





CopyRight 2009-2020 © All Rights Reserved.版权所有: 中国海关未经授权禁止复制或建立镜像

基于微隔离技术的数据中心云网络安全研究
作者:徐春利 刘鲲 孟庆晨 刘烨
徐春利 刘鲲 孟庆晨 刘烨

全国海关信息中心(全国海关电子通关中心)
National Information Center of GACC (General Administration of Customs of China)
全国海关信息中心(全国海关电子通关中心)(以下简称“信息中心”)是海关总署在京直属事业单位,成立于1986年,是国家部委中最早成立的专门从事信息化建设的单位之一,2008年加挂“全国海关电子通关中心”牌子,2014年被划为公益一类事业单位。现有内设部门16个,其中,电通中心下设11个处(室),信息中心下设5个部。自成立至今,信息中心为海关信息化建设作出了重要贡献,先后荣获“全国文明单位”“全国创先争优先进基层党组织”“全国三八红旗手”“中央和国家机关五一劳动奖章”等30余项国家级荣誉称号或奖项,6人享受国务院政府特殊津贴。
信息中心工作职责主要包括:一是承担海关信息系统核心节点运维管理工作,建立海关信息系统实时监控体系和故障预警及处置机制,7×24小时支撑保障总署机关、直属海关和各通关业务现场不间断运行。二是承担海关信息化项目建设工作,为国家重大战略实施、海关改革发展各项政策措施提供信息化保障。三是承担海关信息系统安全和防护工作,建成网络安全防护、数据安全保护等平台,实现核心系统异地容灾交替运行,保障全国海关信息系统安全稳定运行。四是承担大数据治理及应用工作,为总署服务国家宏观决策提供数据保障,开展大数据治理,构建大数据智能模型,在风险甄别和打击走私等实战中取得较好成效。
信息中心注重提升科研创新和应用能力,现有国家保密科技测评中心海关系统测评实验室、信息中心软件测评实验室(通过中国合格评定国家认可委员会认证)、海关国际通关信息化应用创新实验室、海关国际贸易信息标准化应用创新实验室等4个实验室,牵头主持“海关税收征管与风险甄别防控技术研究及应用示范”等国家“揭榜挂帅”项目研究工作。
新时代新征程,信息中心坚持以习近平新时代中国特色社会主义思想为指导,全面贯彻落实党的二十大和二十届二中、三中全会以及中央经济工作会议精神,深入学习贯彻习近平总书记重要指示批示和给红其拉甫海关全体关员重要回信精神,聚焦更优监管、更高安全、更大便利、更严打私,充分发挥科技国家队作用,全力为智慧海关建设、“智关强国”行动提供科技供给,全力保障信息系统安全稳定运行,全力提升科技创新和科研攻关能力,为以海关现代化服务助推中国式现代化提供坚强支撑和保障。



目 次
中国口岸科学技术
◎ 应用开发
04 总集成管理工作对海关信息化建设的 影响研究
………………………………………………………………………………………………………………………… 张晓光 郭莉萍
09 基于人工智能的软件需求分析方法 实践与研究
………………………………………………………………………………………… 杨德辉 范子寅 谢 振 马逸行 冯立胜
18 微服务架构在海关信息化建设中的应用实践
……………………………………………………………………………………………………………… 李 飞 李志鹏 孙 培
25 海关政务应用整合技术研究与设计
………………………………………………………………………………………… 顾 岩 袁 勇 李 俊 吴 奇 单春磊
31 区块链技术在特殊物品通关监管中的 应用探索
……………………………………………………………………………………………………………… 胡自强 周 艳 陆 地
37 混沌工程与可靠性测试技术研究
…………………………………………………………………………………………………………………………………… 杨 硕
◎ 数据分析
42 海关大数据资源一体化管理 与共享架构的研究
……………………………………………………………………………………………………………… 徐龙宁 何长庚 孙建明
49 基于AIGC技术的自动生成分析报告研究
…………………………………………………………………… 马群凯 王 齐 王佳蕾 李 玄 文 杨 赵碧君 张济凡
55 大模型在海关统计工作中的应用研究
…………………………………………………………………………………………………… 杜琳美 吕 涛 毕 滔 陈 衎
63 光学字符识别技术研究 及在海关监管中的应用
……………………………………………………………………………………………………………… 孟庆铎 秦 力 宗超飞
◎ 网络安全
70 基于AI技术的海关网络内生情报生成 技术与应用研究
…………………………………………………………………………………………………… 范絮妍 石 宇 陶君茹 相 森
79 基于微隔离技术的数据中心云网络安全研究
…………………………………………………………………………………………………… 徐春利 刘 鲲 孟庆晨 刘 烨
◎ 运行维护
87 人工智能技术在海关信息化运维 态势感知中的应用
……………………………………………………………………………………………………………… 李 辰 代雪峰 李 判
93 基于即时通信软件打造海关移动业务平台
……………………………………………………………………………………………………………… 孙 平 王羽赫 王 涛
102 国产事务型数据库的应用研究
…………………………………………………………………………………………………… 马志坤 熊 飞 梁 俊 冯立胜
CONTENTS
CHINA PORT SCIENCE AND TECHNOLOGY
◎ Application & Development
04 Research on the Impact of General Integration Management on Customs Informatization Construction
……………………………………………………………………………………………………… ZHANG Xiao-Guang GUO Li-Ping
09 Research on Software Requirement Analysis Method Based on Artificial Intelligence
………………………………………………………………… YANG De-Hui FAN Zi-Yin XIE Zhen MA Yi-Xing FENG Li-Sheng
18 Application and Practice of Microservice Architecture in Customs Informatization Construction
