





CopyRight 2009-2020 © All Rights Reserved.版权所有: 中国海关未经授权禁止复制或建立镜像

人工智能大模型在海关实验室的本地化应用及开发研究
作者:张彦彬 冯锦祥 陈江南 纪梓杉 叶郁 毛棣 李嘉敏 苏杨
张彦彬 冯锦祥 陈江南 纪梓杉 叶郁 毛棣 李嘉敏 苏杨
张彦彬 1 冯锦祥 2 陈江南 3 纪梓杉 1 叶 郁 3 毛 棣 3 李嘉敏 1 苏 杨 1 *
摘 要 智慧实验室是智慧海关建设中的一项重要工作,应用人工智能(Artificial Intelligence,AI)大模型可以提升海关实验室的工作效率和服务水平。本文聚焦海关实验室“数智化”典型应用场景,以AI大模型在海关实验室领域的数据共享与开发应用为研究对象,分析DeepSeek等大模型在海关实验室本地化应用的可行性与必要性,研究本地知识库在数据共享、数据分析和辅助决策中的作用,探讨如何集成应用DeepSeek等大模型和人工智能技术与工具赋能海关实验室业务工作。本文提出了AI大模型本地化应用的技术路线和知识库搭建的实施方案,以广州海关实验室大模型“数智化”场景应用的阶段性成效为例进行了总结与展望,为推进智慧海关建设提供参考。
关键词 智慧海关;DeepSeek;智慧实验室;大模型;人工智能
Smart Laboratories in the Context of Smart Customs: Application and Development of AI Large-models
ZHANG Yan-Bin1 FENG Jin-Xiang2 CHEN Jiang-Nan3
JI Zi-Shan1 YE Yu3 MAO Di3 LI Jia-Min1 SU Yang1*
Abstract Smart laboratories are a vital component of Smart Customs construction. The application of artificial intelligence (AI) large-models can significantly enhance the efficiency and service quality of customs laboratories. This article focuses on a typical application scenario of Digital-Intelligence in customs laboratories, taking the data sharing and development application of AI large-models in customs laboratory field as the research object. It analyzes the feasibility and necessity of localizing large-models such as DeepSeek in customs laboratories, investigates the role of local knowledge bases in data sharing, data analysis, and decision-making assistance, and explores how to integrate the application of big models such as DeepSeek and AI technologies to empower customs operations. The article proposes a technical