





CopyRight 2009-2020 © All Rights Reserved.版权所有: 中国海关未经授权禁止复制或建立镜像

X射线荧光光谱结合分类算法在铁矿石与含铁物料鉴别中的应用研究
作者:王兵 徐鼎 秦晔琼 闵红
王兵 徐鼎 秦晔琼 闵红
摘 要 我国铁矿石贫矿多、富矿少、冶炼成本高的特点,使得我国钢铁行业铁矿石进口量较大,而铁矿石进口过程中以废充矿、以次充好等现象时有发生,对我国生态安全和经济安全造成威胁。因此,建立铁矿石掺假识别模型,快速验证铁矿石固废属性,对支撑进口铁矿石的风险监管、促进贸易便利化、保护生态环境安全具有重要意义。本研究以我国主要进口铁矿石及国内钢铁厂生产过程中产生的含铁物料样本为研究对象,应用波长色散X射线荧光光谱无标样分析法测定样本的元素组成及含量,利用KNN分类算法建立了铁矿石与含铁物料的鉴别模型。使用十重交叉验证方法对模型参数进行调优,并对模型识别能力进行评估,模型查准率、召回率和F1得分均达到1.0,模型对验证样本识别准确率为100%。波长色散X射线荧光光谱无标样分析方法前处理简单且数据稳定性好,该方法结合KNN分类算法,能够实现对进口铁矿石与含铁物料的快速准确识别。
关键词 铁矿石;含铁物料;X射线荧光光谱;K近邻算法
Application of X-ray Fluorescence Spectroscopy Combined with Classification Algorithm in the Identification of Iron Ore and Iron-Containing Materials
WANG Bing 1 XU Ding 1 QIN Ye-Qiong 1 MIN Hong 1
Abstract The prevalence of more lean ore, less rich ore and high smelting costs necessitates a substantial import of iron ore for China’s iron and steel industry. However, occurrences such as using waste to replace ore and substituting substandard goods for high-quality ones during the importation process pose threats to both the ecological and economic security. Establishing an identification model for iron ore adulteration and promptly verifying the solid waste properties of iron ore are crucial for supporting risk regulation of imported iron ore, promoting trade facilitation, and protecting