………………………………………………………………………………………………………………… LI Fei LI Zhi-Peng SUN Pei
25 Research and Practice on Integration Technology of Customs Administration Applications
…………………………………………………………………………………… GU Yan YUAN Yong LI Jun WU Qi SHAN Chun-Lei
31 Exploration of the Application of Blockchain Technology in Customs Clearance of Special Goods
………………………………………………………………………………………………………… HU Zi-Qiang ZHOU Yan LU Di
37 Research on Chaos Engineering and Reliability Testing Technology
……………………………………………………………………………………………………………………………… YANG Shuo
◎ Data Analysis
42 Research on Integrated Management and Sharing Architecture of Customs Big Data Resources
……………………………………………………………………………………… XU Long-Ning HE Chang-Geng SUN Jian-Ming
49 Research on Automatic Generation of Analysis Reports Based on AIGC Technology
……………………………………… MA Qun-Kai WANG Qi WANG Jia-Lei LI Xuan WEN Yang ZHAO Bi-Jun ZHANG Ji-Fan
55 Research on the Application of Large Models in Customs Statistics
……………………………………………………………………………………………… DU Lin-Mei LYU Tao BI Tao CHEN Kan
63 Research on OCR and Its Application in Customs Control
………………………………………………………………………………………………… MENG Qing-Duo QIN Li ZONG Chao-Fei
◎ Cyber Security
70 Research on AI-Based Endogenous Intelligence Generation Technology and Its Application in Customs Networks
………………………………………………………………………………………… FAN Xu-Yan SHI Yu TAO Jun-Ru XIANG Sen
79 Research on Data Center Cloud Network Security Based on Micro-Segmentation Technology
………………………………………………………………………………………… XU Chun-Li LIU Kun MENG Qing-Chen LIU Ye
◎ Operation & Maintenance
87 Application of Artificial Intelligence Technology in Customs Informatization Operation and Maintenance Situation Awareness
………………………………………………………………………………………………………… LI Chen DAI Xue-Feng LI Pan
93 Building a Customs Mobile Services Platform Based on Instant Messaging Software
…………………………………………………………………………………………………… SUN Ping WANG Yu-He WANG Tao
102 Research on the Application of Domestic Transactional Database
……………………………………………………………………………… MA Zhi-Kun XIONG Fei LIANG Jun FENG Li-Sheng
第7卷 增刊
2025年7月
CHINA PORT SCIENCE AND TECHNOLOGY
应用开发 / Application & Development Inspection
总集成管理工作对海关信息化建设的
影响研究
张晓光 1 郭莉萍 1
摘 要 海关信息化工作起步早,现已全面覆盖海关各业务工作领域,并对海关业务工作的开展具有不可替代的支撑作用。伴随着我国改革开放的深化发展和全球经济形势的快速变化,海关信息化建设工作的复杂性大为提升,总集成工作对海关信息化建设工作的保障作用也日益突出。本文总结了海关总集成工作的现状、面临的问题与挑战,并针对问题进行了分析,最后提出了解决方案,可应用于海关以及业界的信息化总集成工作中。
关键词 海关信息化;总集成管理工作;顶层设计;公共平台;技术标准
Research on the Impact of General Integration Management on Customs Informatization Construction
ZHANG Xiao-Guang 1 GUO Li-Ping 1
