





CopyRight 2009-2020 © All Rights Reserved.版权所有: 中国海关未经授权禁止复制或建立镜像

大模型在海关统计工作中的应用研究
作者:杜琳美 吕涛 毕滔 陈衎
杜琳美 吕涛 毕滔 陈衎
摘 要 大模型因其优秀的交互性和通用性已广泛应用于诸多领域。本文从大模型在政务领域的研究进展和应用情况出发,结合海关统计信息系统在数据规模激增、用户友好交互、实时决策需求等方面的挑战,系统探讨了大模型在数据采集、智能交互和智能预测等场景的应用潜力。另外,分析了大模型在海关统计工作中实际应用时面临的挑战并给出对策建议。随着大模型技术的持续优化,其在海关统计中的应用将推动数据治理效能的全面提升,为海关统计工作提供更强技术支撑。
关键词 大模型;海关统计;人工智能;数字政府
Research on the Application of Large Models
in Customs Statistics
DU Lin-Mei 1 LYU Tao 1 BI Tao 1 CHEN Kan 1
Abstract Large-scale AI models have been extensively deployed across multiple disciplines owing to their superior interactivity and cross-domainadaptability.This paper examines the research advancements and implementation cases of large-scale models in government affairs. To addressing critical challenges in information system for customs statistics, including explosive data growth, user-friendly interactionandtime-sensitivedecision-makingrequirements, it conducts a methodological investigation into the application prospects of these models across key scenarios: automated data acquisition, intelligent human-computer collaborationand data-driven predictive modeling. Furthermore, the paper identifies implementation barriers specific to customs statistical systems and formulates evidence-based mitigation strategies. With the continuous optimization of large-scale model technology, its application in customs statistics will promote the overall improvement of data governance efficiency and provide stronger technical support for customs statistics work.
Keywords large model; customs statistics; artificial intelligence; digital government
随着全球贸易蓬勃发展与数字化进程加速演进,海关作为国家进出境监督管理机关,积累了海量数据。海关数据来源广泛,包括报关单申报数据、企业备案信息、物流数据、跨境电商平台数据等。对贸易数据进行高效精准的统计分析,能够准确反映外贸形势和经济运行状况,为国家经贸政策制定提供重要依据。传统的数据管理方法难以满足快速、精准、智能的监管与决策需求。大模型作为人工智能领域的突破性技术,凭借其强大的数据处理能力、复杂模式识别和深度语义理解等特性,为海关统计领域带来了新的发展契机。