ecological environment security. This study focuses on samples of imported iron ores and iron-containing materials produced in the production process of steel mills in China. The elemental composition and content of the samples were determined using WDXRF without standard sample analysis, and the KNN classification algorithm is used to establish the identification model of iron ore and iron-containing materials. The tenfold cross-validation method is used to optimize the model parameters and evaluate the model’s recognition ability. The model’s precision, recall rate and F1 score all reached 1.0, respectively, and the model’s recognition accuracy for validation samples is 100%. The WDXRF without standard sample analysis method has the advantage of simple pre-processing and good data stability. Combined with the KNN classification algorithm, this method can achieve fast and accurate identification of imported iron ore and iron-containing materials.
Keywords iron ore; iron-containing material; X-ray fluorescence spectrometry (XRF); k-nearest neighbors (KNN)
基金项目:国家重点研发计划项目(2018YFF0215400)
第一作者:王兵(1984—),男,汉族,安徽宿州人,硕士,高级工程师,主要从事矿产品检验检测工作,E-mail: wangbing216@163.com
1. 上海海关工业品与原材料检测技术中心 上海 200135
1. Technical Center for Industrial Products and Raw Materials Inspection and Testing of Shanghai Customs District, Shanghai 200135
铁矿石是钢铁工业的基础原材料,我国虽然是铁矿石储量大国,但贫矿多、富矿少、资源分布不均、冶炼成本高,使得国产铁矿石无法满足我国钢铁工业发展的需要。据海关总署公布的数据显示,2022年我国累计进口铁矿石11.07亿 t[1]。
铁矿石属于我国进口法定检验目录商品,长期以来对进口铁矿石实行“先验后放”的监管模式。为改善营商环境、压缩口岸通关时长,2018年8月海关总署将进口铁矿检验监管模式调整为“先放后检”,但从近年海关对进口铁矿石的检验监管情况来看,铁矿石进口过程中不乏伪报瞒报、掺杂使假等现象,威胁我国国门安全、经济安全和生态环境安全。传统现行铁矿石固体废物属性鉴别包括取样、制样、实验室分析、结论判定等环节,技术复杂,检测流程长,缺乏快速智能判定手段,难以完全满足快速通关模式下的风险监控需要。因此,亟待探索铁矿石快速、精准、智能的属性排查技术手段,在促进贸易便利化的同时,保障“依企业申请实施”检验模式下的进口铁矿石风险防控。
目前,实验室一般通过对样本的成分、物相、矿相等多项指标进行综合分析,结合文献资料,对铁矿石样本的属性进行鉴别。近年来,随着机器学习算法的日益发展,结合实验室检测技术手段,为铁矿石属性排查提供了新的技术途径。X射线荧光光谱分析是一种常用的无机分析技术,可以获取样本中除轻元素外的所有元素的种类和含量信息,具有无损分析、低检测限、分析速度快、应用范围广等优点。刘曙等[2]利用X射线荧光光谱结合判别分析技术对5个国家、21个品牌的422份进口铁矿石样品的产地和品牌进行识别。洪子云[3]将X射线荧光光谱数据融合拉曼光谱对铁矿石产品进行识别。陈永欣等[4]利用X射线荧光光谱法及其他方法测定进口铁矿样品中的主次元素含量,结合SPSS软件中4种算法对元素和产地品牌的关联程度进行计算,建立不同进口铁矿产地品牌识别模型。从以上文献分析可见,X射线荧光光谱结合分类判别算法识别铁矿石属性具有可行性。K近邻算法(K-Nearest Neighbors,KNN)是机器学习十大经典算法之一,也是唯一不需要创建复杂模型的算法[5],具有模型参数少、准确性高、对异常值和噪声有较高的容忍度等优点[6],简便易用,可实现对不同样本的有效分类。本研究利用KNN算法与X射线荧光光谱技术相结合,开展铁矿石与含铁物料的智能鉴别研究。
本研究共采集了856批进口铁矿石和107批含铁物料样本主次元素含量的半定量数据,对数据进行预处理后,建立铁矿石与含铁物料的判别分析模型。通过判别分析结果,表明智能分类模型的可用性,为进口铁矿石及含铁物料的快速准确分类提供了一种新的技术手段。
1 数据采集
1.1 样本收集
本研究从我国主要的铁矿石进口口岸采集并制备来自澳大利亚、巴西、南非、哈萨克斯坦、印度、秘鲁、缅甸、加拿大、毛里塔尼亚、蒙古国、伊朗等15个国家共856批次铁矿石样本。考虑到我国禁止进口如高炉渣、冶炼渣、除尘灰和氧化铁皮等含铁物料,因此从国内钢铁企业收集共107批次含铁物料样本(表1)。样本数量多、种类丰富,基本覆盖了我国进口铁矿石的主要来源国和主流品牌矿种,且包括较多铁矿非主流来源国样本,扩大了样本的范围和代表性,有利于提升未知样本的预测准确率。
1.2 实验方法