Abstract The development of customs informatization work began early and has now comprehensively covered all operational areas of customs, playing an indispensable supporting role in the operations of customs business. With the deepening of China’s reform and opening-up and the rapid changes in the global economic landscape, the complexity of customs informatization construction has significantly increased, and the role of system integration in safeguarding this work has become increasingly prominent. This paper summarizes the current status, existing problems and challenges, in customs system integration, then it analyzes the problems, and proposes solutions that can be applied to informatization system integration work within customs and across related industries.
Keywords customs informatization; general integration management; top-level design; public platform; technical standards
海关信息化作为海关业务工作的重要支撑手段,一直紧随着海关业务工作的需要而不断发展。目前,海关信息化已经覆盖通关、监管等海关业务领域,涉及大数据、智能模型、物联网等技术领域,并在向智慧型信息化系统方向发展。
根据海关信息化建设的发展目标和其所支撑的海关业务发展趋势,需要将原来以单个业务领域为对象的信息化系统建设模式,转变为多业务领域相互协作、各信息化作业系统互联互通、多技术手段相互配合的建设模式,这对海关信息化建设中的总集成工作提出了更高要求。本文通过回顾海关总集成工作的现状,分析其对海关信息化工作的作用,并针对性地提出海关总集成工作改进方向。
1 海关信息化建设及总集成工作
中国海关信息化建设从20世纪80年代开始起步,先后历经了独立应用建设、集约应用建设、联网应用建设、综合应用建设等发展阶段,目前已经进入智能化应用建设阶段。伴随着海关信息化的发展,海关信息化集成工作也从无到有,并在信息化建设过程中发挥着重要作用。
本文中的总集成是指应用系统集成,即“从系统的高度提供符合客户需求的应用系统模式并实现该系统模式的具体技术解决方案和运维方案,即为用户提供一个全面的系统解决方案”[1]。海关总集成工作即为满足海关业务和政务管理工作的需求,并根据海关信息化应用系统建设模式和要求,组织开展海关信息化系统建设,为海关工作人员提供其所需的业务信息化系统或政务管理系统。
海关总署首先在2013年启动的金关工程二期建设工作中,通过公开招标方式引入业界符合相关要求的公司承担工程总体集成工作;随后从2018年开始,海关总署指定内部信息化建设单位作为海关内部的总集成单位,承担海关署级项目建设工作的总集成管理工作。总集成管理主要工作内容包括:负责业务需求总体分析、总体技术方案设计、总集成方案编写、组织项目实施、系统集成、联调测试等工作,把控项目建设进度和建设质量等。海关开展总集成管理工作主要目标是希望通过综合治理和技术管控,解决海关信息化建设工作中所面临的各业务领域互通需求日益增加、使用技术的复杂性高、并行开展的建设任务数量多工作量大等挑战。
2 总集成管理工作概述
2.1 总集成管理工作作用
总集成管理工作是指以项目总体目标为导向进行系统化任务分解与综合管理的过程,包括识别、确定、结合、统一与协调各种不同的项目管理的过程与活动[2-3]。总集成管理是项目管理中的核心职能,旨在从全局视角出发,通过系统化的方法协调和整合项目的所有要素(包括范围、时间、成本、质量、资源、风险等)为一个有机整体,确保项目目标顺利实现,并实现建设过程最优,故总集成管理工作对信息化建设工作具有重要意义,主要包括:
(1)打破“信息孤岛”,实现系统互联互通。通过统一技术规划,避免因通信接口不兼容、数据标准不统一等问题造成系统间互不连通、“烟囱林立”的情况,保障各系统既可并行独立开发,又可有效衔接整合。
(2)优化资源配置,提升建设效率。有效协调信息化建设所涉及的硬件、软件、数据、网络、安全等众多领域资源,有效协调各领域建设团队工作,实现物资、人力、时间的动态平衡。
(3)强化跨部门协同,降低协作成本。建立跨团队协作机制,协助解决跨团队问题,促进信息化建设工作顺利进行。
综上所述,总集成管理通过统一规划、动态调整和全面协助,保障信息化项目成功交付。
2.2 海关总集成管理工作简述
总集成管理工作内容目前没有对应的国家标准,通常由信息化建设工作的组织方根据其自身需要确定。海关总署根据其自身信息化建设需要,对海关总集成管理工作要求如下:
(1)负责技术架构把控和项目整体集成:进行项目建设需求分析,指导或开展项目总体设计,编制总体集成方案、集成实施方案等,制定相关技术标准;在项目实施过程中,进行重大技术变更评估和控制。
(2)负责实施过程管理控制:开展项目计划管理、进度管理、配置管理、变更管理、风险管理、问题管理,并提供验收服务。
(3)承担顾问咨询服务:在技术设计、集成实施、重点技术难题解决、验收准备、后期运维等方面提供技术指导和咨询服务。
(4)项目建设质量把控:组织对详细技术方案进行审核;组织开展联调测试工作,并出具联调测试报告;对系统上线材料和项目验收进行检查等。
此外,对于外部总集成还要求其按照国家信息化工程管理相关要求,承担以下工作:协助开展采购工作、协助监理单位实施合同管理等;按照项目组织方要求,做好各种项目文档材料编制和保管工作;做好办公场所和所需设备的准备、做好培训、会议保障等各类保障工作。
目前,海关总署对总集成管理工作的核心要求集中在总体技术管控、建设过程管理、质量总体把控方面,并希望通过总集成管理工作有效规避建设过程中在技术、管理方面的问题和风险。通过金关工程二期和2018年以来的署级项目建设实践,证明了海关总集成管理工作发挥了预期作用,对各类工程和项目的建设工作起到了有效的保障和支撑作用,确保金关工程二期顺利完成建设和竣工验收[2]以及从2018年至今的海关署级项目也均顺利开展建设。
3 总集成管理研究
3.1 总集成管理工作机制
海关总集成管理工作由海关总署科技发展司(以下简称“科技发展司”)统一负责。科技发展司是海关信息化建设工作的总牵头部门,一方面,通过制定相关管理制度和规范,明确包括海关外部、内部总集成在内的信息化应用项目建设各方的工作职责和工作要求;另一方面,对海关外部、内部总集成所承担的总集成管理工作给予指导和评价。在工作分工方面:海关外部、内部总集成对上向科技发展司负责,接受其工作指导,并定期报告总集成自身工作以及信息化应用项目建设情况,报请科技发展司解决海关外部、内部总集无法解决的问题和风险;海关外部、内部总集对下组织信息化应用项目的建设方开展建设工作,并通过检查、评审等方法确保其工作过程规范性和工作质量。
