





CopyRight 2009-2020 © All Rights Reserved.版权所有: 中国海关未经授权禁止复制或建立镜像

光学字符识别技术研究及在海关监管中的应用
作者:孟庆铎 秦力 宗超飞
孟庆铎 秦力 宗超飞
摘 要 本文研究了基于深度学习的文本图像识别技术及其在相关行业中的应用现状,并构建了兽医卫生证书识别模型。研究结果表明,通过引入多维度质量评估与异常识别、形态学搜索模板匹配以及知识蒸馏模型优化等一系列算法改进措施,有效解决了大规模证书识别处理中的时效性和准确性问题,有助于海关实现证书的自动化审核,进而提升通关效率和管理水平。
关键词 深度学习;文本图像识别;兽医卫生证书;知识蒸馏
Research on OCR and Its Application in Customs Control
MENG Qing-Duo 1 QIN Li 1 ZONG Chao-Fei 2
Abstract This paper investigates deep learning-based text image recognition technology and its current applications in related industries, constructing a veterinary health certificate recognition model. By introducing a series of algorithmic improvements, including multi-dimensional quality assessment and anomaly recognition, morphological search template matching, and knowledge distillation model optimization, the issues of timeliness and accuracy in large-scale certificate recognition processing have been effectively addressed. This aids customs authorities in achieving automated certificate review, thereby enhancing clearance efficiency and management levels.
Keywords deep learning; text image recognition; veterinary health certificate; knowledge distillation
光学字符识别(Optical Character Recogni- tion,OCR)作为计算机视觉领域的一个重要研究方向,是一种将图像中的文字转换为可供计算机进一步处理的电子文本的技术。该技术可对图像中的像素进行特征提取与分析,并在此基础上使用字符识别方法获取其中的文字及信息。目前,OCR技术已在银行票据、车牌、证件等背景单一、文本整齐清晰的场景中得到广泛应用。
本文围绕海关业务,以兽医卫生证书为研究样本,通过研究基于深度学习的文本图像识别关键技术,自动提取兽医卫生证书中的关键文本信息并形成结构化数据,实现用“机器眼”代替人眼,为海关安全准入风险防控业务提供技术支撑。
1 光学字符识别技术概述
1.1 光学字符识别的发展
光学字符识别的概念最早于1929年由德国科学家Tausheck提出[1],随后美国科学家Handel也提出了文字识别的想法,但由于条件限制,这项技术并未被实现。20世纪50年代,随着计算机技术的发展,OCR开始进入实践阶段。早期研究集中于拉丁字母和数字的识别,例如,IBM等科技公司在20世纪50年代开始涉足OCR技术的研发,并推出了用于银行和金融行业的OCR系统,用来处理支票和票据。随着模式识别理论的发展,OCR技术开始向复杂文字体系延伸。IBM公司的工程师Casey和Nagy在1966年发表的首篇汉字识别相关的文章中[2],采用模板匹配方式实现了1000个印刷体汉字的识别。到20世纪90年代,LeNet5网络的提出在字符识别任务中取得了突破性进展,为后续深度学习在OCR领域的应用提供了重要参考。此后,随着深度学习的发展及识别网络和物体检测框架的不断优化,光学字符识别得到了长足发展,产生了一系列专用的文字检测及识别技术[3]。