将样本置于105℃烘箱中干燥4 h,密封冷却至室温后取适量样本粉末使用压片机进行压片,压片前用乙醇清洗模具及压头,使用聚乙烯环聚拢粉末,压制样品在30 t压力下保持60 s。压制后检查压片表面均匀、无裂纹、脱落现象,用洗耳球吹去样品表面浮粉。使用德国布鲁克公司S8 Tiger型波长色散X射线荧光光谱仪中的无标样分析方法检测样本中元素及其含量。为保证检测数据的稳定和准确,试验中所有样本均由同一试验人员在同一台光谱仪上检测完成,样本检测条件保持一致。
1.3 数据汇集
全部样本检测完成后,按样本种类和元素名称收集所有检测数据,共收集963个样本的42种元素含量数据。另外,新增样本标签列,用于标记样本种类(1-铁矿样本,0-含铁物料),放置于同一张表格内。数据结构见表2。
2 数据处理
数据是模型运行的基础,决定能否成功建立模型及模型预测结果的准确与否。试验中收集的原始数据可能包含有重复值、缺失值、异常值及无法直接参与运算的非数值型数据等,建模前对数据进行清洗,使数据具备结构化特征,方便作为模型的特征输入。
Pandas数据处理模块是Python语言用于数据处理的强大工具,内置的各种函数可广泛用于数据预处理过程,包括数据类型转换、缺失值处理、数据汇总甚至数据可视化等。
2.1 重复值处理
重复值是指样本数据中存在两行或以上数据完全相同的情况。每个样本检测数据有几十种,不同样本检测数据完全相同的概率较低,有可能是数据整理过程中由于误输入造成,处理时使用dropduplicates函数将重复数据直接删除。经检验,963条检测数据中未见重复值。
2.2 缺失值处理
从原始样本数据结构表中可以看出,采集的963个样本中共检出有Fe、O、Ca、Al、Mn、Tb、Si、Mg、P、Na、Cr、K、Sr、S、Zr、Zn、V、Cu、Gd、Ba、Cl、Ni、Co、Mo、Pb、Ga、W、Sn等42种元素,其中所有样本全部检出的仅有Fe、O、Ca、Al、Mn、Si、Mg和P 8种元素,其余34种元素均存在部分样本未检出的情况(表2中NaN表示的数据)。
由于不同矿种的样本检出元素种类和数量不同,根据数据一致性原则,在数据预处理过程中,为避免数据在维度上缺失,对未检出元素进行零值填充,认为该矿种不含有该元素或元素含量低于仪器检出限范围,使得该部分元素未被检出。缺失值填充使用fillna函数完成。
2.3 异常值排查
异常值也称为离群值,是指同种类数据中明显偏离正常值的数据。本试验中产生异常值的原因可能包括非铁矿石样本、数据记录错误或设备原因等。异常值会使样本均值和方差产生明显偏差,导致算法错误或预测失败。对含铁物料,以Fe元素为例(图1),各样本Fe元素含量差异较大,数据分布无明显规律,是否为异常值不易判断,故对含铁物料保留所有元素含量数据,不进行异常值处理,仅对铁矿石样本数据进行异常值排查。
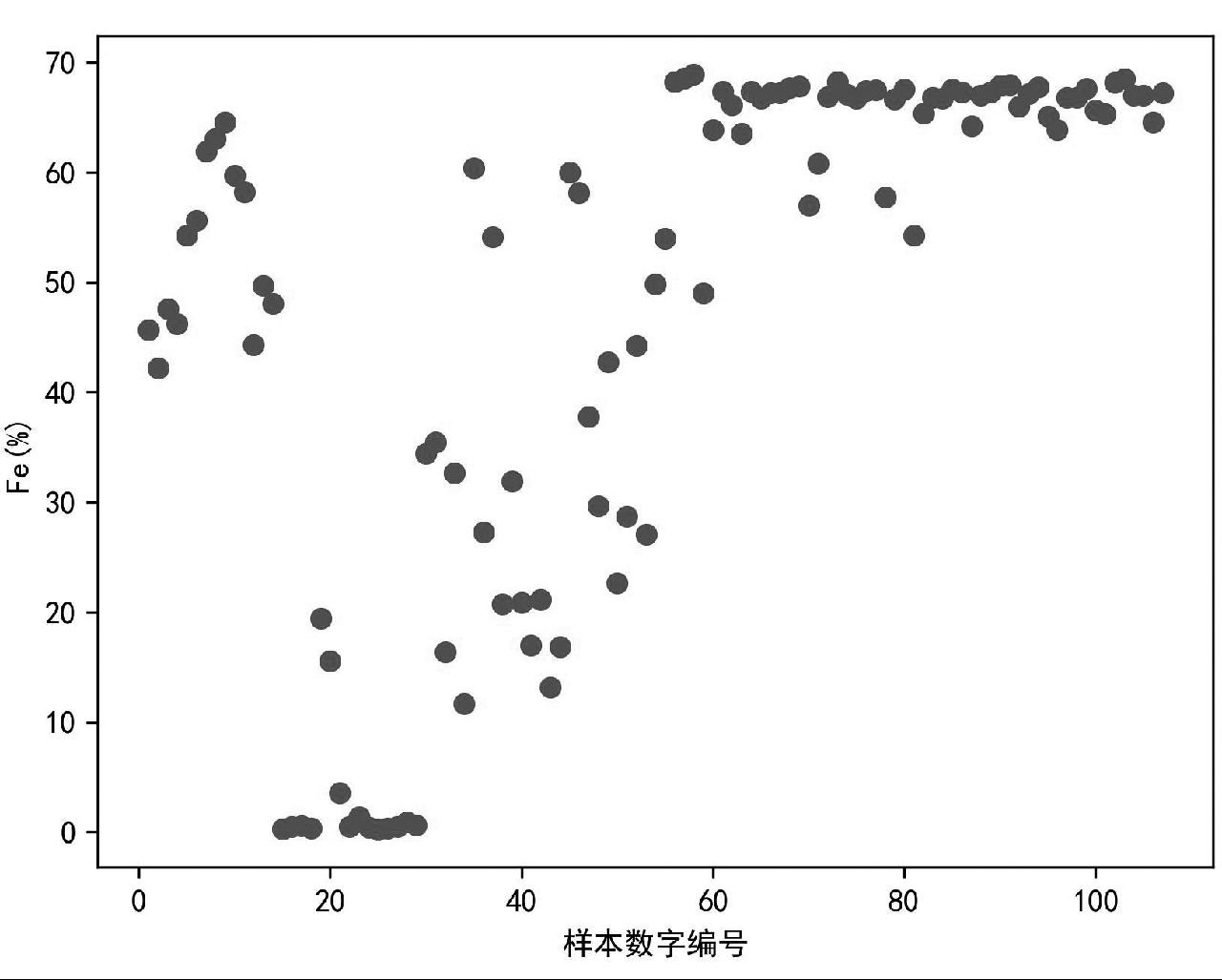
图1 含铁物料样本中Fe元素含量分布图
Fig.1 Scatter plot of Fe content in the sample of iron-containing materials
2.3.1 异常值检测