如何发挥大模型在海关统计工作中的潜力,解决数据统计分析中的现实问题,是提升海关数据管理与数据服务能力的关键课题之一。本文系统分析了大模型技术在海关统计场景中的现实需求及创新应用场景,探讨大模型在提升数据应用效能、便利统计工作、挖掘数据价值等方面的实际作用。同时,深入剖析大模型应用中的技术挑战,为海关统计工作与大模型融合应用提供参考。
1 大模型技术
1.1 大模型技术的理论基础
大模型(Large Model)是指基于海量数据训练、具有极大参数规模的深度神经网络模型。大模型是大语言模型(Large Language Model,LLM)概念的延伸。从输入数据种类区分,大模型包含语言大模型、视觉大模型和多模态大模型等。如今流行的大模型多数基于Transformer框架[1]。Transformer框架基本结构如下。
1.1.1 自注意力层
自注意力(Self-attention)层[1]通过计算输入序列中词与词相关性,动态分配权重,具有发掘长输入序列上下文关联性的能力。自注意力核心原理表达如下:
(1)
式(1)中,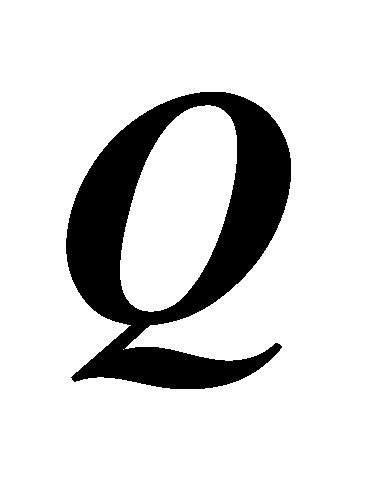 、
、 、
、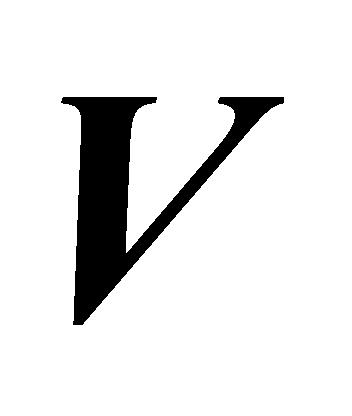 指输入序列经分词(Tokenize)、嵌入(Embedding)、线性变换后形成的矩阵。Softmax函数为归一化指数函数。
指输入序列经分词(Tokenize)、嵌入(Embedding)、线性变换后形成的矩阵。Softmax函数为归一化指数函数。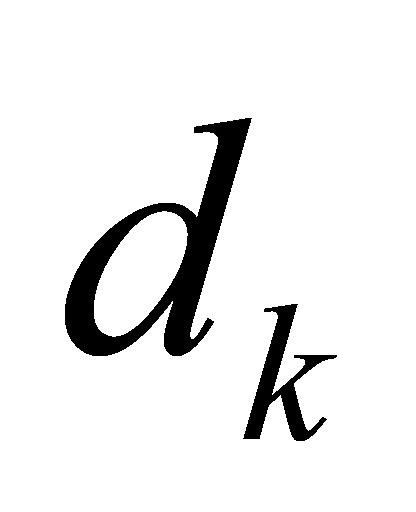 为矩阵
为矩阵 中键向量的维数,除以
中键向量的维数,除以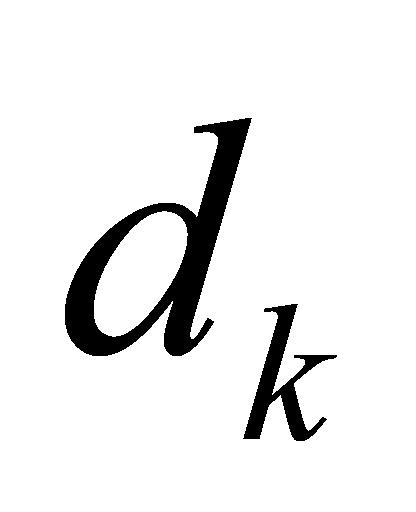 可以缓解梯度消失问题,提升计算稳定性。
可以缓解梯度消失问题,提升计算稳定性。
1.1.2 全连接前馈层
全连接前馈(Fully-connected Feed-forward)层是Transformer框架中的“海马体”,负责记忆模型预训练文本的语义模式,提供了类似键值对(Key-value Pair)的记忆功能,占据了模型约2/3的参数[2]。核心原理如下:
(2)
式(2)中,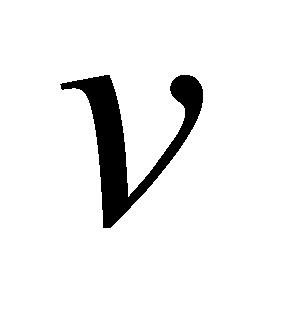 为输入向量,
为输入向量, 和
和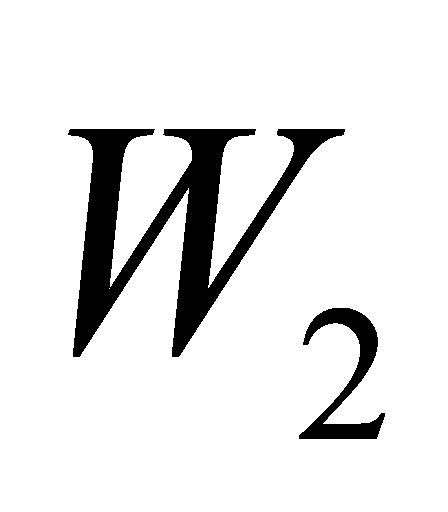 分别为第一层和第二层的权重参数,
分别为第一层和第二层的权重参数,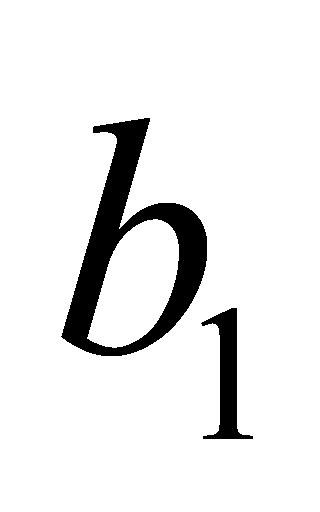 和
和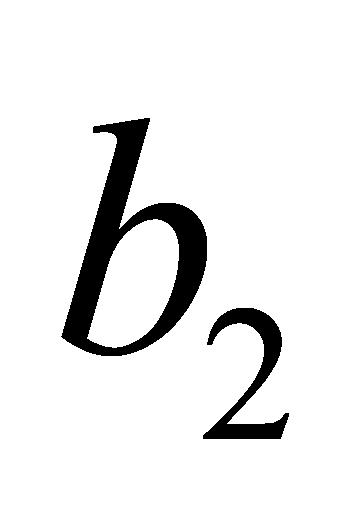 分别为第一层和第二层的偏置参数。第一层起到键的作用,第二层起到值的作用。
分别为第一层和第二层的偏置参数。第一层起到键的作用,第二层起到值的作用。
1.1.3 归一化层
归一化(Normalization)层负责计算输入数据的均值和标准差,并归一化输入数据。归一化层可以加速模型训练过程并提升模型性能[3]。核心操作如下:
(3)
式(3)中,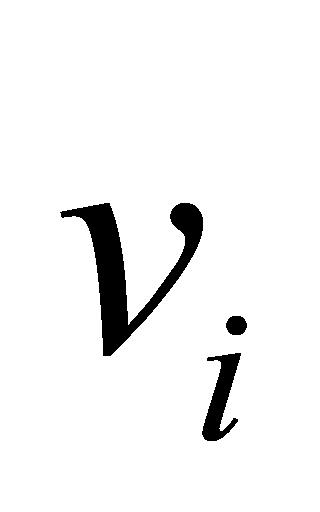 为输入向量,
为输入向量,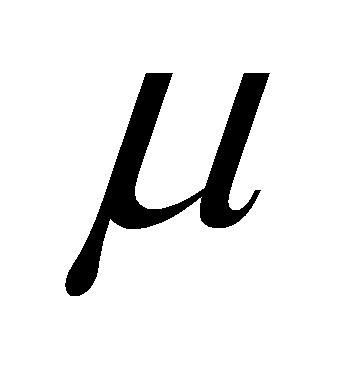 和
和 分别为
分别为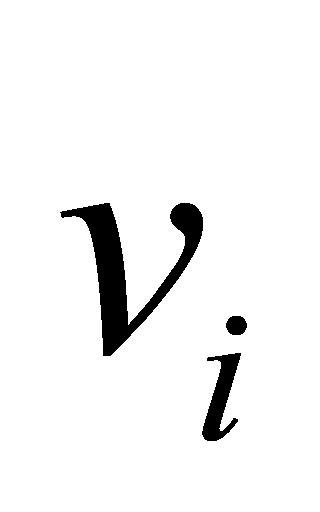 的均值和方差,
的均值和方差, 和
和 为可学习参数。
为可学习参数。
1.1.4 编码器与解码器
Transformer框架包含编码器和解码器两部分,两者均由自注意力层和全连接前馈层结合残差连接(Residual Connection)相互连接构建而成。两者的基本结构示意如图1所示。