1.2 光学字符识别技术
OCR技术的发展可以分为两个阶段:传统OCR技术和基于深度学习的OCR技术。
1.2.1 传统OCR技术
传统OCR技术通过将文本行的字符识别视为一个多标签任务学习过程,借助图像处理技术和相关的统计机器学习算法实现对图片文本内容的提取[4]。识别过程主要包括图像输入、图像预处理、版面分析、字符切割、字符识别等步骤。传统OCR技术对文字识别的准确率高度依赖图像的质量及文字的字体和布局,且识别过程未考虑上下文的语义关联信息,再加上其较多的处理流程及人工设计,使得该技术在处理较为复杂的文本图像时(如畸变或模糊不清),很难达到理想的识别效果。
1.2.2 基于深度学习的OCR技术
基于深度学习的OCR技术将文本图像识别分为文本检测和文本识别[5]两个主要步骤。其中,文本检测步骤主要用于定位文本的位置,文本识别步骤主要用于识别文本的具体内容。
(1)文本检测方法。基于深度学习的文本检测方法主要包括基于回归的方法和基于分割的方法[6]。基于回归的方法是在目标检测的方法上演变而来,首先预生成若干锚框,然后回归坐标和分类,最后经过非极大值抑制得到最终的检测结果,常见的算法主要有CTPN(Connectionist Text Proposal Network)、EAST(Efficient and Accuracy Scene Text)[7]等。基于分割的方法是将图像中的文字区域与背景区域进行分割,提取其中大的文字区域并进行检测。该类算法对于不规则形状的文本具有较好的检测效果。常见的算法主要有PSENet(Shape Robust Text Detection with Progressive Scale Expansion Network)、DBNet(Real-time Scene Text Detection with Differentiable Binarization)[8]等。
(2)文字识别方法。文字识别是对定位好的文字区域进行识别,主要解决的是将一串文字图片转录为对应字符的问题[9]。常用的方法主要有用于规则文字识别的基于CTC(Connectionist Temporal Classification)的方法、用于不规则文本识别的基于校正的方法和基于注意力(Attention)的方法。
2 模型构建
2.1 技术路线
兽医卫生证书以PDF格式存储,且可能存在图像表格比例失衡、图像倾斜过大、表格残缺不全等问题。本研究结合不同图像处理算法,同时参照PP-OCR框架对证书关键信息进行提取识别,具体技术路线如图1所示。

图1 兽医证书信息提取技术路线
Fig.1 Technical route for veterinary certificate information extraction
2.2 算法优化措施
2.2.1 基于结构化单证多维度质量评测与异常识别算法
本研究旨在提出一种全面考虑多个方面的单据质量评测与异常识别方法。该方法侧重评估图像的锐度、倾斜形变和干扰污染,这些因素对图像边缘清晰度、信息提取准确性和自动化系统性能至关重要。综合考虑这些关键因素,可以建立一个综合的单据质量评估模型,以自动判定单据图像的质量,并识别异常单据。该多维度评测方法,通过综合考量图像的关键维度,系统能够自动拒绝低质量图像,同时针对质量问题向用户提供精准反馈,从而提高提取结果的可靠性和准确性。
2.2.2 基于形态学搜索模板匹配算法
传统OCR文字识别方法对整张图像进行识别,耗时较长且包含大量无效信息,无法满足海关通关实时性需求。以兽医卫生证书为研究对象,本研究深入挖掘证书有效信息,发现其具有固定的模板。为提高OCR文字识别效率和准确性,本研究提出了一种基于形态学搜索的模板匹配方法,如图2所示。该方法首先通过轮廓检测定位有效信息区域,并利用自定义形态特征分布算子进行通道划分和特征匹配。通过基于岭回归的线拟合策略标记轮廓线,然后以类似方法搜索感兴趣区域的必要线分布并进行线校验。实现了感兴趣区域的精确分割,并将其送入后续OCR模块进行识别检测。