根据样本数据分布情况,异常值通常采用两种方法进行判断[7]:1)Z-score检测法,数据近似呈现正态分布时适用;2)箱线图判别法,箱线图不受异常值的影响,可以相对稳定地描述数据的离散分布情况,且异常点直接绘制在图形中(箱线图中圆点),视觉直观,便于判别,因此选用第二种方法进行异常值检测。以澳大利亚津布巴粉(Jimblebar Blend Fine,JMBF)铁矿各元素含量为例,直接用程序绘制出42种元素含量箱线图,图中红色圆圈标注即为异常值。图2所示为部分元素含量箱线图。
从图2中可以看出,由于缺失值补0的原因,个别样本的元素检出值被判定为异常值,为确认数值有无异常,进行异常值复核。
2.3.2 异常值复核
根据异常值数据的样本编号,找出该样本进行二次检测,检测条件及人员与一次检测时相同。将两次检测数据进行比对,确认“异常值”为真实检测值,予以保留。采用相同的方法对所有“异常值”进行复核,发现一皮尔巴拉块铁矿铁元素含量为79.05,判定为异常值,原因可能是数据记录过程中出错。将该样本所有检测值用二次检测值进行代替,再次进行异常值检测,未检出异常值。
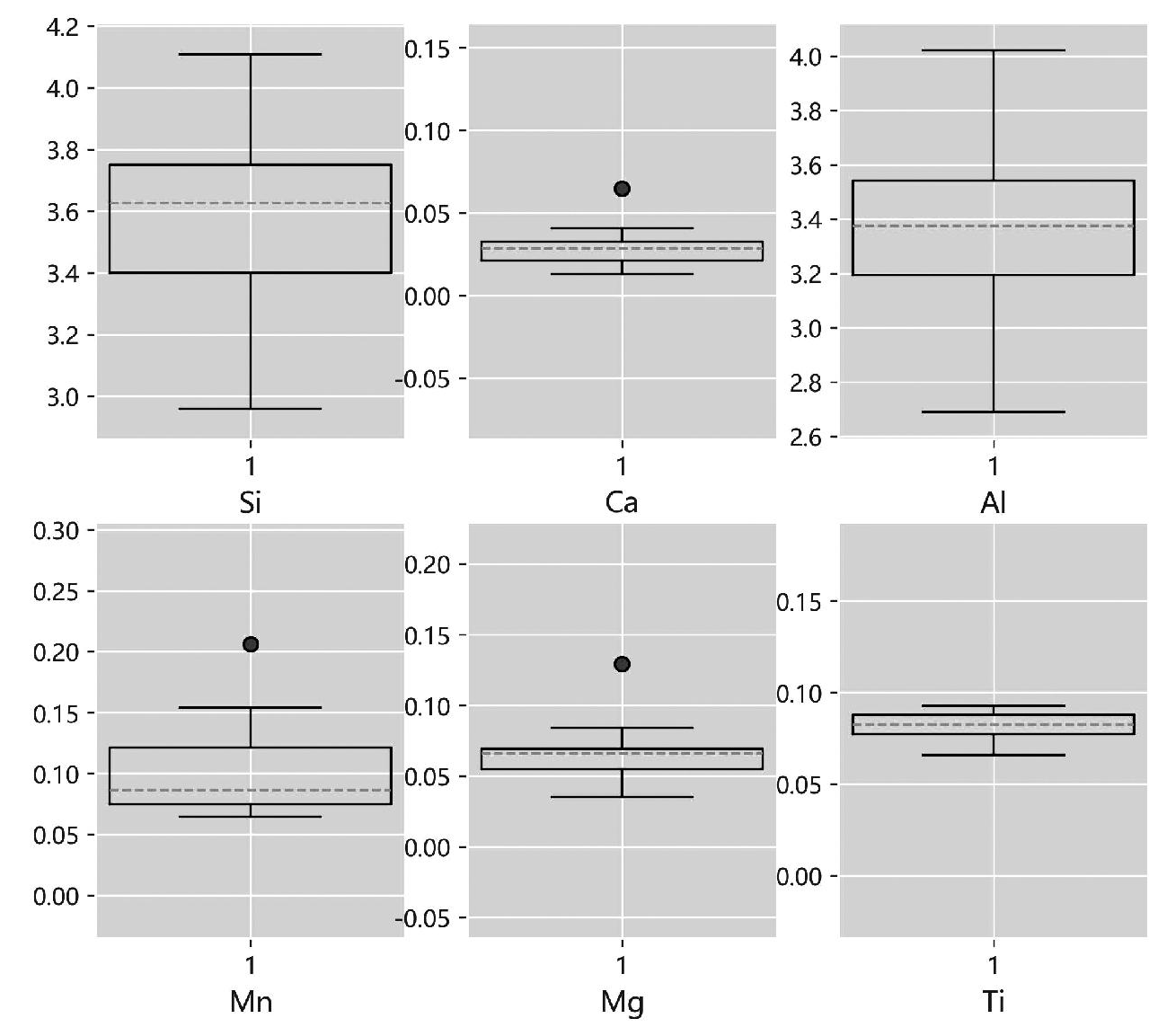
图2 津布巴粉铁矿部分元素含量箱线图
Fig.2 Boxplot of some elements content in JMBF iron ore
2.4 数据过采样
在963批次铁矿石及含铁物料样本中,107批为含铁物料样本,856批为铁矿石样本。样本分布不平衡,易使得含铁物料样本特征被忽略,使得训练出来的模型分类结果偏向于铁矿石样本,造成模型性能失真。为解决样本不均衡问题和最大程度保留已采集数据的特征价值,对含铁物料样本数据进行过采样处理,提高模型对含铁物料样本的学习能力,改善模型性能。过采样采用SMOTE算法(Synthetic Minority Over-sampling Technique,SMOTE)进行数据生成[8],使得正负样本数量达到均衡(图3)。
2.5 特征标准化
从表2原始数据可以看出,每一个样本数据均包含多个特征变量,不同变量数值差距较大,直接使用原始数据建模,会造成小数值特征被掩盖,影响模型准确度。为使得不同特征具有相同的尺度(Scale),故在建模前,应将特征数据进行标准化处理。
数据标准化也称为特征缩放(Feature Scaling),根据样本数据分布情况可知,每一特征数据近似符合正态分布,因此使用Z-Score(Z-Score Normalization)方法对数据进行标准化处理。该方法是基于特征原始数据的平均值Xmean和标准差std(X)进行数据的标准化,将样本特征值转换为符合平均值为0、标准差为1的正态分布。见公式(1)。
 (1)
(1)
式(1)中,X为样本的特征值,Xmean为所有样本该特征值的平均值,std(X)为所有样本该特征值的标准差。Scikit-learn机器学习包中的StandardScaler函数可用于数据标准化操作,皮尔巴拉混合粉(Pilbara blend fine,PBF)中Fe元素含量值标准化前后数据对比如图4所示,标准化前后的数据分布没有变化,只是缩小了量值分布的范围。