3.2 总集成管理工作方法
海关外部、内部总集工作均是围绕项目建设过程开展,并覆盖项目建设生命周期过程的各个重要阶段,包括立项阶段、实施阶段、上线阶段等。一方面,通过技术和管理评审方法,在项目技术管控、规范性管理等方面发挥其作用;另一方面,通过支持和指导工作,支持项目相关方完成项目建设工作。
对于日常的海关署级信息化应用项目,海关总集成管理主要工作方法见表1。
海关总集成管理工作确保了系统建设和集成工作的规范性,促进了项目相关各方的有效协同,促进了项目相关资源的优化配置,保障了项目进度与实施质量,在海关信息化建设工作中所发挥了积极的作用。
4 总集成管理工作面临的挑战及应对策略
近年来,随着我国经济社会的快速发展,对海关信息化建设工作提出了新要求,主要包括三方面:一是提升通关工作自动化水平,持续压缩通关时间,避免物流拥堵和经济损失,特别在跨境电商领域,要求海关能够实现“秒级通关”。二是提升风险布控工作的有效性,实现对高风险货物拦截准确,需要海关运用大数据等高新技术手段对侵权货物实现精确、快速识别。三是支撑国内统一大市场建设,打破区域壁垒;降低企业物流成本,促进内外贸规则衔接,要求海关实现跨关区“一次申报、全域通行”。为实现上述要求,既需要加强现有信息化业务系统之间的互联互通,又需要进一步加强大数据、风险模型、物联网等技术与业务系统之间的整合,从而对海关信息化集成工作提出了新的挑战。
为有效应对挑战,海关总集成管理工作需要参考现代项目集成管理思想,即在工作中通过项目生命周期内各阶段的集成、全部项目管理职能的集成、项目组织和责任体系的集成以及信息集成等方面把项目的各主体、各管理要素、各生产阶段有机结合起来,从而更好地促进建设项目管理目标的实现 [4]。目前海关总集成管理工作还主要偏重于项目过程管理和技术规范性检查,在需求分析、总体设计等技术管控工作方面还需要继续加强。
4.1 开展需求统筹
海关业务领域较多,原有信息化建设基本是围绕各个业务领域单独开展的,但根据国家对海关工作的新要求,不论是提升自动化通关水平,还是实现跨关区通关工作,均需要各业务领域更加紧密地衔接在一起。与此相配合,在海关信息化建设思路上要打破原有的按业务领域分别开展信息化建设的模式,以全局化、集成化的思路将海关业务领域看成一个有机整体,从业务需求层面开展总集相关工作,即进行需求统筹。
在工作方法上,建议首先梳理现有的各业务领域信息化系统功能情况,特别是各信息化系统之间的关联情况,从而形成统一的海关信息化需求底账;在此基础上,对于各业务领域主管部门所提出的新业务需求,按照统一方法开展需求分析,识别新业务需求与已有需求底账的关系,统一安排业务需求的实现方法,从而在根源上杜绝“信息孤岛”的出现,为后续信息化系统总体设计奠定基础。
在工作组织上,建议参照银行或电信等业务领域也较多的行业,组建需求统筹和管理部门。该部门需要对行业需求有完整的认识,并负责建立完整的需求统筹和管理流程、审核机制和优先级排序机制[5]。海关需求统筹和管理工作属于海关总集成管理工作的重要组成部分,需在项目立项初期与提出需求的业务主管部门密切配合,对业务需求进行指导和检查,确保需求统筹工作顺利完成。
4.2 加强顶层设计
顶层设计是指从全局出发,围绕着某个对象的核心目标,统筹考虑和协调对象的各方面和各要素,针对对象的基本架构和运作机制进行总体、全面的规划和设计[6]。在海关总集成管理工作中开展顶层设计,是指在需求统筹基础上,将海关业务系统视为一个完整的信息化系统,并从上至下开展系统设计。在具体工作上,首先在业务需求底账基础上,形成海关信息化系统的整体规划蓝图,明确整体设计要求和各领域之间的关联关系,再分别开展各个领域的具体规划,确保后续各业务领域的信息化建设工作均在整体设计要求下统一有序开展;其次,将大数据、智能模型等先进技术均纳入整体设计,通过先进技术对业务功能的支撑,实现各业务领域工作效能的全面提升。有效的顶层设计是总集成管理工作中最为重要的内容,工作中应始终保持“业务驱动、用户至上”的设计理念,并配套建立“滚动优化、持续改进”的实施机制,支持在具体的信息化项目中逐步实现顶层设计,实现一张蓝图绘到底。
4.3 建设技术公共平台及技术标准
电子政务公共平台是指运用云计算技术,统筹利用计算、存储、网络等资源,统一建设并能对外提供应用功能、基础设施、数据服务、信息安全和运行保障的综合性服务平台[7]。在强化顶层设计的基础上,海关可以借鉴电子政务公共平台的建设和应用经验,建设自身的技术公共平台并充分发挥其在信息化项目建设中的基础性、支撑性和协同性作用,以统一技术实现方法,完成资源共享。在具体工作上,建议在应用、数据、安全等技术领域根据顶层设计的统一要求,分别开展技术公共平台的建设,确保各平台可以对外提供集约化的技术服务,如统一身份认证和授权系统、统一门户、统一业务流程等,直接供海关信息化业务系统在开发时能够相互调用。
此外,建议加强开展与技术公共平台相配套的海关信息化技术标准制定工作,包括设计开发、数据接口、安全协议等方面,通过统一技术标准,与公共技术平台一起实现减少信息化建设的技术复杂度、降低信息化建设成本、提升信息化建设的工作效率的目的。
5 结语
海关总集成管理工作目前已在海关信息化项目建设过程的规范保障以及技术支持方面发挥着重要作用。通过开展需求统筹、顶层设计、公共技术平台和技术标准建设等工作,总集成管理工作可以更加有效地提高海关信息化建设工作水平,为推进智慧海关建设提供重要保障。
参考文献
[1]柳纯录.系统集成项目管理工程师教程[M]. 北京: 清华大学出版社, 2009: 603-604.
[2]海关总署. 金关二期工程顺利通过竣工验收[J]. 中国海关, 2018(3): 32-34.
[3]中国(双法)项目管理研究委员会.中国项目管理知识体系(C-PMBOK2006)(修订版)[M]. 北京: 电子工业出版社, 2008: 176-177.
[4]王华. 工程项目管理[M]. 北京: 北京大学出版社, 2014: 452-453.
[5]刘秋万, 孟茜, 姚丹. 全球化时代的银行信息系统建设[M].北京: 机械工业出版社, 2015: 293-294.
[6]芮平亮, 傅军, 杨怡. 信息系统顶层设计技术[M]. 北京: 电子工业出版社, 2015: 4-5.
[7]石友康, 段世慧, 聂秀英. 基于云计算的电子政务公共平台技术与实践[M]. 北京: 人民邮电出版社, 2024: 5-6.