基于Transformer框架,衍生出以下3种流行架构:(1)编码器(Encoder-Only)架构,专注于对输入序列进行理解分析,生成文本时往往会带来更多资源消耗,代表模型有GPT-1[4]、GPT-2[5]、GPT-3[6]、ChatGPT[7]等;(2)解码器(Decoder-Only)架构,采用自回归生成策略,每步生成仅考虑已生成文本,适合大量文本输出场景,代表模型有BERT[8]、RoBERTa[9]、ALBERT[10]等;(3)编码器-解码器(Encoder-Decoder)架构,模型参数规模相较于前两者往往更为庞大,一般在处理长序列输入时面临更大计算压力,同时处理复杂序列的能力更加强大,代表模型有T5[11]、BART[12]、DeepSeek等。
随着参数数量、训练数据或训练步骤的提升,模型解决特定问题的能力突然提升,这种现象称之为涌现能力(Emergent Ability)[13]。面对多步骤构成的复杂任务,当模型参数规模大到一定程度时,效果会急剧增长;而在模型规模小于某个临界值时,模型基本不具备任务解决能力。通过微调(Fine Tune)、提示词(Prompt)工程等方法,可以提升预训练通用大模型在特定场景下的应用效果。
1.2 大模型技术在政务领域的应用现状
我国大模型近年来发展迅猛,截至2025年3月31日,共有346款生成式人工智能服务在国家网信办完成备案;对于通过API接口或其他方式直接调用已备案模型能力的生成式人工智能应用或功能,共有159款生成式人工智功能在地方网信办完成登记[14]。2025年1月20日,DeepSeek-V3和DeepSeek-R1开源大模型的发布引发新一轮大模型应用热潮。2025年2月8日,深圳市龙岗区在政务外网信创环境首先完成DeepSeek-R1本地化部署[15]。根据各级政府官网公开消息,截至2025年3月,我国已有72个省级或市级政府部门完成DeepSeek模型私有化部署[16]。在政务领域,大模型因其优秀的交互性、强大的文本及图像处理能力,在政民互动、政务办公、行政执法、政策分析等等方面能够发挥独特作用(图2)。
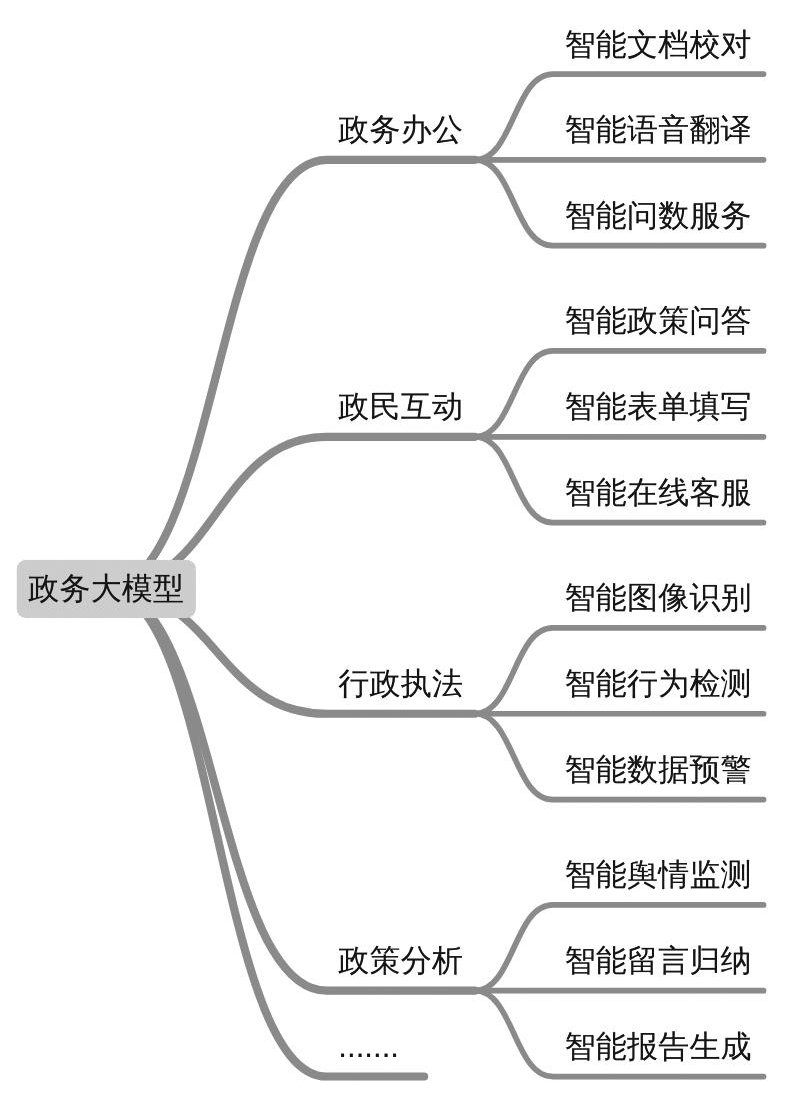
图2 大模型在政务领域的部分应用场景
Fig.2 Application scenarios of large models in the government sector
2023年7月,《生成式人工智能服务管理暂行办法》印发,鼓励生成式人工智能在各行业和领域的创新应用,探索应用场景,构建应用生态体系。近年来,多地不断完善大模型支持政策。仅在2024年7月,《北京市推动“人工智能+”行动计划(2024—2025年)》《上海市促进工业服务业赋能产业升级行动方案(2024—2027年)》《深圳市加快打造人工智能先锋城市行动方案》《支持人工智能全产业链高质量发展的若干措施》(杭州市人民政府)四地政策文件印发实施。政策不断加力完善,从算力基础设施建设、模型生态打造、人才队伍支撑等多维度提供配套支持。
2 海关统计工作的现状和需求
根据《中华人民共和国海关统计条例》规定,海关统计是海关依法对进出口货物贸易的统计,是国民经济统计的组成部分。海关统计是国家宏观经济调控和贸易政策制定的重要支撑。当前,从报关单等数据的采集和录入到统计数据的分析计算再到统计报表和简报的生成已实现自动化。但多变复杂的国际贸易形势对海关统计决策支撑能力的灵活性和即时性提出了更高要求。
2.1 海关统计工作现状
2.1.1 海关统计数据采集与分析
海关积极应用先进信息技术,通过电子化报关系统和数据抓取技术,初步实现了统计数据采集的智能化和自动化。在数据处理环节,运用自动化算法和规则引擎对采集数据进行初步筛选,去除冗余数据、错误数据和识别异常录入。数据安全与隐私保护方面,海关在数据采集、传输和存储过程中实施加密、权限控制和日志记录等多重保护措施。在跨部门数据共享方面,海关建立了统一的数据管理机制,确保数据交换的规范性,实现全流程数据追溯和监管。
2.1.2 海关统计报表的生成与发布