2.6 主成分分析
从表2可以看出,在所有42种元素中,大部分元素属于未检出状态,说明该元素在样本的特征贡献度上较低,用此特征数据训练模型,既增加数据运算量,降低模型运行效率又有可能产生过拟合现象,难以取得满意的预测结果。因此,在建立模型之前,对数据进行降维操作,同时保留绝大部分有效数据信息[9]。
设定数据还原率为90%,即保留原数据90%的信息特征,主成分数量和数据还原率的关系如图5所示。由图可知,选择主成分数量为20时,即可满足数据还原率要求,并达到较好的降维效果。
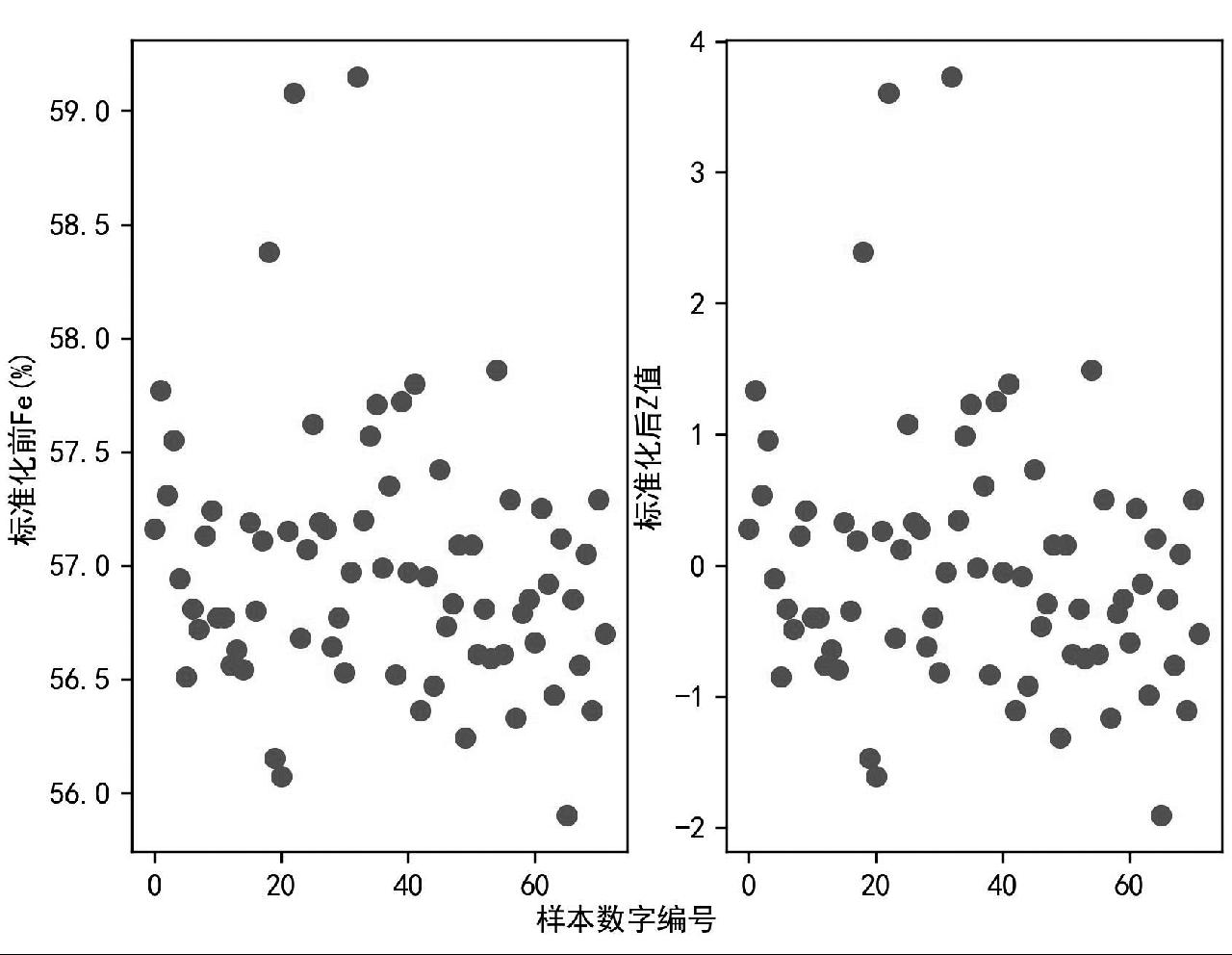
图4 皮尔巴拉粉中Fe元素特征值标准化前后数据比对
Fig.4 Comparison of data before and after standardization of Fe element characteristic values in PB fine
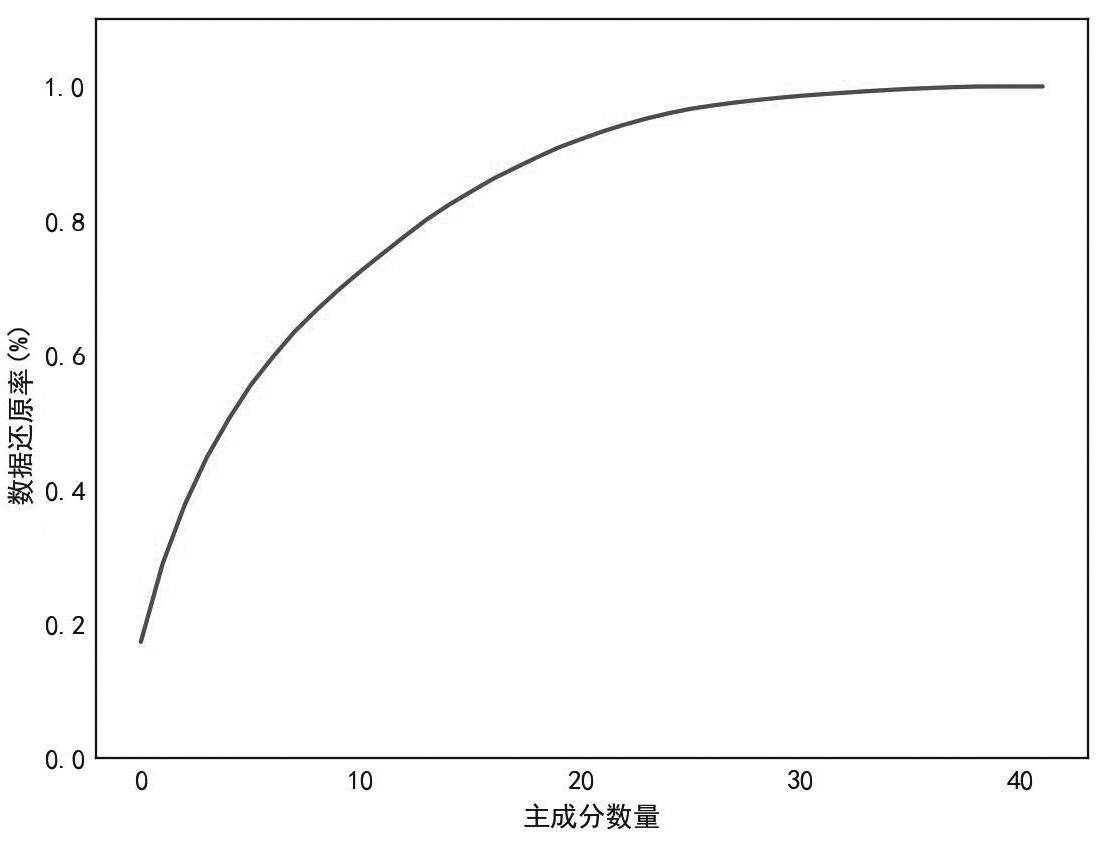
图5 主成分数量与数据还原率关系
Fig.5 Relationship between number of principal components and explained variance ratio
3 结果与讨论
3.1 数据集划分
使用sklearn机器学习包中的train test split函数将全部数据按7∶2∶1的比例划分为训练集、测试集和验证集,用于训练、测试和验证模型。
3.2 模型参数确定
KNN算法中,待分类样本周围的样本数kneighbors和待分类样本与周围样本的距离权重weights两个参数对模型预测结果影响较大。由于本实验中数据量较少,为充分利用数据进行模型训练和验证,使用10重交叉验证方法,比对每一个k值下模型的预测准确率,从而选出最佳k值。距离权重有两种设定“uniform”和“distance”,前者表示所有近邻样本距离权重一致,后者表示近邻样本与未知样本距离与权重成反比。在其他参数相同情况下,经不同权重参数模型结果比对,选择“uniform”时最佳k值为1,测试集预测准确率为98.99%,选择“distance”时最佳k值为4,测试集预测准确率为99.16%(图6),权重参数选择“distance”时模型性能更好。其余参数均使用函数默认值。
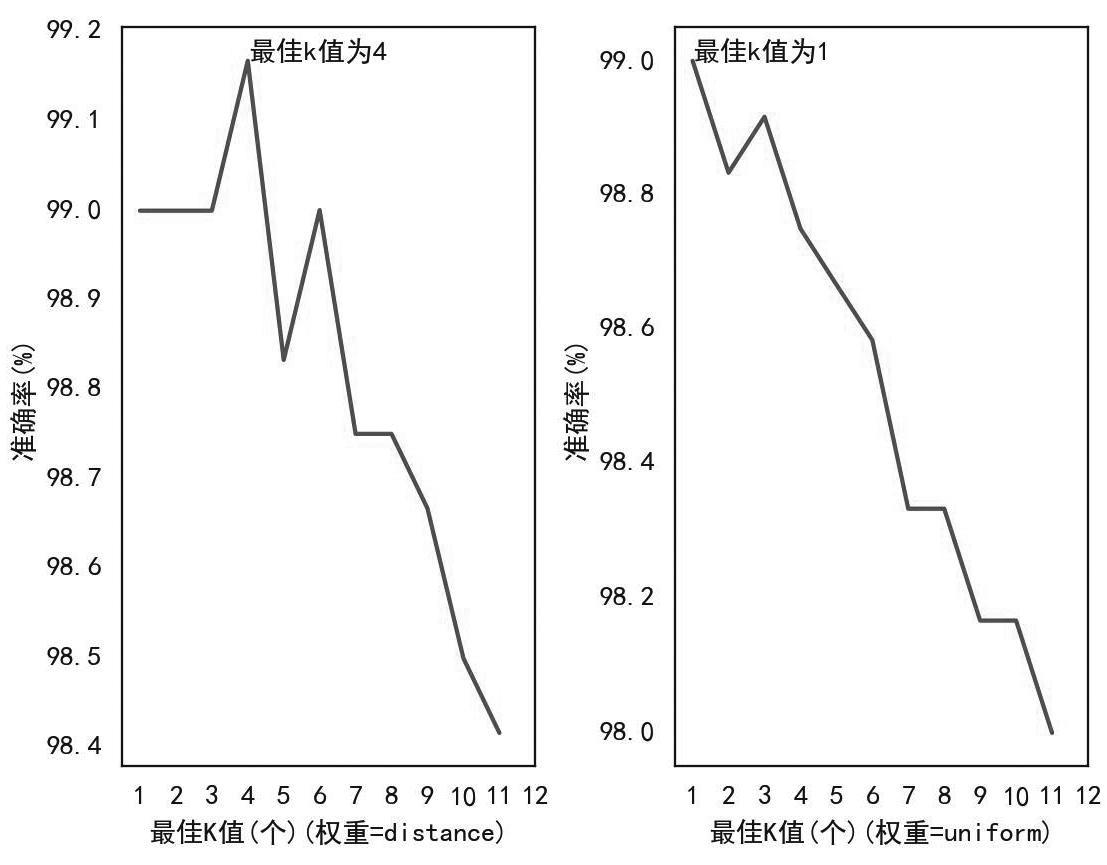
图6 不同权重下的k值预测准确率
Fig.6 Prediction accuracy of k values under different weights
3.3 模型建立及测试
使用sklearn机器学习包中neighbors模块下的K Neighbors Classifier工具,在优化的模型参数下,建立基于KNN算法的铁矿石和含铁物料分类模型。利用查准率P(Precision)、召回率R(Recall)和F1得分(F1 Score)[10]3项指标,衡量模型的性能。见公式(2)、(3)、(4)。
 (2)
(2)
 (3)
(3)
 (4)
(4)