roadmap for localizing AI-LMs applications and an implementation plan for building a knowledge base. Taking the phased effectiveness of the Digital-Intelligence application scenario of Guangzhou Customs laboratory’s large-models as an example, it provides a summary and outlook to serve as a reference for advancing the construction of Smart Customs.
Keywords Smart Customs; DeepSeek; smart laboratories; large-models; artificial intelligence (AI)
第一作者:张彦彬(1975—),男,汉族,山东日照人,本科,高级工程师,主要从事信息技术管理工作,E-mail: 13925001898@139.com
通信作者:苏杨(1988—),女,汉族,河南信阳人,硕士,工程师,主要从事信息化测试验证工作,E-mail: 936491750@qq.com
1. 广州海关技术中心 广州 510623
2. 海关总署广东分署学会 广州 510130
3. 广州海关 广州 510623
1. Guangzhou Customs Technology Center, Guangzhou 510623
2. Guangdong Branch of General Administration of Customs, Guangzhou 510130
3. Guangzhou Customs, Guangzhou 510623
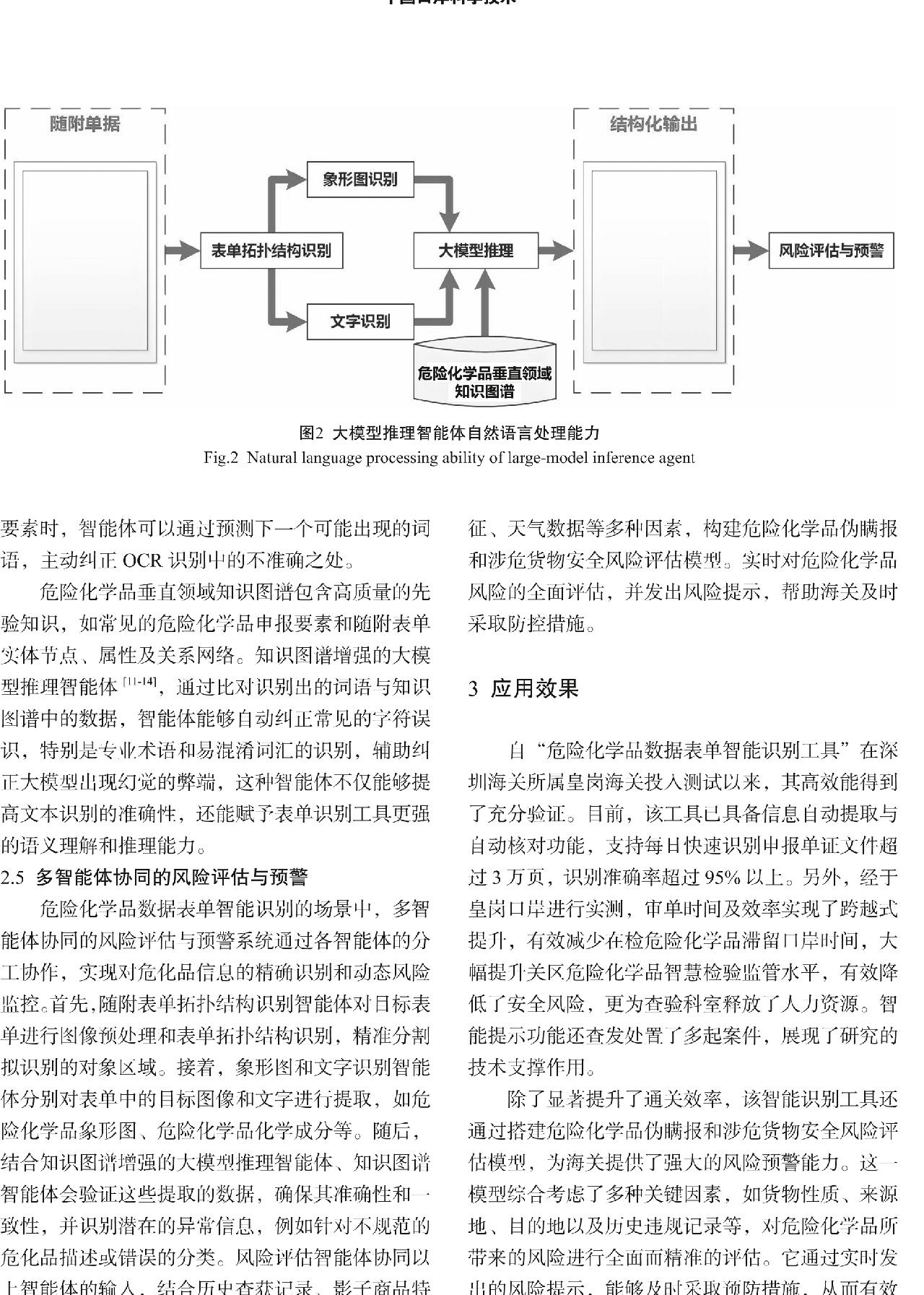
随着全球贸易的快速发展,海关监管工作面临新的挑战。如何利用人工智能(Artificial Intelligence,AI)技术赋能海关实验室业务工作,提升检测效率和准确性,既“检得快”又“检得好”,成为亟待解决的问题。AI大模型以其强大的数据处理能力和学习能力,在海关实验室的“数智化”建设中发挥重要作用。本文旨在探索AI大模型在海关实验室垂直领域中的落地应用,研究DeepSeek[1]等大模型本地化部署和本地知识库建设的技术和实施方案,提升AI在数据共享和开发应用中的作用和影响。
1 引入AI 大模型技术的必要性及可行性分析
1.1 引入AI大模型技术的必要性
AI大模型的出现为海关实验室改革检测模式提供了新路径。AI大模型凭借强大的数据处理能力,能够迅速整合并剖析海量的海关业务知识库,深度挖掘其中隐藏的潜在规律,为优化检测流程、精准预测风险提供坚实可靠的数据依据。同时,AI大模型可以在部分流程中取代人工操作,有效释放人力,减少人工干预的出错风险,进一步提升整体工作效率。
1.2 引入AI大模型技术的可行性
从技术发展角度看,当下 AI 技术迭代迅速,开源资源丰富,能依据海关实验室不同业务需求,快速搭建并完善模型。在安全性方面,海关实验室对数据安全与隐私保护要求极高,本地化部署可有效规避数据泄露、数据污染及跨互联网传输风险[2-3],而 DeepSeek、Qwen 等大模型的开源,则为本地化部署提供了技术基础。就实验室自身条件来讲,海关实验室信息化力量较强的技术机构,拥有一定软硬件资源及专业技术人员,具备与专业团队合作实施本地部署的综合实力。因此,DeepSeek 等大模型在海关实验室本地化部署具有切实的技术可行性。