统计报表作为海关统计信息的主要展示形式,直观反映进出口贸易的基本运行状况,是经贸措施制定和调整的重要依据。海关统计报表种类繁多,各指标之间相互关联且数据基数庞大,发布的时效性和准确性受到社会公众关注。目前,海关统计报表主要依靠定期数据汇总和人工调整设计,在数据更新、信息交互和数据展示方面还有提升空间。现有海关统计报表生成通过电子化报关系统和数据采集平台获取基础数据,在完成数据清洗和标准化后,形成中间数据库表,在此基础上计算并校验进出口额、同环比等统计指标,最后根据报表模板生成固定格式报表。报表新增或调整基于海关业务人员和技术人员的大量沟通和共同操作。可视化、智能化的报表维护和定义方式能够便捷海关业务人员,减轻基层工作负担且提升报表时效性和灵活性。
2.2 海关统计工作需求
随着跨境电商、离岸贸易、新型供应链模式的快速发展以及国际贸易形势的快速变化,海关贸易数据的体量、种类和实时性要求均大幅提高。因此,如何在保证数据质量和安全的前提下,实现海关统计数据的高效治理和深度应用,成为当前亟待解决的核心问题。
(1)构建更加智能的数据检控机制,提升统计原始资料质量。统计原始资料直接关系到统计数据的准确性。构建基于大模型的智能模型组,发掘可能存在的单据填制不规范、虚报出口骗取退税、瞒报单价或原产地逃税等行为,提升数据准确度。
(2)构建更加友好的数据交互服务,便利社会公众和业务人员取数用数。在保证数据查询准确性的基础上,提供智能化问数服务、智能化查询服务、智能化指标解答服务、智能化组合报表生成服务,提供更高质量统计数据公共服务。
(3)构建更加准确的预测预警系统,应对突发事件和异常波动。以多维度数据基础,搭建多样预测模型和情景分析框架,深入分析因果关系,揭示数据内在规律,支持即时决策和风险防控。在面对国际贸易摩擦、经济危机等外部冲击时模拟情景,评估各政策选项可能带来的影响,提供政策方案参考。
3 大模型在海关统计中的应用场景分析
3.1 数据质量检控
数据质量检控是指通过人工和技术手段,判定微观数据真实性,剔除虚假和无效数据,提升统计数据质量的行为。常见的数据质量检控手段使用3-sigma原则、四分位法等,逻辑预置于系统中,缺乏灵活性。
针对报关单等单据数据的特定风险场景,例如短期贸易量激增、新注册企业激增、物流兜转等,结合专家经验发掘数据特征,使用大模型构建智能模型组,开展风险识别工作。除了明确的风险场景,大模型还可以挖掘潜在的风险特征。通过对查获存在虚假贸易等行为企业和正常企业的贸易数据标注,结合监督学习等手段挖掘企业风险表征,为人工判别提供参考。
此外,结合大模型多模态能力,可以构建多数据来源的风险甄别模型。例如,构建港口集装箱-贸易量模型,对于非大宗散货的货物,贸易量与港口集装箱数正相关。使用大模型分析港口集装箱卫星照片变化与贸易量变动,预警两者的偏差情况,为进一步进行人工分析提供线索。基于不同来源的外部数据,可以辅助海关工作人员发现数据风险线索,更好地完成数据质量检控工作。
3.2 智能交互
传统的数据查询和报告报表生成维护方式难以满足用户对统计数据的多维交互和深度信息挖掘的需求。构建智能交互系统,将自然语言输入转化为结构化查询语句,把结果以指定形式输出,实现从数据检索到信息反馈的全流程自动化,有效帮助业务人员便捷快速地设计调整报表,进一步提高统计数据的利用效率和决策支持能力。
3.2.1 动态可视化的交互
动态可视化系统支持折线图、柱状图、饼状图、热力图、树状图以及网络关系图等多种图形方式,全面反映海关统计数据在时空维度上的变化。决策者通过拖拽、缩放、过滤等交互操作,自由组合不同数据视角,从宏观到微观层面对数据进行深入剖析[17]。例如,当某地区的进出口数据出现突变时,系统自动生成预警提示,提供数据信息细节和历史对比,协助决策者迅速定位异常原因。将大模型技术和BI(Business Intelligence)设计工具相结合,可以提升报表定义维护方法的灵活性。业务人员通过BI工具绘制报表模板,通过行索引和列索引,给出行列交叉点数据的采集方式和过滤条件。大模型提供BI使用建议和结果分析等辅助功能,进一步提升报表的维护操作直观性和准确度。
3.2.2 自然语言驱动的交互