2.2.3 基于知识蒸馏的模型优化
文字识别是本系统的核心模块。由于在海关风险防控业务中涉及大并发量单据处理的场景,这要求模型具有快的推理速度以满足时效性。SVTR(Scene Text Recognition with a Single Visual Model)模型在精度具有竞争力的前提下,模型参数量更少,具有更快的推理速度,能够满足海关业务繁忙时高并发、数据量大的单据文字识别性能需求。
为应对海关场景高时效性、数据量大的特点,在实际训练和推理时,结合用于特征提取的MobileNetV1-Enhanced,它是一个多层的轻量级深度卷积网络,能够让网络在计算力较低的移动端运行并且保证网络的性能不会下降太多,可分离卷积代替传统卷积,大大减少模型参数,并提高了模型推理速度。
GTC(Global-to-local Transformer with CTC)是一种结合了Attention和CTC两种在文字识别中主流的方法。在训练时将两种方法结合起来对多种特征进行融合,能够获得更加准确、高效的模型。Attention只在训练时使用,而在推理时不会用到,因此也不会增加更多时间成本。其训练过程如图3所示。
将在大规模公开数据集上预训练的SVTR模型直接用于海关非结构化随附单据的文字识别,准确率很低,不能满足M2M间的高可靠、高置信度的需求。因此,考虑在预训练模型的基础上使用参数微调的方法对模型进行改进。相比于直接进行调优,使用知识蒸馏对模型的冗余参数压缩,能够改善模型复杂度。
在数据量足够大的情况下,通过合理构建网络模型的方式增加其参数量,可以显著改善模型性能,但是这又带来了模型复杂度急剧提升的问题。由于海关场景中需要面对大规模单据实时处理的情况,对模型的性能和处理时间都提出了较高的要求,大模型在实际场景中使用的成本较高,会耗费过多的软硬件资源。深度神经网络一般有较多的参数冗余,本文使用知识蒸馏方法对模型进行压缩,减小其参数量。知识蒸馏是指使用“教师模型”(Teacher Model)去指导“学生模型”(Student Model)学习特定任务,保证小模型在参数量不变的情况下,得到比较大的性能提升。在知识蒸馏任务中,衍生出了互学习的模型训练方法,使用两个完全相同的模型在训练的过程中互相监督,可以达到比单个模型训练更好的效果。蒸馏训练策略如图4所示。
文本识别问题可以看作是一个多分类问题,训练时字典中的字符个数可以看作分类数
,对于样本, = 1,2,...,n,其对应的标签为,i = 1,2,...,n。对于样本来说,每个种类m的概率为:
(1)
式(1)中,zm 表示网络的Softmax层的输出,预测概率最高类即为输出的字符。一般的多分类问题的损失函数被定义为预测值和标签之间的交叉熵损失L。
(2)
其中I被定义为:
(3)
传统的监督训练过程为图像输入到网络中进行前向传输,计算通过损失函数衡量预测与标签的差距反向传播。知识蒸馏是一种用于模型压缩和知识传递的技术,它通过将一个复杂的“教师模型”的知识转移到一个较小的“学生模型”上,以在计算资源有限的情况下保持较高的模型性能。知识蒸馏不仅可以用于模型压缩和加速训练,还可以用于提升模型的泛化能力和学习能力。通过知识蒸馏,可以利用“教师模型”的知识来辅助“学生模型”在小样本数据上进行训练,从而提高模型的泛化能力。
然而,两个相同的模型相互蒸馏则是在小样本情况下的一种新的探索和尝试。在这种方法中,两个模型(通常是相同结构的模型)同时充当“教师模型”和“学生模型”的角色,彼此交换知识,共同学习和提升。两个相同的模型共同训练和相互提炼来提高深度神经网络的性能,可以获得紧凑的网络,其性能优于传统知识蒸馏方法从强大网络中提炼出来的网络。
假设两个模型为和,它们的预测分别为和,利用KL散度(Kullback-Leibler Divergence)来衡量两个模型之间的分布差异,称为蒸馏互损失LDML(Distillation Mutual Loss),形式如下:
(4)