第一作者:张晓光(1975—),男,汉族,北京人,硕士,主要从事项目管理、总集成管理相关工作,E-mail: 976071059@qq.com
1. 全国海关信息中心(全国海关电子通关中心) 北京 100005
1. National Information Center of GACC (General Administration of Customs of China), Beijing 100005
中国口岸科学技术
表1 总集成管理工作方法
Table 1 General integration working method
项目阶段 | 工作方法 | 工作内容和目的 |
立项阶段 | 支持立项材料编制 | 从需求分析、技术设计等方面对立项材料编写工作进行支持. |
立项阶段 | 立项材料规范性检查 | 检查技术架构、数据、安全、运维以及系统间关联关系等是否符合海关相关技术要求. |
实施阶段 | 设计方案合规性检查 | 确保项目的技术设计方案在架构、数据、安全等各技术领域均符合海关信息化技术制度和规范要求. |
实施阶段 | 联调测试方案检查, 出具联调测试报告 | 根据技术方案检查联调测试方案的正确性、完整性, 确保按照技术方案实现项目建设内容的集成. |
实施阶段 | 项目实施计划检查 | 编制合理的项目实施计划. |
实施阶段 | 项目跟踪管理 | 持续跟进项目进展, 编制项目周报并向项目相关各方报告, 协调解决项目建设中的问题和风险. |
实施阶段 | 技术变更管理 | 对变更开展技术评估和检查, 确保变更所引发的技术设计调整符合相关要求, 并按照标准流程完成变更手续. |
部署阶段 | 上线材料审查 | 对项目技术文档和上线材料开展技术合规性检查以及上线核查, 确保项目检查成果符合相关的海关信息化技术和管理规范. |
验收阶段 | 验收材料检查 | 对验收材料的完整性和规范性开展检查. |
第7卷 增刊
2025年7月
Application & Development Inspection / 应用开发
基于人工智能的软件需求分析方法
实践与研究
杨德辉 1 范子寅 2 谢 振 1 马逸行 1 冯立胜 1 *
摘 要 在当今快速发展的软件开发领域,需求分析作为项目开发的关键节点,其准确性和高效性对于整个项目具有重要作用。本文创新性地提出了一种融合大语言模型(Large Language Model,LLM)与统一建模语言(Unified Modeling Language,UML)可视化建模的软件需求分析方法,并构建了“需求理解-结构化转换-模型验证”三步法,推动智慧赋能软件开发需求分析,提供一种更为高效的解决方案。
关键词 人工智能;大语言模型;需求分析;统一建模语言
Research on Software Requirement Analysis Method Based on Artificial Intelligence
YANG De-Hui 1 FAN Zi-Yin 2 XIE Zhen 1 MA Yi-Xing 1 FENG Li-Sheng 1*
Abstract In today’s fast-paced software development field, requirements analysis is a key node in project development, and its accuracy and efficiency play an important role in the whole project. This paper innovatively proposes a software requirements analysis method that integrates large language model (LLM) and unified modeling language (UML), visual modeling, and constructs a three-step method of “requirements understanding-structured transformation-model verification” to promote the intelligent empowerment of software development requirements analysis and provide a more efficient solution.
Keywords artificial intelligence (AI); large language models; requirements analysis; unified modeling language (UML)
在软件工程中,准确且高效的需求分析是项目成功的关键环节之一。然而,传统的需求分析方法往往面临着需求理解不准确、文档一致性难以保证等问题。为解决这些问题,本文提出了一种结合大语言模型、统一建模语言(Unified Modeling Language,UML)等工具提升软件需求分析的方法。该方法将大语言模型的强大语义解析能力与UML可视化建模的优势相结合,通过构建特定的处理流程,实现了软件需求分析的智能化和高效化,并提升了软件需求规格说明书的编写质量。
1 总体概述
1.1 需求分析
1.1.1 传统需求分析的现状
传统软件需求分析方法长期面临两大核心挑战:自然语言歧义性和变更管理复杂性。
在自然语言歧义性方面,需求文档通常采用非结构化自然语言描述,导致关键要素的模糊性。例如,功能性需求中的动词不确定性:“XXX项功能应优化完善”(未定义优化完善标准);非功能性需求的量化缺失:“界面响应要快速”(未明确时延阈值);多角色理解的差异性:业务部门描述的“用户权限管理”与开发团队的理解可能存在偏差。很多例子表明,需求质量的好与坏直接导致系统功能设计是否严谨与完整,用户体验是否便捷[1-2],进而影响项目成功与否。另外,研究表明,约68%的需求错误源于自然语言表述的不精确[3],这种歧义性在需求传递链中逐级被放大,最终可能导致高达40%的开发返工[4]。