传统数据查询工作需要海关业务人员掌握结构化查询语言(Structure Query Language,SQL),存在一定技术门槛。自然语言驱动的查询系统核心在于,将用户的自然语言输入转换为结构化查询语句,对接至数据库查询结果,提升信息检索效率。通过预训练和微调技术,大模型能够准确理解用户输入的查询需求,自动提取时间、地域、商品编码等关键要素,并将其转化为系统内部可识别的查询条件[4]。即使用户不具备专业的计算机知识,也能够直接通过日常语言获取所需数据和分析报告。例如,用户输入“2023年《区域全面经济伙伴关系协定》(RCEP)成员国对我国机电产品出口增长最快的3个国家的机电产品出口量”,系统从海关系统数据库和知识库中提取出信息,由大模型构建图表展示和生成报告。用户还可以就查询结果提出补充问题或进一步探讨数据背后的意义,模型通过语义理解和关联分析,提供详细解答和相关数据补充,实现人机交互无缝衔接[5]。结合大模型的报表生成,预计将原有的报表生成和调整流程由2个月左右压缩至数天,便利相关工作的开展。
3.3 智能预测
现有的传统分析预测模型虽然在一定程度上能够捕捉数据的周期性和趋势性,但面对多因素干扰、突发事件的影响时,其预测精度存在一定不足。智能预测技术通过引入深度学习模型、Transformer架构以及先进的机器学习时间序列分析算法,能够对历史数据进行深度特征提取和融合建模,提供更为准确的预测。
3.3.1 基于大模型技术的时间序列预测
在国际贸易环境中,海关统计数据不仅具有海量性和多样性,而且受到经济、政治、市场波动等多重因素的影响,数据变化呈现出复杂时序特征。传统的时间序列分析方法,如自回归整合移动平均模型(Autoregressive Integrated Moving Average Model)、季节性自回归整合移动平均模型(Seasonal Autoregressive Integrated Moving Average Model)等,虽然在一定程度上能揭示数据的周期性和趋势性,但面对多因素交互、异常波动和非线性关系时,其预测效果往往受限。基于大模型的时间序列预测则通过深度学习、Transformer架构和长短期记忆网络(Long Short-Term Memory Network)等先进技术,对历史数据进行深度特征提取和模式识别,从而实现对贸易数据的更精准预测[18]。大模型技术能够自动学习和捕捉数据中的微妙变化和长期依赖关系,通过大规模并行计算和多层次特征融合,显著提高预测精度[19]。在模型训练过程中,采用深度神经网络结合Transformer架构,使得模型能够在捕捉短期波动的同时,有效识别长期趋势和季节性特征。与传统线性模型相比,基于大模型的时间序列预测不仅具备更高的容错性和适应性,还能自动调整模型参数,适应外部经济环境的动态变化。通过历史数据训练,模型可以识别出影响进出口总量、单价波动及贸易差额等指标的关键因素,并通过自注意力机制,提供更为细致和精准的预测结果[2]。基于大模型的时间序列预测系统支持结果解释和敏感性分析,通过可视化工具直观展示关键特征变量的影响权重和变化趋势,提供深层次数据解读。
3.3.2 融合因果分析的大模型决策支持
在多因素共同作用影响海关进出口数据的背景下,因果关系的挖掘成为预测系统中不可或缺的一环。传统的因果分析方法往往依赖于线性回归或结构方程模型,其在面对高维数据、多重共线性以及非线性关系时存在一定局限,而大模型技术通过融合深度学习、图神经网络以及强化学习算法,实现了对因果关系的更加全面和精准的捕捉[20]。首先,该技术能够通过对历史进出口数据和外部经济指标(如汇率波动、国际政治局势、国内经济政策调整等)进行特征提取,通过构建多维度的变量网络图,实现因果链条的全面梳理。大模型驱动的因果分析不仅在数据的多维度整合和变量关系的动态调整上表现突出,还具备自我修正的能力。利用先进的反事实分析方法,这种系统能够模拟在不同政策情境下各变量变化对进出口数据的影响,从而为政策制定提供量化依据和风险预警[21]。此外,模型还可以引入迁移学习和对抗训练技术,使得因果关系分析具有更高的稳健性和泛化能力,确保在面对新兴贸易形势时,依然能够提供稳定、可靠的决策建议。
4 面临的挑战与对策建议
4.1 模型输出结果问题