训练过程中,采用了CTC Loss和Attention Loss。通过引入一个特殊的空白标签来表示没有发生变化的时间步,并利用动态规划算法来寻找最可能的标签序列,CTC允许模型自动对齐输入和输出序列,无需人工标注。这种方法有效地提高了模型在处理序列预测任务时的性能和准确性。CTC模块在SVTR网络的FC层后计算CTC Loss,其输出为。Attention Module的引导,使模型从更强大的注意力中学习更好的对齐和特征表征,使模型可以保持稳健而准确的预测,同时保持较快的推理速度,其输出为,该模块的损失基于交叉熵函数计算的AL(Attention Loss)。此外,还有一个特征蒸馏损失(Feature Distillation Loss,FDL)需要被计算,它是用来优化特征提取模块的参数,以增强特征提取性能。通过计算输出和输入的均方误差来获得FDL的结果。
假设存在模型和,将它们的损失函数基于上面的内容进行改进,模型的自身损失为:
(5)
蒸馏互损失函数为:
(6)
式(2)中与分别表示在蒸馏时CTC蒸馏互损失与注意力蒸馏互损失的权重系数。
联合损失为:
(7)
类似的,模型的自身损失为:
(8)
蒸馏互损失函数为:
(9)
联合损失为:
(10)
这样,每个网络既能学会正确预测训练实例的真实标签也能匹配其同伴的概率估计。在训练时每个batch的迭代都会相互学习,根据联合损失函数更新模型参数。
2.2.4 知识超图的字段校正校验
为提升字段识别准确率和置信度,利用海关业务专家提供的资料构建校正校验规则对OCR识别结果进行后处理。知识图谱(Knowledge Graph,KG)可以表征实体之间结构化的关系,面对繁多的规则,针对每个字段基于知识图谱构建知识超图的字段校正校验规则集合。知识图谱被定义为有向图,其中,为节点的集合,代表海关随附单据待提取内容的实体标签,为边的集合,代表实体之间的关系。
当要对某个字段(Field)信息进行校正时,从改字段标签对应的查询节点出发,遍历节点之后图中的路径,找到与查询节点相关联的其他属性节点。遍历路径可以表示为一个路径集合,其中每个路径是一个节点序列,并且满足。在对每个字段进行校正校验时,需要遍历每个属性节点,每个节点对应校正规则或校验规则,因此对于每个路径,每个路径都有相同的权重,路径权重集合表示为。
知识超图根据每个字段的标签,获取对应的校正校验规则,例如使用编码规则对证书号码的置信度进行校验。通过上述方法,单据中的多个字段可以快速匹配到与其对应的规则,实现高效的字段校正和校验,大幅提高提取字段的准确率。
3 模型训练与效果
3.1 数据集准备与标注
本研究中使用了462张兽医卫生证书扫描件对提出的方案进行训练和测试。这些文件中需要提取的关键信息由人工标注。由于标注时依靠海关业务部门提供的先验知识参考和校对,其标注的可靠性能够得到保证。
3.2 模型训练
配置训练参数,训练参数见表1。文字识别的骨干网络为Mobile Net-V1 Enhanced,优化器为Adam。
表1 参数设置表
Table 1 Parameter setting table
参数名称 | 参数值 |
Epoch_num | 100 |
Batch_size | 12 |
Learning_rate | 0.0005 |
Algorithm | SVTR |
Backbone | MobileNetV1Enhanced |
Neck | SVTR |
Head | CTC |
3.3 实验结果
NRTR模型、基准模型SVTR模型以及蒸馏优化后模型MLKD-SVTR的对比实验结果见表2。
从表2中可以看到,MLKD-SVTR在性能上显著优于NRTR和SVTR,其字段错误率仅为28.34%,远低于NRTR和SVTR,同时推理速度最快,比SVTR和NRTR更高效。这一改进得益于知识蒸馏等技术,在保持轻量化的同时大幅提升识别精度和推理速度,更适合实际部署需求。
4 结语
本文模型中使用的算法改进措施显著提高了OCR技术识别的准确率和处理效率,特别是对于兽医卫生证书,通过优化的模型和算法,可以实现高效、准确的证书信息提取。这不仅满足了海关风险防控业务对实时性和准确性的高要求,也为海关的智能化监管和服务水平的提升提供了技术支撑。未来,模型的进一步优化和推广应用,将有助于通关效率的提升和海关业务流程的不断优化。
参考文献
[1] 朱成. 数字化转型对企业行政工作的影响[J]. 东方企业文化, 2023(S2): 44-46.
