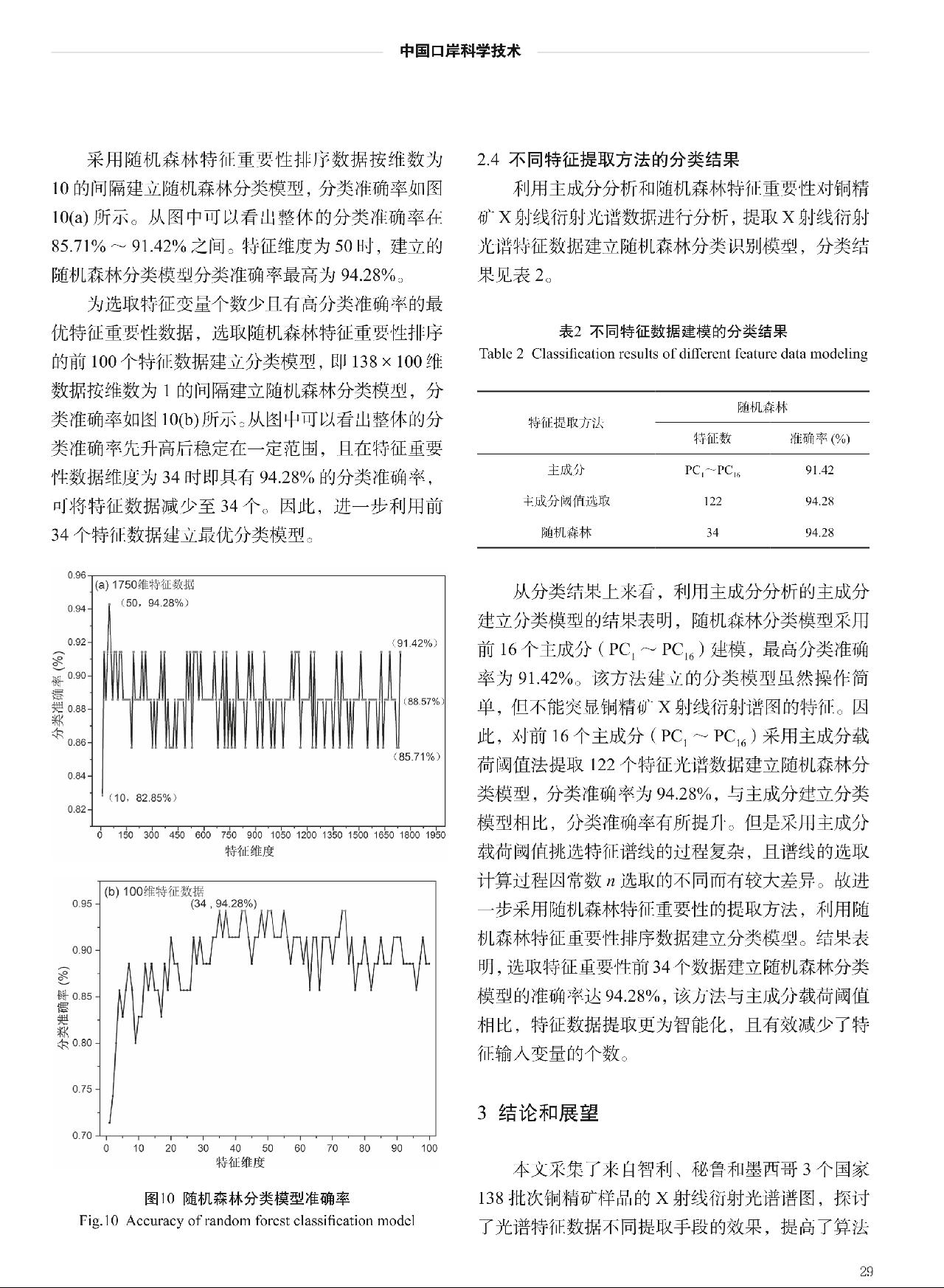
采用随机森林特征重要性排序数据按维数为10的间隔建立随机森林分类模型,分类准确率如图10(a)所示。从图中可以看出整体的分类准确率在85.71%~91.42%之间。特征维度为50时,建立的随机森林分类模型分类准确率最高为94.28%。
为选取特征变量个数少且有高分类准确率的最优特征重要性数据,选取随机森林特征重要性排序的前100个特征数据建立分类模型,即138×100维数据按维数为1的间隔建立随机森林分类模型,分类准确率如图10(b)所示。从图中可以看出整体的分类准确率先升高后稳定在一定范围,且在特征重要性数据维度为34时即具有94.28%的分类准确率,可将特征数据减少至34个。因此,进一步利用前34个特征数据建立最优分类模型。
图10 随机森林分类模型准确率
Fig.10 Accuracy of random forest classification model
2.4 不同特征提取方法的分类结果
利用主成分分析和随机森林特征重要性对铜精矿X射线衍射光谱数据进行分析,提取X射线衍射光谱特征数据建立随机森林分类识别模型,分类结果见表2。
表2 不同特征数据建模的分类结果
Table 2 Classification results of different feature data modeling
特征提取方法 | 随机森林 | |
特征数 | 准确率 (%) | |
主成分 | PC1 ~PC16 | 91.42 |
主成分阈值选取 | 122 | 94.28 |
随机森林 | 34 | 94.28 |
从分类结果上来看,利用主成分分析的主成分建立分类模型的结果表明,随机森林分类模型采用前16个主成分(PC1~PC16)建模,最高分类准确率为91.42%。该方法建立的分类模型虽然操作简单,但不能突显铜精矿X射线衍射谱图的特征。因此,对前16个主成分(PC1~PC16)采用主成分载荷阈值法提取122个特征光谱数据建立随机森林分类模型,分类准确率为94.28%,与主成分建立分类模型相比,分类准确率有所提升。但是采用主成分载荷阈值挑选特征谱线的过程复杂,且谱线的选取计算过程因常数n选取的不同而有较大差异。故进一步采用随机森林特征重要性的提取方法,利用随机森林特征重要性排序数据建立分类模型。结果表明,选取特征重要性前34个数据建立随机森林分类模型的准确率达94.28%,该方法与主成分载荷阈值相比,特征数据提取更为智能化,且有效减少了特征输入变量的个数。
3 结论和展望
