





CopyRight 2009-2020 © All Rights Reserved.版权所有: 中国海关未经授权禁止复制或建立镜像

海关知识问答场景下的大语言模型应用研究
作者:王浩 陈广磊 王涵 侯成宇
王浩 陈广磊 王涵 侯成宇
摘 要 本文提出了一种基于检索增强生成(Retrieval-augmented Generation,RAG)技术的成本低、可靠性高的海关大语言模型技术方案。通过构建海关领域知识库、引入权限控制策略和优化模型训练,解决通用大语言模型在专业性、数据安全性和算力资源方面的局限,为提升工作效率和执法规范性提供技术支持。
关键词 海关知识问答;检索增强生成(RAG);大语言模型;数据安全
Research on Application of Large Language Models in Customs Knowledge Q&A Scenarios
WANG Hao 1 CHEN Guang-Lei 1 WANG Han 1 HOU Cheng-Yu 1
Abstract This paper proposes a cost-effective and highly reliable technical solution for large language models (LLMs) in the customs field based on retrieval-augmented generation (RAG) technology. By constructing a customs-specific knowledge base, incorporating access control strategies, and optimizing model training, this solution addresses the limitations of general LLMs in terms of professionalism, data security, and computing resources. It provides technical support for improving work efficiency and regulatory enforcement standards.
Keywords customs knowledge Q&A; retrieval-augmented generation (RAG); large language models (LLMs); data security
大语言模型(Large Language Model,LLM)结合知识库的应用模式在智慧海关建设中具有广泛的应用前景。通用大语言模型在海关的应用需满足以下要求:海关业务具有高度的专业性和规范性,需要将相关专业知识和业务流程融入大语言模型;海关对数据的安全性和可靠性要求高,需要设计完善的数据安全保护机制;海关重视人工智能应用,需要进一步优化项目间算力资源的分配与应用。针对上述挑战,本研究提出了一套基于检索增强生成(Retrieval-augmented Generation,RAG)技术架构的海关大语言模型技术方案,旨在通过引入专业领域知识库、设计科学的权限控制策略,以及优化模型训练策略,解决通用大语言模型在专业性、数据安全性和算力资源方面的局限性,构建一套能够精准回答海关专业问题、确保数据安全且高效利用有限算力资源的系统,以辅助海关工作人员提升工作效率和执法规范性。
1 研究概述
1.1 整体技术方案