大模型的预测和推理能力依赖训练数据,如果模型训练使用的数据中存在噪声或错误信息,会干扰模型学习,导致产生模型幻觉或预测偏差。在海关贸易统计领域,数据误差或模型幻觉可能导致错误结果,误导外贸形势研判。目前海关已经建立了较为完善的数据管理体系,包括数据采集、清洗、预处理和验证,能够保障数据的时效性和完整性,但仍需有针对性地处理历史数据中的偏差和噪音,可以开展人工集中审核或利用第三方验证工具进行双重审核,减少数据问题对模型的影响。同时,在模型应用过程中,需建立多层次结果验证和人机协同机制,提升输出的可靠性。
4.2 数据安全问题
海关数据涉及企业商业秘密,大模型训练和推理时需要频繁调用这些数据。为确保数据安全,训练海关统计行业大模型时,在海关内网配置训练环境和导出数据,在数据安全可控的商业环境下进行训练,需要综合安全性和性价比进行选择。无论选择哪种方式,都需要制定在大模型训练环境下海关数据安全使用规范,明确数据出域管理要求,增强数据安全管控技术手段,采用先进加密技术,确保数据传输与存储的安全。
4.3 模型结果输出问题
大模型输出结果可解释性差,这在监管决策对可靠性要求极高的情况下是一个关键问题。大模型的“黑箱”性质要求使用者自行验证输出结果正确性和合理性。在模型设计中,结合基于微调和提示词等技术,确保大模型输出符合业务逻辑,降低模型输出的不确定性。另外,人机协同机制是不可或缺的。现阶段大模型仅可作为辅助工具,输出结果只可作为参考,高风险决策必须由人工进行复核和校正。在关键领域应用大模型,配备专业的风控和合规团队,核实大模型的判断,确保决策的合理性是十分必要的。
5 结语
大模型自从2017年Transformer框架发布之后迎来了迅速发展的时期,模型的参数规模、处理和生成能力日新月异。目前大模型已经在政务领域得到了广泛应用,包括但不限于文档校对、语言翻译、行为识别、政策问答等。
根据海关统计工作的实际需要,通过模型预训练、微调、蒸馏、迁移学习等手段,通过大模型与现有系统和人工智能模型集成,可以在数据质量管理、数据查询与交互、数据预测与决策支持等方面提供支撑,提升工作成效。值得注意的是,在海关统计应用大模型的过程中,同样应该注意引入大模型可能带来的可靠性、安全性和稳定性等方面的问题。海关统计工作因其特殊性,对模型要求更严格,在模型参数规模提升的同时,平衡模型性能和成本同样是重要课题。随着大模型技术的持续优化,其在海关统计中的应用将推动数据治理效能的全面提升,为贸易政策制定提供更精准、更快速、更智能的决策支持。
参考文献
[1] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C/OL]//Advances in Neural Information Processing Systems 30 (NIPS 2017). Red Hook: Curran Associates, Inc., 2017: 5998-6008 (2017-06) [2025-05-08]. https://papers.nips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf.
[2] GEVA M, SCHUSTER R, BERANT J, et al. Transformer feed-forward layers are key-value memories [EB/OL]. (2020-12-29) [2023-10-01]. arXiv:2012.14913. https://arxiv.org/abs/2012.14913.
[3] BA J L, KIROS J R, HINTON G E. Layer normalization [EB/OL]. (2016-07-21) [2025-05-08]. arXiv:1607.06450. https://arxiv.org/abs/1607.06450.
[4] Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training [R/OL]. San Francisco: OpenAI(2018-06-11) [2023-10-01]. https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf.