式(2)—(4)中,TP表示模型预测结果和实际样本均为含铁物料的样本数量;FP表示模型预测为含铁物料,实际为铁矿的样本数量;FN表示模型预测为铁矿,实际为含铁物料的样本数量。将测试数据集x test输入模型进行测试,从结果混淆矩阵上可以看到,在344个测试样本中,全部预测正确,预测准确率为100%。查准率、召回率和F1得分均为1。
3.4 模型性能验证
将验证数据集x valid输入模型进行验证,从结果混淆矩阵上可以看到,在170个验证样本中,全部预测正确,预测准确率为100%。查准率、召回率和F1得分均为1。
4 结论与展望
本研究利用波长色散X射线荧光光谱无标样分析法结合KNN分类算法,建立了用于判别铁矿石和含铁物料的分类模型,测试集和验证集准确率均达到100%,说明模型在进口铁矿石和含铁物料区分识别方面准确性较高,方法可行,理论上已具备一定的应用能力。
文中模型是在小样本量下采用普通算法生成的,面对实际应用的大量数据,可通过改进算法结构,提升模型运行效率,改善模型大数据量下运行稳定性和流畅度,同时继续扩大样本库,尤其是含铁物料样本种类和数量,进一步提升模型识别能力。
随着人工智能的发展和各类便携式分析仪器性能的提升,将人工智能技术与现代仪器技术相结合,有望为海关检验监管一线提供实时高效、精准可靠的各类矿产品属性排查的新手段和能力,更好发挥执法把关技术支撑作用,保障进口矿产品快速通关条件下的风险防控,筑牢国门安全,奠定坚实基础。
参考文献
[1]中华人民共和国海关总署: 2022年12月全国进口重点商品量值表(美元值)[DB/OL]. http://www.customs.gov.cn//customs/302249/zfxxgk/2799825/302274/302275/4794311/index.htm
[2]刘曙,张博,闵红, 等. X射线荧光光谱结合判别分析识别铁矿石产地及品牌:应用拓展[J].光谱学与光谱分析, 2021, 41(1): 285-291.
[3]洪子云. 基于近红外光谱、拉曼光谱、X射线荧光数据融合的矿产品识别应用研究[D]. 上海: 东华大学, 2022.
[4]陈永欣,周山,李慈进, 等. SPSS在进口铁矿产地品牌识别中的应用[J].大众科技, 2022, 24(1): 5-11.
[5]张居营. 大话Python机器学习[M]. 北京: 中国水利水电出版社, 2019: 216-217.
[6]黄永昌. scikit-learn机器学习常用算法原理及编程实战[M]. 北京: 机械工业出版社, 2018: 69-70.
[7]刘顺祥. 从零开始学Python数据分析与挖掘[M]. 北京: 清华大学出版社, 2018: 93-99.
[8]唐宇迪. 跟着迪哥学Python数据分析与机器学习实战[M]. 北京: 人民邮电出版社, 2019: 149-153.
[9]裔隽, 张怿檬, 张目清, 等. Python机器学习实战[M]. 上海: 科学技术文献出版社, 2018: 164-171.
[10] Gavin Hackeling. scikit-learn机器学习(第二版)[M]. 北京: 人民邮电出版社, 2020: 81-84.