[2] 张静娴, 冷青轩, 陈航, 等. 基于图像滤波预处理的卷积神经网络汉字识别[J]. 电工技术, 2023(24): 69-73.
[3] 张策. 乌金体藏文古籍文档图像字符切分研究[D]. 兰州: 西北民族大学, 2023.
[4] 徐英卓, 王昊阳. 基于OCR的国家职业资格证书信息提取研究与应用[J]. 信息技术与信息化, 2024(5): 10-14.
[5] 邹卓峰, 张宝权, 李辉, 等. 基于图像识别技术的固井质量评价方法研究[J]. 钻探工程, 2024, 51(S1): 104-111.
[6] 蒋仕新, 邹小雪, 杨建喜, 等. 复杂背景下基于改进YOLO v8s的混凝土桥梁裂缝检测方法[J]. 交通运输工程学报, 2024, 24(6): 135-147.
[7] 张婷琳, 陈祥本, 丁晔, 等. 基于OCR技术的档案智能化收集方法研究[J]. 无线互联科技, 2024, 21(19): 32-36.
[8] 杨华, 汪俊雄, 沈浩, 等. 基于Attention-DBNet算法的文本检测方法[J]. 中南民族大学学报(自然科学版), 2024, 43(5): 674-682.
[9] 李有春, 汤春俊, 梁加凯, 等. 无人机输电线路巡检照片号牌文字识别方法[J]. 无线电工程, 2024, 54(6): 1560-1568.
第一作者:孟庆铎(1983—),男,汉族,吉林通化人,硕士,高级工程师,主要从事海关信息化系统开发工作,E-mail: 179797156@qq.com
1. 全国海关信息中心(全国海关电子通关中心) 北京 100005
2. 北京中海通科技有限公司 北京 100023
1. National Information Center of GACC (General Administration of Customs of China), Beijing 100005
2. China CUSLINK Co., Ltd., Beijing 100023
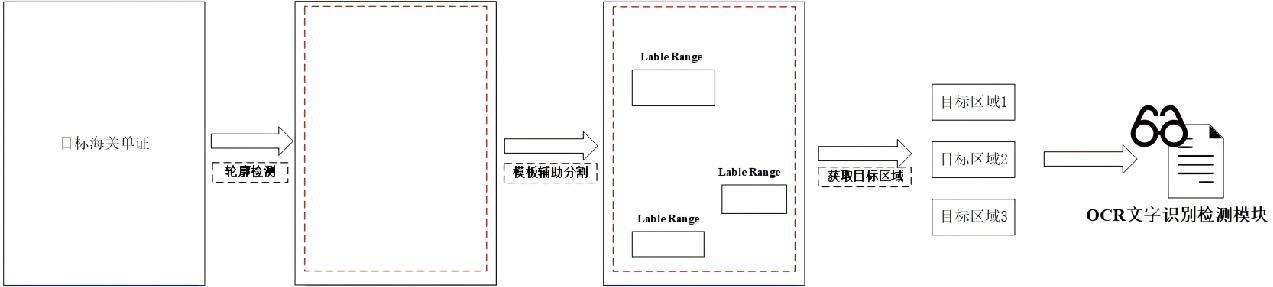
图2 基于形态学搜索模板匹配方法示意图
Fig.2 Schematic diagram of template matching method based on morphological search

图3 GTC训练策略
Fig.3 GTC training strategy
图4 蒸馏训练策略
Fig.4 Distillation training strategy
表2 不同模型的实验结果对比
Table 2 Comparison of experimental results of different models
模型 | 字段错误率 (%) | 推理时间 (s) |
NRTR | 85.07 | 8.42 |
SVTR | 86.67 | 1.51 |
MLKD-SVTR | 28.34 | 1.25 |