本研究采用检索增强生成技术,通过检索海关知识库获取相关知识,将其融入提示词(Prompt)作为LLM回答问题的参考,提升LLM回答海关法规、制度、流程等问题的准确性、专业性。
整体技术方案主要分为数据准备阶段和应用阶段。(1)数据准备阶段:收集海关相关法律法规、制度、流程等内部文件,解析并切片为知识片段。利用预训练的文本向量化(Embedding)模型将这些片段转换为向量,并存储于高效的向量数据库中,便于快速检索。(2)应用阶段:当用户提问时,系统使用Embedding模型将问题转换为向量,在向量数据库中检索相关的知识片段。然后,将这些知识片段与问题一起构建Prompt输入给LLM,由其生成问题答案。
检索增强生成技术不仅减少了“幻觉”导致的错误,还支持知识库的实时更新,确保回答内容的时效性。
1.2 安全保密设计
在海关领域,大模型的安全性和保密性至关重要,必须进行安全保密设计,确保信息在大语言模型构建和使用过程中的安全。
本研究采用海关内网私有化部署,确保大语言模型的训练和推理过程与互联网完全隔离,从物理层面消除信息泄露隐患。为防止用户通过模型获取超出权限的文件内容,本研究设计了严格的分级管理,根据文件数据的保密级别进行权限控制,使大语言模型的应用符合海关各项安全与保密要求。
1.3 深度学习并行训练技术
随着大模型参数规模的不断增涨,单张计算卡(GPU)已不能满足大模型的训练需求,于是深度学习并行训练技术应运而生。具体方式可分为数据并行和模型并行,如图1所示。
数据并行将训练数据切分,每部分数据在独立GPU上进行前向和反向传播计算,然后通过参数同步机制更新全局大模型参数。该技术有效解决单张GPU训练大模型效率低下的问题,实现训练效率的倍数增长。
模型并行将大模型分割成多个子模型,每个子模型在独立GPU上计算,并通过通信协议交换必要的梯度或参数信息。该技术可以解决模型参数规模超出单张GPU显存容量等问题,实现多个GPU协同训练同一个模型。
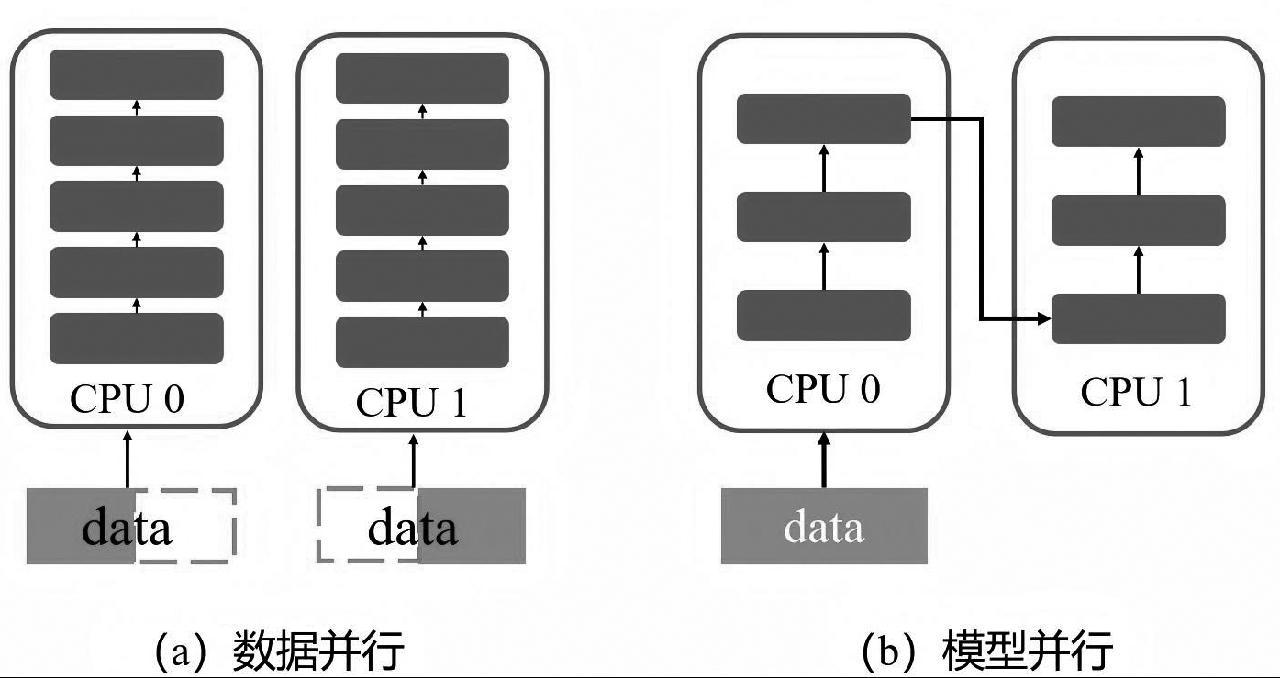
图1 模型并行原理示意图
Fig.1 Schematic diagram of model parallelism principle
深度学习并行训练技术能充分挖掘海关中低端型号GPU的潜力,通过合理设计并行训练策略及利用先进的深度学习优化库,实现大模型在这些中低配置设备上进行训练,提升海关算力设备利用率。
2 技术原理
本研究基于开源的RAGFlow框架进行定制开发,旨在构建一套专为海关业务场景设计的垂直领域大语言模型。RAGFlow框架技术成熟、功能全面,采用直观的UI交互设计实现了RAG的全流程配置。在此框架基础上,仅需对文档分割、Embedding模型、文本检索、LLM等核心模块进行定制,即可高效构建出适应海关业务需求的大模型。为了满足海关对安全保密的严格要求,本研究对RAGFlow的文本向量存储进行了重新设计,实现了分级管理。
2.1 文档分割
RAGFlow具有文档上传与解析功能,支持批量上传并高效读取文档内容。针对PDF、TIFF等非结构化文档,RAGFlow集成了OCR模型调用功能,支持调用多种OCR模型将文档内容识别为文字。本研究采用本地部署的百度PP-OCRv3模型,以确保识别效果与效率。
由于Embedding模型存在Token(字符)数限制,通常不超过512个字符,且为了便于后续的向量化与检索,须将长文档切割成多个语义相对完整的小片段。每个片段能独立表达完整意思,以确保信息的准确性和完整性。
本研究收集整理的文档涵盖了法律法规、岗位分工、操作流程、文件通知等内容,分割文档时须特别注意保证章节、段落的完整性。RAGFlow的分割算法能自动识别章节、段落结构,并优先按这些结构进行分割。对于无法识别结构的文档,本研究基于对样本文档段落长度的统计分析,将长度限制为250个字符,较短的长度有助于提升检索效率。