表1 测试样本信息
Table 1 The information of test samples
样本种类 | 产地 | 数量 (批) |
铁矿石 | 澳大利亚 | 455 |
巴西 | 109 | |
南非 | 69 | |
哈萨克斯坦 | 104 | |
印度 | 15 | |
秘鲁 | 6 | |
缅甸 | 7 | |
加拿大 | 17 | |
毛里塔尼亚 | 5 | |
蒙古国 | 6 | |
伊朗 | 16 | |
乌克兰 | 11 | |
瑞典 | 7 | |
越南 | 21 | |
智利 | 8 | |
氧化铁皮 | 45 | |
高炉渣 | 17 | |
除尘灰 | 38 | |
含铁污泥 | 7 |
表2 原始样本数据结构(%)
Table 2 Raw data structure of test samples (%)
样本编号 | Fe | O | Si | Ca | Al | As | Sb | Ag | Sc | Ho | kind |
Fe-001-01 | 55.22 | 31.8 | 3.370 | 0.0241 | 3.180 | NaN | NaN | NaN | NaN | NaN | 1 |
Fe-001-02 | 56.34 | 31.8 | 3.080 | 0.0217 | 2.820 | NaN | NaN | NaN | NaN | NaN | 1 |
Fe-001-03 | 55.66 | 32.8 | 3.650 | 0.0306 | 3.300 | NaN | NaN | NaN | NaN | NaN | 1 |
Fe-002-01 | 57.22 | 32.0 | 3.340 | 0.0190 | 3.530 | NaN | NaN | NaN | NaN | NaN | 1 |
Fe-002-02 | 57.85 | 31.2 | 2.960 | 0.0253 | 2.690 | NaN | NaN | NaN | NaN | NaN | 1 |
… | … | … | … | … | … | … | … | … | … | … | … |
Q-50 | 68.50 | 21.9 | 0.392 | 0.0800 | 0.047 | NaN | NaN | NaN | NaN | NaN | 0 |
Q-52 | 67.00 | 22.9 | 0.45 | 0.1080 | 0.060 | NaN | NaN | NaN | NaN | NaN | 0 |
Q-57 | 66.98 | 21.9 | 0.395 | 0.4600 | 0.318 | NaN | NaN | NaN | NaN | NaN | 0 |
Q-141 | 64.55 | 23.7 | 1.850 | 1.0850 | 0.293 | 0.004 | NaN | NaN | NaN | NaN | 0 |
Q-151 | 67.22 | 21.8 | 0.762 | 0.3280 | 0.154 | 0.004 | NaN | NaN | NaN | NaN | 0 |
注: 样本编号以“Fe”开头的为铁矿石样本, 非“Fe”开头的为含铁物料样本, “NaN”表示样本中未检出元素的值.
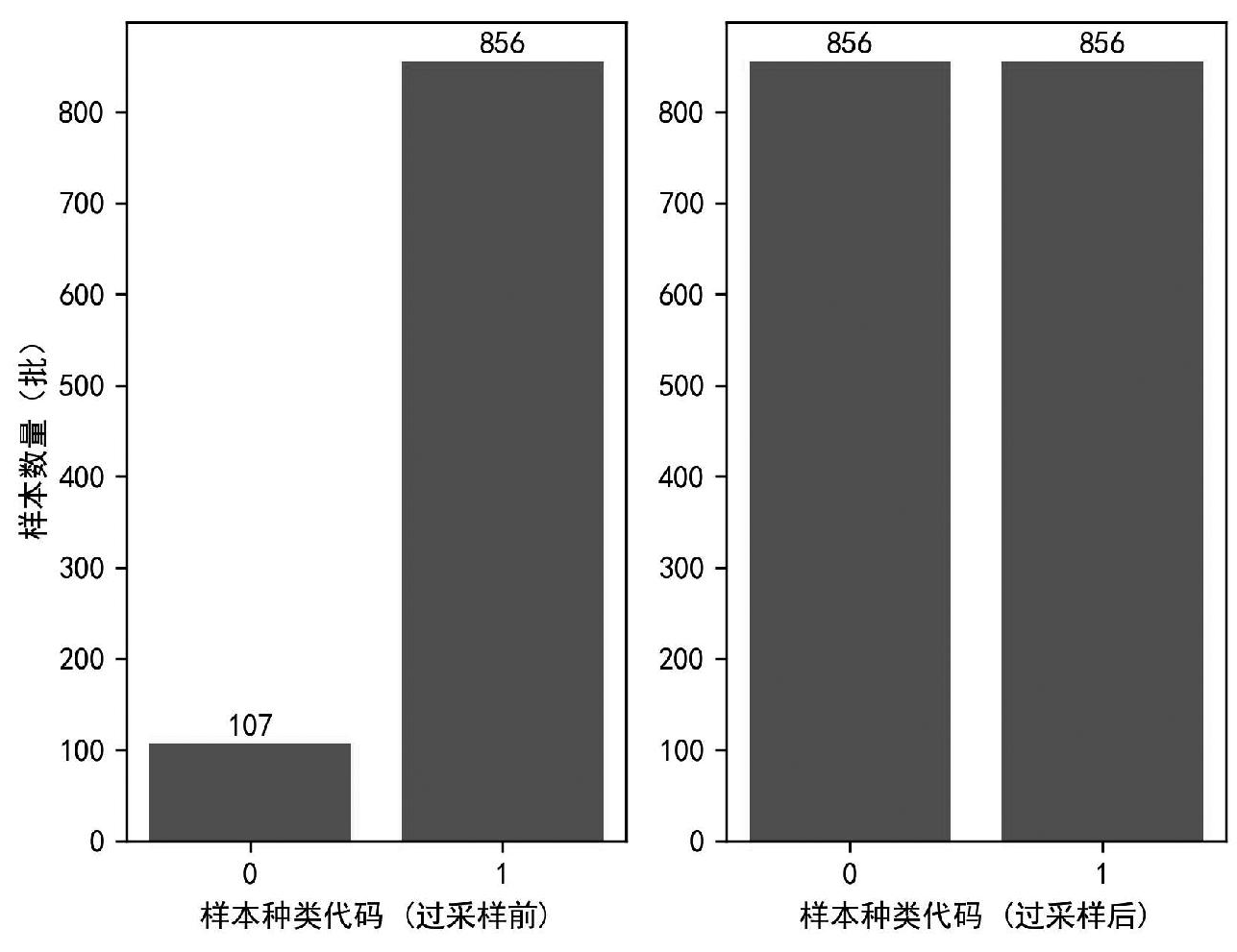
图3 数据过采样后正负样本数量对比
Fig.3 Comparison of positive and negative sample numbers after over-sampling