2 海关实验室引入AI大模型的科学路径
2.1 国内外AI大模型应用现状
在国内,伴随着AI大模型技术的蓬勃发展,其在海关领域的应用已然从理论研讨迈向实际应用,部分海关已开始部署以 DeepSeek 等为代表的国产化开源大模型所构建的智能体。在国外,欧美等国家则更多采用GPT-4、Claude等模型。
在中国海关的实验室建设中,选用经过国产化的开源大模型优势明显。一方面,国产化开源模型在数据安全和隐私保护方面更具可靠性,能够更好地适应海关实验室业务需求和监管要求;另一方面,以 DeepSeek 为代表的国产大模型提供多种蒸馏规格,在有效减少算力资源占用的同时,性能表现出色,展现出较强的竞争力与实用性。
针对实验室具体开展的检测业务,所配合使用推理模型、语言模型、多模态模型等多种类型的模型发挥着关键作用。推理模型可分析复杂检测数据和业务流程,助力工作人员快速识别潜在问题和风险点;语言模型能高效检索文本信息,提供准确的检测标准、法规依据等知识支持;多模态模型主要用于图像解析和结构化数据处理,能精准解析海关实验室的检测图像数据,并将其转化为结构化数据以便分析利用。通过科学合理选择和应用不同类型的人工智能模型,海关实验室能够显著提升其检测效率、准确性和智能化水平,从而更好地应对日益复杂的海关监管任务和挑战。
2.2 对应措施
2.2.1 缩短检测周期
为更好地缓解检测任务压力,可以通过构建知识库来缩短检测周期。相关人员可组织专家团队共同打造涵盖海关实验室相关标准法规、资质能力、仪器设备信息的知识库。同时,借助AI大模型可高效检索并分析知识库内容,为实验室的质量体系建设、标准化管理和设备管理提供有力支持。工作人员在检测过程中遇到问题时,可迅速从知识库获取准确信息,减少分析时间,提升检测效率。
通过借助AI大模型分析样品信息、检测项目和检测结果数据,精准识别检测流程中的冗余环节和潜在问题,提出针对性优化建议,实现检测结果精准评估。例如,模型可根据样品特征自动推荐合适检测方法或智能生成检测方案,避免重复检测操作,缩短检测周期。
2.2.2 增强风险预警和精准监管能力
AI大模型整合海关实验室的多源数据,通过学习历史数据和监测实时数据进行深度分析,挖掘数据间潜在关联和风险规律,构建风险预测与告警模型,可进一步提升智能化水平。例如,关联分析样品信息、检测数据、样品来源等数据,及时发现潜在风险点,提高海关的风险预警能力和监管的精准性和有效性。
2.2.3 提高检测流程效率和准确性
可建立客户信息和检测周期时长的知识库,利用AI大模型来分析客户历史信息和检测需求,从而自动分配检测任务和安排检测时间,优化客户服务流程。同时,自动审核和生成检测报告,减少人工干预,缩短检测周期。
2.2.4 辅助海关执法决策
实验室可尝试利用AI技术辅助海关监管执法。AI大模型基于大量出口管制文件,找出海关出口货物监管等执法要求,建立知识库。运用模型、提示词和工作流等,对如 X 光光谱分析仪的检测报告进行分析,为海关执法提供辅助决策信息,降低人工判断误差和不确定性。
3 大模型本地化部署技术实践
以下从AI大模型本地化部署的技术选型、部署步骤以及部署过程中的综合考虑因素三个方面进行探讨。
3.1 技术选型
基于研究探索和实践验证,本文提出了一套完整的本地化部署技术路线,具体方案选型有以下几个方面:(1)部署方式,基于海关技术机构数据安全性和业务特点,在互联网部署和本地部署中选择本地部署,脱敏数据可在各互联网大模型平台进行技术验证测试,用于技术路径选择和快速迭代开发研究;(2)在平台、模型和软件方面,优先选择已开源的国产化平台、模型和软件;(3)操作系统方面,综合安全性、性能要求、开源和兼容性等因素,考虑选择Linux系统;(4)大模型部署框架,对比轻量级部署框架和高性能推理加速框架,基于性能考量,优先选择高性能推理加速框架vLLM;(5)大模型方面,对比 