本文采集了来自智利、秘鲁和墨西哥3个国家138批次铜精矿样品的X射线衍射光谱谱图,探讨了光谱特征数据不同提取手段的效果,提高了算法模型的可解释性,建立了X射线衍射谱图结合随机森林算法的铜精矿原产地识别技术。机器学习、深度学习算法的发展,为后续进一步拓宽样本数据、开展铜精矿原产国甚至是矿区的识别提供了强大的算法手段,将原产地识别算法与便携式X射线衍射仪相结合,有望为海关检验监管一线提供现场原位、实时高效的铜精矿风险筛查智能装备,保障进口铜精矿风险防控下的快速通关。
参考文献
[1]陈琳. 铜精矿采购对铜冶炼企业的影响[J]. 中国有色金属, 2023(7): 42-44.
[2] The World Copper Factbook 2023[R]. International Copper Study Group, 2023.
[3] 马永杰, 郭俊先, 郭志明, 等. 基于近红外透射光谱及多种数据降维方法的红富士苹果产地溯源[J].现代食品科技, 2020, 36(6): 303-309.
[4] 王翔, 赵南京, 殷高方, 等. 基于反向传播神经网络的激光诱导荧光光谱塑料分类识别方法研究[J]. 光谱学与光谱分析, 2019, 39(10): 3136-3141.
[5] Bi Y F, Zhang Y, Yan J W, et al. Classification and discrimination of minerals using laser induced breakdown spectroscopy and raman spectroscopy [J]. Plasma Science and Technology, 2015, 17(11): 923-927.
[6] 方匡南, 吴见彬, 朱建平, 等. 随机森林方法研究综述[J]. 统计与信息论坛, 2011, 26(3): 32-38.
[7] 李欣海. 随机森林模型在分类与回归分析中的应用[J]. 应用昆虫学报, 2013, 50(4): 1190-1197.
[8] Qi J, Zhang T L, Tang H S, et al. Rapid classification of archaeological ceramics via laser-induced breakdown spectroscopy coupled with random forest [J]. Spectrochimica Acta Part B-Atomic Spectroscopy, 2018, 149: 288-293.
[9] Sheng L W, Zhang T L, Niu G H, et al. Classification of iron ores by laser-induced breakdown spectroscopy (LIBS) combined with random forest (RF) [J]. Journal of Analytical Atomic Spectrometry, 2015, 30(2): 453-458.