2.2 Embedding模型
经过分割的文档片段须进行向量化处理,以便实现高效的相似度计算和检索。具体是采用预训练的Embedding模型实现,本研究测试了gte-large-zh、bge-m3、m3e-base等中文开源模型,这些模型已经过大规模语料库的训练,能有效捕捉文本的语义信息。实验过程将在海关内部语料集上对上述模型进行微调,选择表现最优的模型集成到RAGFlow中。RAGFlow通过接口加载该模型文件,从而对文本进行向量化处理。
2.3 文本检索
RAG的核心是检索,从大规模语料库中精准提取与问题紧密相关的内容。随后LLM基于问题和检索到的内容生成最终答案。这一设计有效解决了LLM在细分领域常出现的“幻觉”问题,显著提升了答案的准确性和专业性。因此,检索结果的相关性对RAG大模型的整体效果至关重要。为了实现精准文本检索,RAGFlow采用Elasticsearch检索并结合重排模型,以提升检索结果的精准性和相关性。
RAGFlow集成了Elasticsearch,实现了向量的高效存储与检索。Elasticsearch作为一款开源搜索引擎,自7.x版本起引入向量检索功能,相较于传统向量数据库,在检索效率上展现出显著优势,并拥有多路召回能力。
RAGFlow基于Elasticsearch创新性地采用混合检索策略,结合向量检索与全文检索的双重优势,分别计算向量余弦相似度和关键词匹配率,按预设权重叠加得出混合相似度,最终根据混合相似度输出得分最高的TopK个检索结果。
为确保最相关且最具价值的检索结果能优先作为LLM回答问题的上下文输入,RAGFlow引入了重排序机制,通过算法模型对检索结果的相关性进行再次评估并调整输出顺序。RAGFlow通过接口方式灵活支持重排序算法模型的调用,本研究选用bge-reranker-v2-m3,该模型在中文领域展现出卓越性能与效果。
2.4 大型语言模型
RAG的最终环节是将检索到的内容与用户问题共同输入LLM,通过精心构建Prompt引导LLM生成针对该问题的最终答案。Prompt是一种用于指示或引导模型生成特定输出的文本。本研究着重设计了包含明确任务描述与背景知识(检索获得)的Prompt,如图2所示,旨在帮助LLM输出更为准确且符合预期的回答,提升生成质量和专业性。图2中的关键字{knowledge}将被RAGFlow自动替换为检索到的知识。

图2 知识问答Prompt内容
Fig.2 Prompt content for knowledge Q&A
RAGFlow通过API接口实现对LLM的调用,其设计兼具灵活性与兼容性,支持在线大模型部署平台如OpenAI、Moonshot的无缝接入,也兼容本地大模型部署框架如Xinference、Ollama。出于对数据安全的考量,本研究选择了Xinference作为LLM的本地部署方式。
在LLM的选型上,基于海关语料库主要语言为中文的特点以及算力资源有限的现状,主要考虑中文领域表现较好的3款开源LLM:Baichuan2-7B-Chat、GLM-4-9B-Chat以及Qwen2-7B。为进一步提升在海关场景中的适应性和表现,本研究将使用海关领域的专业语料对上述模型进行微调,并设计测试评估其效果,选择表现最优者作为最终选型。
2.5 知识权限管控
在海关业务场景下,鉴于部分公文属于涉密文件,海关大语言模型在未来应用中不可避免涉及这些文件,本研究在RAGFlow基础流程上进行了优化,基于统一多源的知识库结构设计了一套具备权限管控功能的新流程,以有效遏制潜在的泄密风险。