DeepSeek 和Qwen 等现有的开源大模型后,鉴于本地化部署的资源限制以及满足绝大部分业务场景的需求,本阶段暂时选用 DeepSeek蒸馏版本推理模型和Qwen普通参数规模的语言模型;(6)工具软件方面,经过对比Chatbox、Page Assist、Cherry Studio、AnythingLLM、Open WebUI、Coze、Dify、RAGFlow、FastGPT[4]等后,工作流和知识库软件选择 FastGPT,同时选用分布式推理框架 Xinference 部署国产化索引模型和重排序模型。
3.2 部署步骤
基于上述方案和现有的硬件资源,对大模型与AI应用平台进行部署。在装有显卡的物理机上,搭建vLLM部署框架,下载DeepSeek推理模型和Qwen语言模型,通过vLLM框架合理分配显卡运行2个大模型;在一台虚拟机上搭建Xinference分布式推理框架后,可在Xinference平台上拉取索引模型和重排序模型并运行;在另一台虚拟机上安装搭建Docker环境,拉取FastGPT镜像并启动相关容器服务。完成上述操作后,可登录FastGPT平台,配置上述已部署的模型。针对实验室业务,优先选择实验室检测相关标准、实验室资质能力作为知识库基础数据,文件格式以PDF、DOC、XLS等最常用的格式化文件为主。将实验室检测报告、实验室仪器设备检测结果原始记录作为用户端输入。使用FastGPT搭建知识库,利用工作台创建个性化工作流,创建实验室应用相关智能体。
3.3 大模型本地部署的综合考虑因素
在实践探索中发现,搭建AI大模型需要综合考虑以下几个关键因素:
其一,从硬件资源角度来看,显卡、虚拟机的CPU与内存、储存、物理机的显存以及跨网数据传输效率等方面,需要关注资源数量与性能瓶颈问题[5]。
其二,操作系统的选择与应用极为关键。以Ubuntu为代表的Linux系统,在命令操作、相关软件部署以及参数设置等方面,对实施人员的技术深度、广度和实际操作经验有着较高要求。
其三,在大模型优化方面,当前的Qwen语言模型仍存在一定的能力提升空间。若硬件资源条件允许,可替换较大参数规模的模型,同时关注版本迭代情况,及时更新至如Qwen3这样的最新版本;对于DeepSeek推理模型,当硬件资源充足时,可考虑升级至满血版本,以进一步优化模型性能。
其四,软件和数据的处理与优化不容忽视。需要着力优化FastGPT知识库的文件格式兼容性以及数据加工处理流程,切实解决扫描版PDF标准文件的识别难题、PDF格式转码为DOC文件时内容错乱的问题,以及索引模型因分块大小设置不当导致的知识库内容检索错漏等系列问题。
此外,还可通过调用RagFlow(基于深度文档理解的开源RAG引擎)等外部知识库来丰富数据来源与处理能力。在业务层面,组建各领域专家队伍,收集整理国家法律法规信息、各部委与海关业务相关文件、海关内部相关业务管理规范性文件、海关检验检测机构的相关标准信息,并进行分层分类,也能进一步减轻大模型负担,提升检索准确率和速度。
4 实验室大模型“数智化”场景应用阶段性成效
4.1 阶段性成效
在广州海关技术中心,DeepSeek等大模型的本地化部署、知识库、工作流创建及智能体应用等方面,探索出了能落地实施的可行性技术路线。针对实验室检测数据、仪器设备检测原始记录、实验室资质能力、实验室相关标准等典型应用场景,大模型人工智能辅助判断已有成功测试案例。