[5] RADFORD A, WU J, CHILD R, et al. Language models are unsupervised multitask learners [EB/OL]. San Francisco: OpenAI, 2019 (2020-06-01) [2025-03-08]. https://storage.prod.researchhub.com/uploads/papers/2020/06/01/language-models.pdf.f.
[6] Brown T, Mann B, Ryder N, et al. Language models are few-shot learners[J]. Advances in neural information processing systems, 2020, 33: 1877-1901.
[7] Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. Advances in neural information processing systems, 2022, 35: 27730-27744.
[8] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[C]//Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 2019: 4171-4186.
[9] LIU Y, OTT M, GOYAL N, et al. ROBERTA: A robustly optimized BERT pretraining approach [EB/OL]. (2019-07-26) [2025-05-08]. arXiv:1907.11692. https://arxiv.org/abs/1907.11692.
[10] LAN Z, CHEN M, GOODMAN S, et al. ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations [EB/OL]. (2019-09-26) [2025-05-08]. arXiv:1909.11942. https://arxiv.org/abs/1909.11942.
[11] Raffel C, Shazeer N, Roberts A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer[J]. Journal of machine learning research, 2020, 21(140): 1-67.
[12] LEWIS M, LIU Y, GOYAL N, et al. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension [EB/OL]. (2019-10-29) [2025-05-08]. arXiv:1910.13461. https://arxiv.org/abs/1910.13461.
[13] WEI J, TAY Y, BOMMASANI R, et al. Emergent abilities of large language models [EB/OL]. (2022-06-15) [2025-05-08]. arXiv:2206.07682. https://arxiv.org/abs/2206.07682.
[14]国家互联网信息办公室. 国家互联网信息办公室关于发布生成式人工智能服务已备案信息的公告 (2025年1月至3月)[EB/OL]. (2025-04-08)[2025-05-21]. https://www.cac.gov.cn/2025-04/08/c_1745817775881843.htm.
[15]龙岗政府在线. DeepSeek赋能!龙岗开启智慧政务新篇章[EB/OL]. (2025-02-11) [2025-03-10]. https://www.lg.gov.cn/xxgk/xwzx/zwdt/content/post_11994841.html.