在变更管理复杂性方面,敏捷开发模式下,需求变更频率可达每周2~3次,传统人工跟踪方式主要面临着三方面困难:一是变更影响范围分析不全面,单一需求修改可能波及5~8个关联模块或多个系统;二是版本控制碎片化,Word/Excel文档的版本难以维护一致性;三是追溯矩阵更新滞后,“需求-设计-测试”的追溯链路存在割裂。
1.1.2 对模型驱动开发的工具需求
模型驱动开发(Model-Driven Development,MDD)范式要求将非结构化需求转化为形式化、可执行的精确模型表达,这对工具链提出了新范式要求。
(1)需具备自动化模型生成能力,通过集成大语言模型的语义解析技术,实现从自然语言需求到UML/SysML等标准模型的无损转换,某工业案例显示生成效率提升320%。
(2)需建立动态协同机制,支持需求变更与模型演化的实时同步,通过双向追踪矩阵确保语义一致性,如需求-模型元素映射准确率≥95%。
(3)需构建多维度验证体系,集成形式化验证、仿真模拟与合规性检查功能。例如,基于线性时序逻辑(Linear Temporal Logic,LTL)验证状态机模型的完备性,或通过能耗仿真评估架构可行性。
当前工具链正从传统绘图工具(如Enterprise Architect)向AI增强型建模平台演进,其核心能力体现为“需求-模型-代码”的数字闭环,标志着需求分析工作已进入大模型时代。
1.2 研究的创新点
本研究提出一种多模态智能需求分析方法,通过融合DeepSeek、通义千问、LLaMA等大语言模型与UML可视化建模工具,实现需求分析的范式革新。其核心创新点在于构建“需求感知-语义建模-动态验证”的全链路可视化流程:首先,利用多模型协同机制,如DeepSeek、通义千问处理自然语言需求、LLaMA解析领域术语,将非结构化需求解构为功能、性能、约束等多维度语义要素;其次,基于PlantUML的自动化模型生成引擎,将语义要素动态映射为用例图、时序图、状态图等标准模型,支持需求变更的实时模型演化;最后,引入知识图谱技术,建立需求实体与模型元素的向量化关联网络,生成可视化需求分析内容。研究表明,通过此方法能够为复杂系统开发提升需求分析的能力。
2 理论分析
2.1 大语言模型技术突破
以DeepSeek、通义千问、LLaMA为代表的先进模型[5-7],通过多粒度语义解析架构重构了自然语言理解的边界。
2.1.1 语义理解层面的突破性进展
DeepSeek采用动态稀疏注意力机制,在长文本需求,如30K tokens的政务系统需求文档中实现跨段落指代消解准确率97.3%,相比传统模型提升21%,其创新的领域自适应微调框架使医疗领域术语(如“DICOM协议”)的语义解析精度达94.5%。
通义千问提出多模态语义融合算法,支持文本、流程图、数学公式的联合解析,如将“吞吐量≥QPS 10k”自动关联负载均衡设计,在工业控制系统需求分析中,多模态语义对齐准确率提升38%。
LLaMA-2通过层次化上下文编码器(Hierar- chical Context Encoder),解决嵌套否定句,如“非紧急状态下不得启用备用电源”的语义歧义问题,在航空航天需求验证中使意图识别F1值达到89.7%,较基线模型提高27个百分点。
2.1.2 知识推理层面的范式革新
DeepSeek-R1构建可微分逻辑推理引擎,将行业规范编码为可计算约束,如ISO 26262汽车安全标准,在自动驾驶需求评审中自动检测出“感知延迟≤100 ms”与“冗余计算架构”的逻辑矛盾,其实验召回率约92%。通义千问-MoE基于混合专家知识库,包含了128个领域专家,实现跨领域知识迁移,如将金融风控规则映射为数据追溯架构设计,在跨境支付系统需求分析中,规避83%的合规性设计缺陷。LLaMA-3引入强化学习驱动的推理路径优化(RL-Guided Reasoning),通过需求变更反馈动态调整推理策略,在电信级系统需求演化中,使逻辑冲突检测效率提升41%。
2.2 研究设计
本研究的目的是在AI大模型高速发展的背景下,如何利用新技术更快、更好地编写软件需求规格说明书。研究将围绕软件需求规格说明书中几个重要节点进行设计,分别为时序图、用例图、状态图以及页面原型。研究以金伯利进程国际证书业务中某个项目需求为背景,开展技术探索。
2.2.1 工具的选择
(1)UML工具选择。UML是一种通用的可视化建模语言,可以用来描述、可视化、构造和文档化软件系统的各项工作。经过软件工程领域的广泛实践,UML已成为软件需求分析及相关领域重要的分析方法和工具。随着信息化技术的发展,UML的图从手工绘制、传统UML工具逐渐向着类代码化绘制的方向发展。传统UML工具丰富了手工绘制所不能展现出的UML分析的深度,而新的类代码化工具则将UML分析工作从复杂的软件操作中解脱出来。针对UML工具的选择,在研究过程中进行了比较,表1为传统UML工具和PlantUML的对比[8-10]。
由上述对比可知,PlantUML是一种开源的、用于生成 UML图的工具,它使用简单的文本描述语法来创建各种类型的UML图,如用例图、类图、时序图、状态图、活动图、用例图等。该工具不仅拥有简洁易读、灵活强大的特点,而且在软件相关行业具有一定应用基础,推广起来成本相对较低,因此本研究重点使用该工具开展设计。
(2)大模型选择。由于选择了PlantUML作为支持工具,所以大模型的选择需要明确每个模型的特点以及它们在处理PlantUML语法时的表现。PlantUML能够生成UML图表,因此大模型需要理解其特定语法结构,并能够生成或解析这些结构。表2为ChatGPT、通义千问、DeepSeek、KIMI等4个大模型的综合对比。
由对比可知,现在国内外大模型种类丰富,涵盖多个领域和技术路线,不同厂商推出的大模型在不同的业务领域都表现出了卓越的性能。经过多次实践探索,结合当前对软件需求编制的支持需求,DeepSeek-R1对PlantUML语法的支持较之其他模型更为适合,一次生成的PlantUML脚本可在编译器中直接运行,不需要人工干预。
2.2.2 UML核心图表选择