以一份实验室检测数据为例,样品活青蟹有5个检测项目,其中汞、镉、砷3个检测项目需要按照指定的GB 5009.268—2016《食品安全国家标准 食品中多元素的测定》[6]检测方法进行实验室检测,双氟沙星检测项目要根据原农业部第1077号公告中的检测方法检测,磺胺喹沙啉要按照GB/T 21316—2007《动物源性食品中磺胺类药物残留量的测定 液相色谱-质谱/质谱法》[7]进行检测。实验室需按要求出具检测结果并标注检测低限和结果单位,海关口岸工作人员可依据相关文件进行判断后确定是否通关放行。
在传统模式下,针对汞、镉、砷的检测项目,检测人员需依据最新版的国标GB 2762—2022《食品安全国家标准 食品中污染物限量》[8]进行检测结果判定并输出检测结论。本案例通过设计定制化 AI 工作流,取代传统人工操作,进一步提高效率、降低差错率,更好地满足海关实验室高效精准检测的需求。
在构建 FastGPT 集成知识库和大模型的工作流中,选用本地部署的 DeepSeek 推理模型用于本地知识库内容之外的补充,并对知识库输出结果数据进行交叉验证;同时配置 FastGPT 语言模型、知识库和提示词,选择 Qwen语言模型,以准确识别知识库内容,尽量避免推理模型出现幻觉问题。基于上述工作流,AI大模型辅助完成标准知识查阅、限量判定、结论复核、验证及输出等原需人工干预的步骤,显著提升海关实验室检测效率与精准度,提供智能化支持。
在验证环节,将国家标准GB 2762—2022的PDF文件作为知识库文件导入FastGPT,从目前应用效果来看,FastGPT对于双氟沙星和磺胺喹沙啉两个检测项目的“检测低限”和“单位”字段数据识别还存在一些问题(检测低限应为:定量限2、定量限10),后续还需要调整,其他检测项目和关键字段都识别正确。
对于双氟沙星和磺胺喹沙啉的检测项目,按照提示词和工作流设定,当前知识库只导入了GB 2762—2022的PDF格式文件用于判定汞、镉、砷3个检测项目,知识库判定结论两个都为“无法判断”是准确的。对照知识库内容的限量值,汞、镉、砷3个检测项目判定合格也是准确的。经过DeepSeek的数据交叉验证,知识库与本地DeepSeek推理模型结论一致。
在当前基于研究和技术分享设计的案例中,还有三点需要继续优化完善。一是DeepSeek推理模型,在检测结果数据中双氟沙星和磺胺喹沙啉检测结果为“未检出”时应判定为“合格”,而不是无法判断。二是本地知识库,需要充实与原农业部第1077号公告和GB/T 21316—2007中检测方法对应的判定标准,这项工作需要海关各业务条线对应主管部门的专家参与知识库构建。三是DeepSeek当前版本为蒸馏版的推理模型,需要本地化部署DeepSeek满血版推理模型或通义千问QwQ推理模型进行数据准确性验证。
综上所述,案例中实验室大模型“数智化”场景应用已经取得阶段性成效,后续还可以在工作效率提升、数据处理能力增强、服务质量改善等方面发挥更大作用。
5 未来优化方向及展望
未来,AI大模型在海关实验室“数智化”建设中将有更广泛的应用。随着技术进步和团队能力提升,建议在如下4个方向上进行深入研究与拓展。
5.1 模型幻觉问题应对思路探索
通过构建和持续完善海关业务知识库,结合检索增强生成(Retrieval-Augmented Generation,RAG)技术[9]调用权威数据,减少模型对训练数据的依赖;在现有推理模型和语言模型的基础上,不断优化架构和训练方法,适时引入多个新版本模型进行升级迭代和交叉验证,充分发挥本地部署的AI大模型自身能力,提高输入数据和知识库文件的利用效率,应对模型幻觉问题,提高模型的辅助决策能力;引入新硬件资源支持,增强本地部署能力,以提供充足计算资源,确保模型训练和推理过程的稳定高效,进而提升结果的准确性和稳定性。
5.2 多模态融合与智能交互