RAG大模型生成答案的知识来源有两个:(1)LLM本身通过预训练和微调融合的知识;(2)RAG通过检索方式提供的背景知识。本研究在LLM微调阶段对训练语料进行人工审核,确保不包含涉密文件;在RAG知识检索阶段,根据用户角色的权限控制检索范围,实现对不同级别文件的有效管控。
在RAGFlow的基础流程中,用户仅需配置一个知识库和一个LLM接口即可创建聊天机器人。由于所有文件都存储在同一知识库中,无法有效控制用户访问的文件范围。
本研究设计的新流程充分利用了RAGFlow中知识库与LLM可灵活复用的特性。首先,根据文件的保密级别进行细致分级,并将不同密级的文件存储在不同的知识库中。然后,根据不同用户角色的权限,配置专属的聊天机器人。这些聊天机器人根据其角色权限配置对应的知识库,实现了对不同分级知识的访问限制。同时,所有聊天机器人共享同一个大模型,确保用户体验的一致性。用户在前端提交问题时,权限路由策略会根据其角色自动将问题发送至相应的聊天机器人进行解答,从而实现了对知识访问权限的有效管控。
3 实验验证
3.1 语料收集
为了构建海关领域的内网知识库,本研究在数据安全管理规定框架下,收集整理海关内网1.2万个非涉密文档,涵盖Word、Excel、PDF、TXT、HTML、TIFF等多种格式,内容包含法律法规、规章制度、岗位分工、操作流程、内部通知、常见问题解答等多个类型。
筛选剔除重复或错误的文档,以确保数据准确性和可靠性。利用批处理程序,将文档转换成RAGFlow支持的格式(例如:将HTML转换为TXT,将TIFF转换为PDF)以便后续处理。调用RAGFlow的文件上传接口,将这些文档批量上传至系统。最后,RAGFlow自动解析这些文档并转换为向量进行存储,从而构建本地海关知识库。
为提高实验效果,实验还邀请了不同业务条线专家对问答内容对进行标注和审核,形成了一个包含1500条问答对的海关专业问答数据集,见表1。此数据集既丰富了知识库内容,又可用于LLM的微调,以提升模型输出的准确性和专业性。
表1 海关专业问答数据集样例
Table 1 Samples of customs professional Q&A datasets
问题 | 答案 |
公文中发文字号由哪几部分组成? | 发文字号应当包括机关(部门)代字、年份、序号. |
企业稽查的基本执法依据是什么? | 《中华人民共和国海关法》第四十五条是海关开展企业稽查最基本的执法依据. |
3.2 Embedding模型微调
为增强RAG在海关知识领域的检索能力,本研究对gte-large-zh、bge-m3、m3e-base共3款模型进行了微调和测试。
针对缺乏Embedding模型微调数据集的问题,本研究创新性地设计了一种利用LLM自动生成训练和评估数据集的方法。具体做法是:从本地知识库中加载知识片段,构建一个Prompt让LLM根据每个知识片段生成两个问题。生成的数据集包含3个子集:queries(问题集)、corpus(知识片段集)和relevant_docs(映射关系集)。
在微调Embedding模型时,由于无法直接测量其输出内容的正确性(在RAG中,Embedding模型的输出仅用于检索与问题相关的知识片段),本研究设计了一种名为“命中率”的评估算法。对于每个(query,relevant_doc)对,先根据query检索出向量距离最近的TopK个relevant_doc,如果正确的relevant_doc包含在内,则该条记录被视为“命中”。