[16]至顶网. “DeepSeek+政务”全国部署图表: 多地政府加快AI+政务落地进程[EB/OL]. (2025-03-11) [2025-03-18]. https://insights.zhiding.cn/2025/0311/3164201.shtml.
[17] Wang Y, Wald I, Wu Q, et al. IEEE transactions on visualization and computer graphics[J]. IEEE transactions on visualization and computer graphics, 2019, 25(6): 2168-2180.
[18] Salinas D, Flunkert V, Gasthaus J, et al. DeepAR: Probabilistic forecasting with autoregressive recurrent networks[J]. International Journal of Forecasting, 2020, 36(3): 1181-1191.
[19] Lim B, Arık S Ö, Loeff N, et al. Temporal fusion transformers for interpretable multi-horizon time series forecasting[J]. International Journal of Forecasting, 2021, 37(4): 1748-1764.
[20] Shalit U, Johansson F D, Sontag D. Estimating individual treatment effect: generalization bounds and algorithms[C]. International conference on machine learning. PMLR, 2017: 3076-3085.
[21] LOUIZOS C, SHALIT U, MOOIJ J M, et al. Causal effect inference with deep latent-variable models [C/OL]//Advances in Neural Information Processing Systems 30 (NIPS 2017). Red Hook: Curran Associates, Inc., 2017: 6449-6459 (2017-06) [2025-05-08]. https://papers.nips.cc/paper_files/paper/2017/file/94b5bde6de888ddf9cde6748ad2523d1-Paper.pdf.
第一作者:杜琳美(1978—),女,汉族,贵州安顺人,硕士,副高级工程师,主要从事统计信息系统建设、数据安全管理工作,E-mail: dulinmei@163.com
1. 全国海关信息中心(全国海关电子通关中心) 北京 100005
1. National Information Center of GACC (General Administration of Customs of China), Beijing 100005
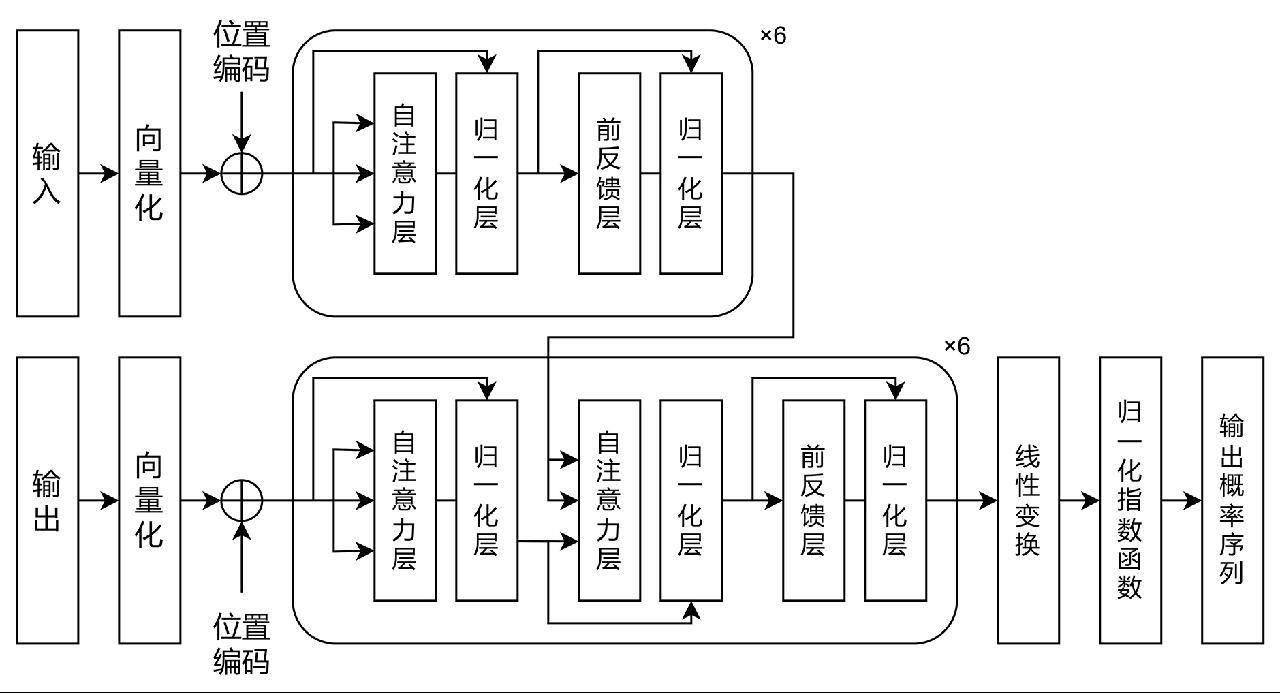
图1 Transformer框架中编码器和解码器的基本结构图[1]
Fig.1 Basic structure diagram of the encoder and decoder in the transformer framework[1]