在文本输入的基础上引入语音识别功能,支持中文及其他语种自然语言输入与识别,支持录音文件识别,提升信息采集效率;利用图像识别技术,解决扫描文件和照片等文件的识别问题,提高光学字符识别(Optical Character Recognition,OCR)精准度,同时拓展视频文件及非格式化或半格式化文件识别的能力;整合语音、图像、视频等多种模态数据,实现数据互补,提升整体业务处理的智能化水平和效率。
5.3 智能决策与风险预测
基于大数据分析与AI大模型,为海关业务提供智能决策支持,如贸易趋势分析、风险管理等,辅助智慧海关相关条线业务场景的科学决策;利用AI技术对海关业务数据进行实时监测与分析,提高业务风险早期预警与防范能力,提升海关风险管理的主动性和有效性。
5.4 构建辅助AI大模型的微服务架构
传统AI大模型架构因模型数据无法及时更新,存在数据滞后问题,在应对动态数据、跨系统协作、高并发请求时表现不佳,限制了AI服务的效率、灵活性和准确性。融合模型上下文协议(Model Context Protocol,MCP)与网络应用程序编程接口(Representational State Transfer Application Programming Interface,RESTful API)的微服务架构[10-11]可搭建高效安全的交互桥梁。该架构可通过MCP与RESTful API模块化设计,为大模型集成外部服务工具和接口,整合分散数据资源,打破数据孤岛,实现数据实时交互与无缝流动,进而提升AI大模型性能和准确性。同时,借助MCP服务,大模型可突破浏览器限制,自主执行用户任务,从而将语言生成能力转化为生产力,提升智能化与自动化水平,例如支持本地文件系统操作、本地浏览器、本地应用以及远程MCP服务的调用等。在安全防护方面,通过对RESTful API和MCP服务进行安全封装,实施严格访问控制策略,保障数据传输与处理的安全性和完整性,筑牢AI服务的安全防线,如图1所示。
6 结语
AI大模型在海关实验室“数智化”建设中的应用,不仅能够提升海关实验室的工作效率和质量,还能够为海关监管提供强有力的技术支持。通过本地化部署DeepSeek等大模型和构建本地知识库,可以提升实验室数据共享、数据分析和辅助决策能力,推动海关实验室向更加自动化、智能化和智慧化的方向发展。未来,随着技术的不断进步和应用的深入,智慧实验室将更好地服务于全球贸易,为辅助海关监管技术作出更大贡献。
参考文献
[1]刘海军, 温赞玲. 深度求索DeepSeek:人工智能、技术创新与新质生产力[J/OL]. 当代经济管理, (2025-01-13)[2025-04-25]. http://kns.cnki.net/kcms/detail/13.1356.F.20250327.1530.003.html.
[2]刘金瑞. 生成式人工智能大模型的新型风险与规制框架[J]. 行政法学研究, 2024(2): 17-32.
[3]姜毅, 杨勇, 印佳丽, 等. 大语言模型安全与隐私风险综述[J/OL]. 计算机研究与发展, (2025-01-41)[2025-04-25]. http://kns.cnki.net/kcms/detail/11.1777.TP.20250305.1350.023.html.
[4] Wallfacer Lab, FastGPT[CP]. https://github.com/labring/FastGPT/, 2025.
[5]张慧敏. DeepSeek-R1是怎样炼成的?[J]. 深圳大学学报(理工版), 2025, 42(2): 226-232.
[6] GB 5009.268—2016. 食品安全国家标准 食品中多元素的测定[S]. 北京: 中国标准出版社, 2016.
[7] GB/T 21316—2007 动物源性食品中磺胺类药物残留量的测定 液相色谱-质谱/质谱法[S]. 北京: 中国标准出版社, 2007.