微调采用全参数微调方式,使用Multiple Negatives Ranking Loss作为损失函数,在生成的数据集上进行训练,以提升Embedding模型检索结果的命中率。这种损失函数非常适合训练只有正例的检索用途的Embedding模型,因为它会在每个批次的训练数据中,从其他n-1个非相关的relevant_doc中随机抽样作为反例,从而计算损失值。
本研究分别测试了基线模型和微调模型的命中率,结果见表2。实验结果表明,微调后的Embedding模型在命中率上均优于基线模型,其中bge-m3的基线模型和微调模型均优于其他模型,因此最终采用bge-m3。
表2 Embedding模型命中率
Table 2 Hit rate of embedding models
Embedding模型 | 命中率 (%, 微调前) | 命中率 (%, 微调后) |
gte-large-zh | 79.62 | 90.56 |
bge-m3 | 85.23 | 97.39 |
m3e-base | 81.73 | 93.18 |
3.3 LoRA方法微调LLM
为增强LLM在海关业务领域的知识理解和生成能力,本研究采用LoRA(Low-rank Adaptation)方法对LLM进行微调。
LoRA通过在预训练模型的权重矩阵中引入低秩矩阵来实现微调。如图3所示,对于预训练模型中的每个权重矩阵W,LoRA冻结矩阵W的参数并添加一个低秩矩阵ΔW(包括B、A两个矩阵),微调过程只更新ΔW的参数,通过W+ΔW来模拟对W的微调。其中,矩阵W秩为d,参数规模为d×d,B、A的秩均为r,参数规模分别为d×r和r×d,则ΔW的参数规模为d×r+r×d。由于r远小于d,因此ΔW的参数规模也就远小于W。这种设计可以在不大幅增加模型参数量的情况下,对预训练模型进行高效的微调,因此LoRA特别适合资源受限的环境。
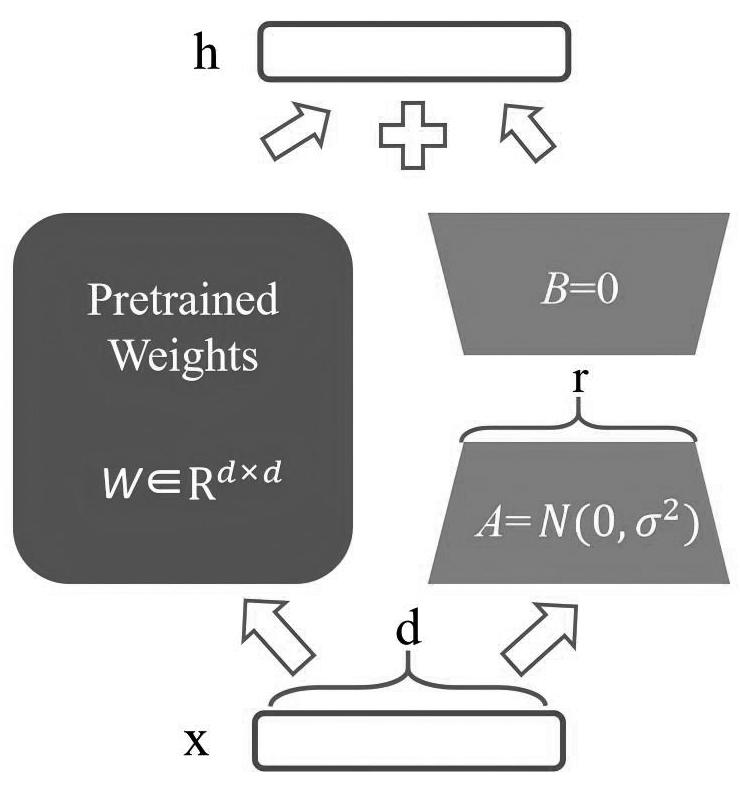
图3 LoRA原理示意图
Fig.3 Schematic diagram of LoRA principle
本研究使用了1500条海关专业问答数据集,并基于LoRA方法对预训练模型进行了微调,通过引入海关专业知识,显著提升了模型对海关领域实体、术语、概念等的理解和生成能力,使生成的答案更加准确、专业。
为比较LLM在微调前后的效果变化,本研究采用专家评分方式对基线模型和微调模型进行打分,共设置20个问题,采取10分制打分,取平均分作为模型最终得分,得分情况见表3。实验结果表明,经过微调后的大语言模型专家打分均有所提升,其中Qwen2-7B的输出更适合海关知识领域。
表3 大语言模型专家打分结果
Table 3 Scoring results by LLM experts
大语言模型 | 专家打分 (微调前) | 专家打分 (微调后) |
GLM-4-9B-Chat | 7.067 | 7.716 |
Qwen2-7B | 7.425 | 8.344 |
Baichuan2-7B-Chat | 6.638 | 7.153 |
4 结语
本研究针对构建海关大语言模型的实现路径进行了探索,解决了通用大语言模型对海关专业性知识覆盖不足、数据安全保障设计不完善以及算力资源要求高等关键问题。基于RAG技术架构设计并实现了一套低成本、高可靠的大语言模型的技术方案,融合海关专业知识,精准回应海关工作人员在执法过程中遇到的专业性问题,极大提升了工作效率和执法规范性。通过私有化部署和权限管控机制,满足海关对数据安全性和可靠性的极高要求。在算力资源有限的条件下,通过优化模型训练策略和引入高效并行计算技术,实现高效训练与部署。未来,随着技术发展和数据积累,该方案将具备更强的知识服务能力和更广泛的应用场景,助力智慧海关建设。