在开展海关软件需求分析工作中,为着重于分析需要实现的业务用例,弱化繁杂的UML约束要求,同时为了更好地绘制和使用,本研究团队提出通过使用UML中的经典图例,即时序图、用例图、状态图[11-12]。其中,时序图用于描述对象之间在时间维度上的交互顺序,展现系统中各个对象如何按照时间顺序进行消息传递和协同工作;用例图是一种用于描述系统功能需求的图形化工具,主要用于展示系统与外部交互者的关系,并用于检查系统功能是否完整;状态图是UML中用于描述一个对象在生命周期中的不同状态以及状态之间的转换的图形工具,用于描述业务主体在不同环节的状态转变。
2.3 实践成果
海关软件需求分析工作选用了时序图进行业务用例分析,用例图和状态图进行系统用例分析,并结合说明性文本描述软件需求。具体工作步骤如下:(1)明确业务需求,从项目建议书等材料中识别业务用例;(2)利用PlantUML时序图分析业务用例,识别参与角色、系统,明确交互行为和任务分工(作为后期拆解任务书等工作的基础);(3)填写RTM需求跟踪矩阵(Requirement Traceability Matrix,RTM),完成软件需求规格说明书中业务用例与系统用例的对应关系;(4)利用PlantUML用例图分析整体系统用例,明确系统边界,列明拆解的系统用例并分析其中关系;(5)利用PlantUML状态图分析单一系统用例,通过状态转换理解对应的业务需求,指导软件开发编码工作。
结合实际工作,经实验研究,绘制图例需经过三步,即“三步法”,生成图例,具体如下:
(1)生成初版图例:基于现有“XXX申请”为例,编写概要文字表述,作为对话大模型的输入,通过大模型获取原始PlantUML脚本,并根据脚本生成初版图例。
(2)持续优化图例:技术人员与需求人员基于初版图例反复对碰需求,确保图例与需求一一对应。与此同时,技术人员对照人工手绘版图例,优化图例,形成用例图最佳实践。
(3)图例反向生成文字:最终使用图例源码,通过大模型反向生成文字,作为软件需求规格说明书文字说明部分。
下文以金伯利进程国际证书业务中A项目部分需求分析为例,分步展示每个环节成果。
2.3.1 时序图
第一步,生成初版时序图,如图1所示。
大模型使用DeepSeek模型,在大模型输入的内容详见下列文字描述:
我需要生成PlantUML时序图,需求如下:(1)企业在国际贸易“单一窗口”中金伯利国际证书功能模块录入企业基本信息后提交;(2)系统校验通过后将企业基本信息发往海关,海关返回接收回执;(3)海关接收成功后,企业可以在国际贸易“单一窗口”中金伯利国际证书功能模块录入企业变更信息后提交;(4)系统检验通关后将企业变更信息发往海关,海关返回接收回执;(5)海关端对企业基本信息进行修改,国际贸易“单一窗口”接收海关端修改后的企业基本信息;(6)企业可在国际贸易“单一窗口”中金伯利国际证书功能模块查询当前最新的企业。
第二步,持续优化时序图,如图2所示。
技术人员与需求分析人员基于初版时序图反复对碰需求,通过修改PlantUML代码方式,持续优化时序图。通过参照人工手绘时序图,通过关键字提示功能优化时序图、关键词、角色,代码要求如下:(1)所有角色统一使用浅蓝色标注;(2)有校验的地方使用alt语法;(3)每次系统间的交互使用一个activate;(4)使用autonumber对时序图编号。
第三步,时序图反向生成文字。
将PlantUML脚本放入DeepSeek大模型,反向生成文字描述。对该时序图的具体文字描述如下:在国际贸易“单一窗口”中的金伯利国际证书申请模块,企业用户首先录入企业基本信息并提交,平台接收到信息后进行企业基本信息校验。如果校验通过,国际贸易“单一窗口”将企业基本信息发送给海关,海关接收后返回接收回执;如果校验不通过,国际贸易“单一窗口”向企业用户提示校验不通过。当海关接收成功后,企业用户可以在国际贸易“单一窗口”录入企业变更信息并提交,再次进行校验,若校验通过,将企业变更信息发送给海关,海关返回接收回执;若校验不通过,则向企业用户提示校验不通过。如果海关未接收成功,则不进行后续操作。之后,海关对企业基本信息进行修改,并将修改后的信息发送给国际贸易“单一窗口”。国际贸易“单一窗口”接收修改后的企业基本信息。最后,企业用户通过国际贸易“单一窗口”查询当前最新的企业信息,国际贸易“单一窗口”将当前最新企业基本信息返回给企业用户。
通过脚本反向生成的描述内容语句通顺,能够正确表达时序图中的流程关系,有效帮助技术人员和需求分析人员降低编写文档压力。
2.3.2 用例图
用例图同样遵循“三步法”流程,使用大模型生成原型和反向生成文字步骤一致,在此不再赘述。用例图仅展示不同于时序图的关键词工程。初版用例图如图3所示。
一旦业务复杂,大模型生成的用例图可能出现连线交错的问题,此时可以调整一下布局,通过语法调整指向,首先把版式调整为上下结构,并区分相关用户与系统功能用例之间关系,使用例图变得更清晰,其次减少连线之间的交错,最终得到如图4所示用例图。
删除package/rectangle分组,通过语句优化及完善,将曲线变为直线,形成最终用例图,如图5所示。
该用例图包含3个角色:海关总署税收征管局(以下简称“税管局”)、直属海关和隶属海关。同时,有7个用例,分别是样本数据补充、冲突预警、原产地单证风险结果查询、统计分析、识别过程查看、数据分发、专家研判反馈、绩效录入反馈。税管局可以使用样本数据补充、冲突预警、原产地单证风险结果查询、统计分析和识别过程查看功能。直属海关可以使用数据分发、原产地单证风险结果查询、统计分析和识别过程查看功能。隶属海关可以使用专家研判反馈、绩效录入反馈、统计分析和识别过程查看功能。
2.3.3 状态图
状态图同样遵循“三步法”流程,使用大模型生成原型和反向生成文字步骤一致,初版状态图如图6所示,但其效果并不理想。所以需要增加隐藏空白的描述,优化内容如下:
隐藏为空描述,调整箭头方向及文字描述。经过调整状态图得到了优化,使得状态图更加规范和标准,最终状态图如图7所示。
以下是对给定 PlantUML 状态图的文字描述:起始状态为“提货中”,当货物运抵后进入“验核中”状态。如果验核成功,则进入“验核成功”状态,流程结束;如果验核失败,会进入“外方确认可修改”状态。在“外方确认可修改”状态下,如果外方确认可以修改货物,就进入“货物修改中”状态。在“货物修改中”,若验核成功,又会回到“验核成功”状态并结束流程。如果从 “验核失败” 状态直接外方确认失败,就会进入“外方确认失败”状态,然后流程结束。