[8] GB 2762—2022 食品安全国家标准 食品中污染物限量[S]. 北京: 中国标准出版社, 2022
[9]赵静, 汤文玉, 霍钰, 等. 大模型检索增强生成(RAG)技术浅析[J]. 中国信息化, 2024(10): 71-72+70.
[10]陈政, 吴骏, 马方舟. 基于微服务架构的应用开发研究[J]. 科技资讯, 2024, 22(24): 24-26.
[11]肖斌, 王永峰. 一种高效微服务应用开发平台架构设计[J]. 中国科技信息, 2023(2): 96-98.
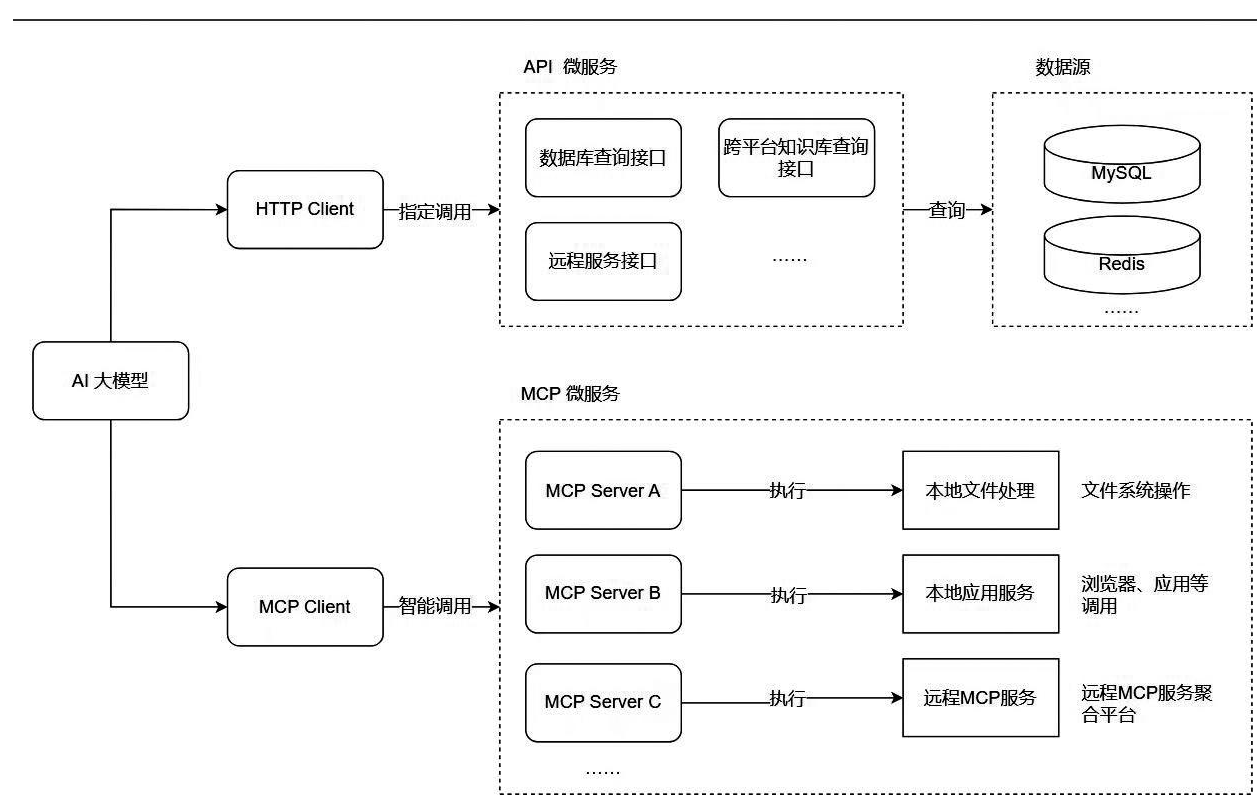
图1 集成 MCP、RESTful API 微服务架构的 AI 大模型
Fig.1 AI large-models integrated with MCP and RESTful API microservices architecture