[10] Tang H S, Zhang T L,Yang X F, et al. Classification of different types of slag samples by laser-induced breakdown spectroscopy (LIBS) coupled with random forest based on variable importance (VIRF) [J]. Analytical Methods, 2015, 7(21): 9171-9176.
[11] Porizka P, Klus J, Kepes E, et al. On the utilization of principal component analysis in laser-induced breakdown spectroscopy data analysis, a review [J]. Spectrochimica Acta Part B: Atomic Spectroscopy, 2018, 148: 65-82.
[12]杨兆龙, 章媛, 岳东杰. 主成分-多变量时间序列模型及其在桥梁变形预测中的应用 [J].现代测绘, 2019, 42(4): 1-4.
[13] Strobl C, Boulesteix A-L, Kneib T, et al. Conditional variable importance for random forests [J]. BMC Bioinformatics, 2008, 9:307.
[14] Garcia S, Fernandez A, Luengo J, et al. A study of statistical techniques and performance measures for genetics-based machine learning: accuracy and interpretability [J]. Soft Computing, 2009, 13: 959-977.
[15] Vors E, Tchepidjian K, Sirven J B. Evaluation and optimization of the robustness of a multivariate analysis methodology for identification of alloys by laser induced breakdown spectroscopy [J]. Spectrochimica Acta Part B: Atomic Spectroscopy, 2016, 117: 16-22.
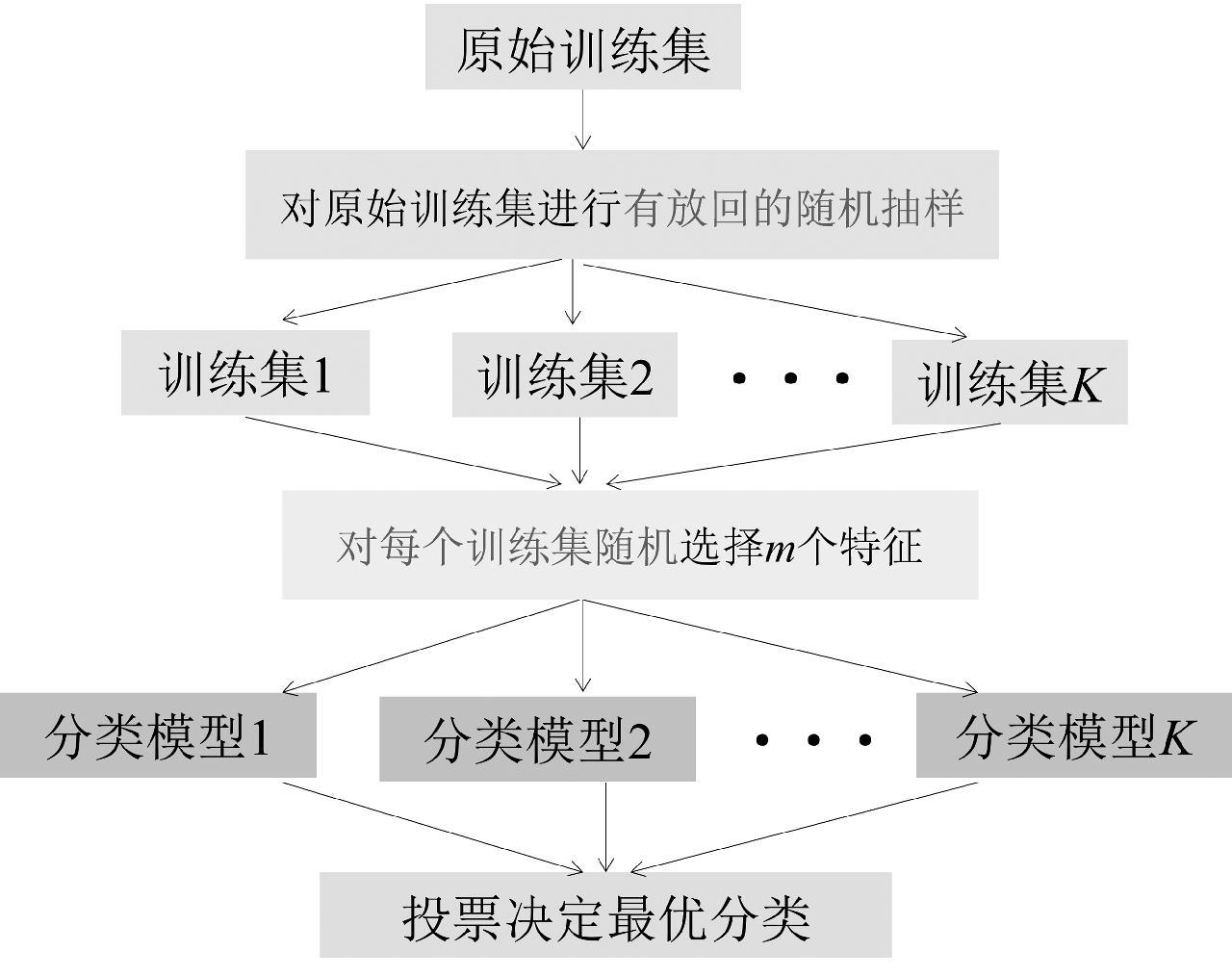
图1 随机森林分类原理图
Fig.1 Principle of random forest classification
1-黄铜矿; 2-黄铁矿; 3-闪锌矿; 4-石英; 5-勃姆石; 6-云母/滑石; 7-斑铜矿
图2 不同矿区铜精矿X射线衍射图
Fig.2 XRD spectra of copper concentrates from different origins
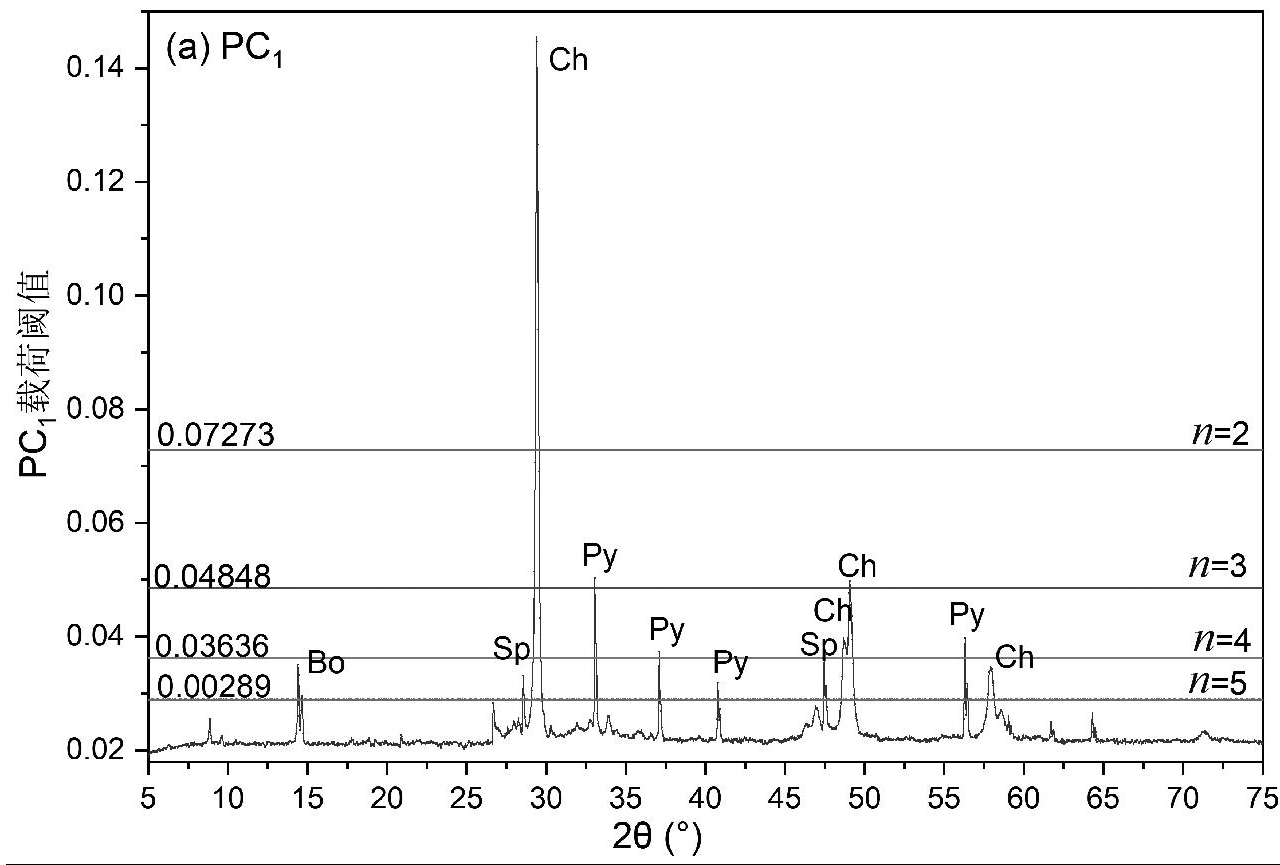
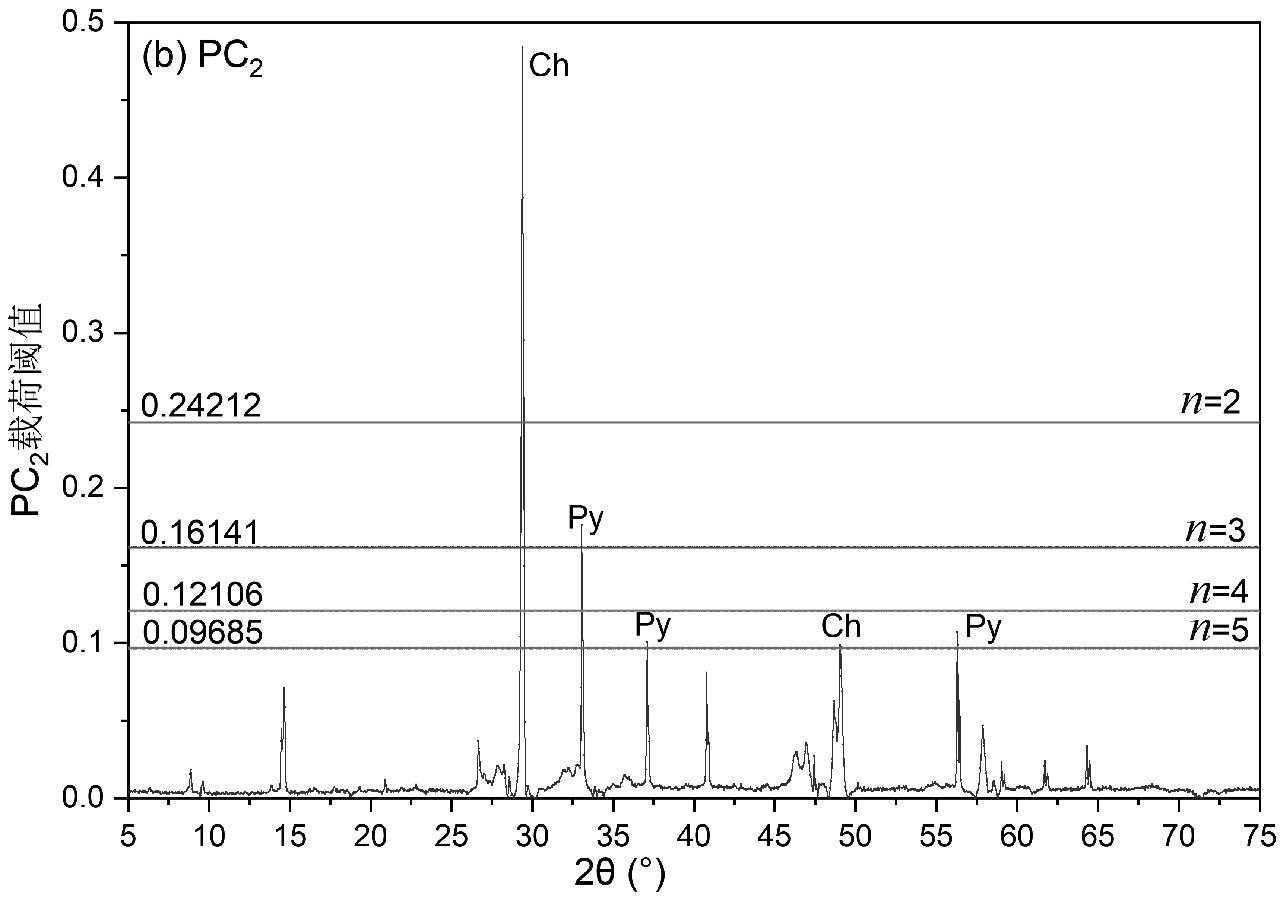