参考文献
[1] Yunfan Gao, Yun Xiong, Xinyu Gao, et al. Retrieval-Augmented Generation for Large Language Models: A Survey[J/OL]. ArXiv, 2023, abs/2312.10997.
[2]曾骏, 王子威, 于扬, 等. 自然语言处理领域中的词嵌入方法综述[J]. 计算机科学与探索, 2024, 18(1): 24-43.
[3] Rajbhandari, S., Rasley, J., Ruwase, O., He, Y.. ZeRO: Memory Optimizations Toward Training Trillion Parameter Models[C]. SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, 2019, 1-16.
[4] Ding, H., Pang, L., Wei, Z., et al. Retrieve Only When It Needs: Adaptive Retrieval Augmentation for Hallucination Mitigation in Large Language Models[J/OL]. 2024, ArXiv, abs/2402.10612.
[5] Hu, M., Peng, Y., Huang, Z., et al. Retrieve, Read, Rerank: Towards End-to-End Multi-Document Reading Comprehension[J/OL]. 2019, ArXiv, abs/1906.04618.
[6] Bsharat, S.M., Myrzakhan, A., Shen, Z.. Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4[J/OL]. 2023, ArXiv, abs/2312.16171.
[7] Wang, H., Huang, W., Deng, Y., Wang, R., et al. UniMS-RAG: A Unified Multi-source Retrieval-Augmented Generation for Personalized Dialogue Systems[J/OL]. 2024, ArXiv, abs/2401.13256.
[8] Henderson, M., Al-Rfou, R., Strope, B., et al. Efficient Natural Language Response Suggestion for Smart Reply[J/OL]. 2017, ArXiv, abs/1705.00652.
[9] Hu, J.E., Shen, Y., Wallis, P., et al. LoRA: Low-Rank Adaptation of Large Language Models[J/OL]. 2021, ArXiv, abs/2106.09685.
基金项目:海关总署科研项目(2023HK085)
第一作者:王浩(1990—),男,汉族,山东青岛人,本科,主要从事人工智能项目开发与管理工作,E-mail: wang_hao2@outlook.com
1. 青岛海关 青岛 266002
1. Qingdao Customs, Qingdao 266002