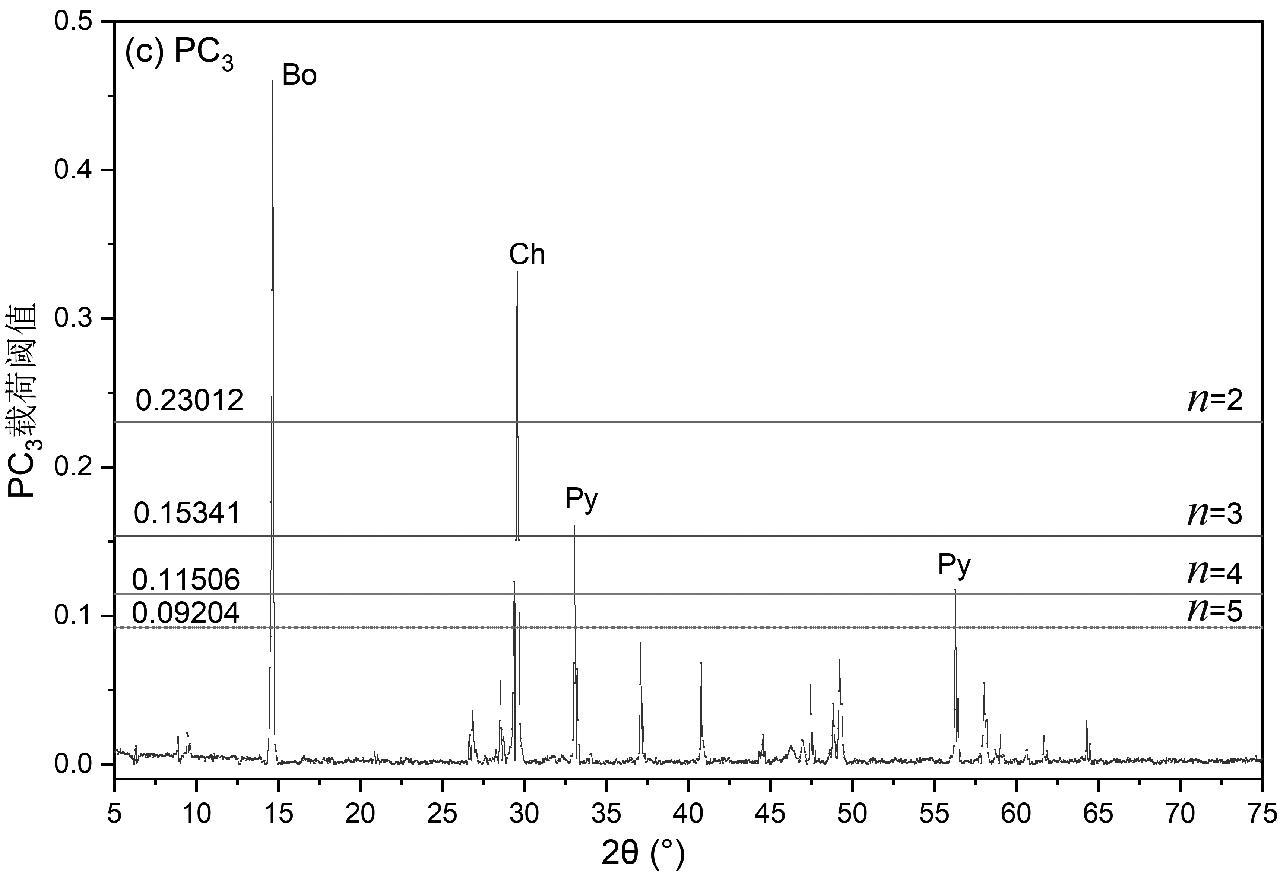
图6 载荷阈值图
Fig.6 Load threshold graph
基金项目:海关总署科研项目(2023HK008)
第一作者:孙鑫(1985—),男,汉族,天津人,本科,工程师,主要从事大宗资源商品检验及鉴别工作,E-mail: 18222266800@163.com
1. 天津海关化矿金属材料检测中心 天津 300457
2. 天津海关工业产品安全技术中心 天津 300457
3. 津海威视技术(天津)有限公司 天津 300300
1. Chemicals, Minerals & Metallic Materials Inspection Center of Tianjin Customs, Tianjin 300457
2. Industrial Product Safety Technology Center of Tianjin Customs, Tianjin 300457
3. Jinhai Nuctech Tianjin Company Limited, Tianjin 300300