2.4 实践启示
通过大模型与UML的深度结合,能够辅助技术人员快速生成时序图、状态图、用例图等标准化模型,这一实践表明:AI与可视化建模工具的协同创新,正在重塑软件需求分析的过程。大模型凭借其强大的自然语言解析能力,能够从模糊需求中精准提取参与者、事件、状态迁移等要素,解决了自然语言到形式化模型的语义鸿沟问题,而PlantUML则通过代码化建模语言实现了模型的自动化生成与动态演化。两者的融合不仅提升了需求分析与人工绘图效率和软件需求编写质量,更通过模型与需求的双向追溯机制,验证了“需求即代码”(Requirement-as-Code)的可行性,标志着软件需求分析从人工经验驱动向智能化、自动化、可验证的方向演进,为复杂系统的可信开发提供了可扩展的技术支撑。
3 结语
本研究构建了一种软件需求分析方法,即“需求感知-语义建模-动态验证”方法,通过使用大模型和UML等可视化工具,验证了该方法的实现路径。该方法能够帮助技术人员完成相关模型绘制及文档编写工作,这不仅提升了技术人员绘图效率和软件需求文档编写质量,更通过“需求-模型-代码”的全链路追溯,为复杂系统的可信开发奠定了结构化基础。未来,随着多模态交互、自优化模型库等技术的演进,还能将海关业务要素数字化底账中的知识灌输给大模型,辅助业务和技术人员编制海关业务需求说明书和海关软件需求规格说明书,这将在本质上重构人机协同的需求分析模式,为智能时代的软件工程实践提供理论指引与技术参考。
参考文献
[1] Ivar Jacobson, Gradybooch, James Rumbaugh. 统一软件开发过程[M]. 北京机械工业出版设, 2002: 23-35.
[2]冯雪. 信息系统需求变更管理研究[D]. 成都: 西南交通大学, 2012.
[3]王飞, 杨志斌, 黄志球, 等. 基于限定自然语言需求模板的AADL模型生成方法[J/OL]. 软件学报, 2018, 29(8): 2350-2370. http://www.jos.org.cn/1000-9825/5530.html.
[4]李淑华. 面向智能物流的敏捷需求分析方法的应用研究[D].武汉:武汉理工大学[2025-06-06]. DOI: CNKI:CDMD: 2.1015.001533.
[5]赵冰, 郑乐乐. DeepSeek赋能思政引领力的逻辑、机理与实践进路[J/OL]. 四川轻化工大学学报, (2025-01-13)[2025-03-21]. http://kns.cnki.net/kcms/detail/51.1793.C.20250320.1348.002.html.
[6]刘雪婷. 聚焦ChatGPT: 核心技术、现实问题与展望[J]. 信息系统工程, 2025(2): 79-82.
[7]上善若水. 大模型进入APP混战时代,通义千问们路在何方[N]. 电脑报, 2023-11-13(040). DOI:10.28184/n.cnki.ndina. 2023.000819.
[8]许涵斌. 面向开源代码的UML模型库构造方法[D]. 南京: 南京大学, 2016.
[9]唐辉芃. 基于模型驱动的代码生成技术研究与实现[D]. 成都: 西南科技大学, 2024. DOI:10.27415/d.cnki.gxngc.2024. 000675.
[10]戴莉萍, 王文乐. UML实验中点放式建模与编程式建模探讨[J]. 软件导刊, 2021, 20(8): 221-225.
[11]陈娟. 基于UML的面向对象的系统分析与设计[D]. 武汉: 武汉理工大学, 2005.
[12]赵会盼. 一种基于UML的面向对象的软件需求分析方法[J]. 电子技术与软件工程, 2021(9): 63-65.
第一作者:杨德辉(1978—),男,汉族,北京人,硕士,高级工程师,主要从事数字政府、信息化标准、国际技术合作、软件开发及需求管控等相关工作,E-mail: 534164338@qq.com
通信作者:冯立胜(1971—),男,汉族,北京人,本科,高级工程师,主要从事软件开发、运行维护、架构设计与管控工作,E-mail: fenglisheng@139.com
1. 全国海关信息中心(全国海关电子通关中心) 北京 100005
2. 北京中海通科技有限公司 北京 100023
1. National Information Center of GACC (General Administration of Customs of China), Beijing 100005
2. China CUSLINK Co., Ltd., Beijing 100023
表1 传统UML工具与PlantUML对比表
Table 1 Comparison table between traditional UML tools and PlantUML
对比维度 | 传统UML工具 | PlantUML |
交互方式 | 图形界面拖拽操作 | 类代码文本描述自动生成图表 |
版本控制 | 二进制文件难追踪差异 | 文本文件易于Git管理 |
学习难易度 | 需熟悉复杂界面和操作流程 | 掌握语法即可 (类似基础Python) |
自动化能力 | 手动通过图形化界面调整 | 可AI直接辅助生成 |
成本 | 多为商业软件(费用较高) | 免费开源 |
表2 大模型综合对比表
Table 2 Comprehensive comparison table of large models
模型 | 语法规范性 | 复杂图表支持 | 中文适配性 | 错误修正能力 | 适用场景 |
(3.0) | ★★★★☆ | ★★★★☆ | ★★★☆☆ | ★★★★☆ | 国际化项目 |
(Qwen3-32B) | ★★★☆☆ | ★★★☆☆ | ★★★★☆ | ★★★☆☆ | 云架构设计 |
DeepSeek-R1 | ★★★★☆ | ★★★★☆ | ★★★☆☆ | ★★☆☆☆ | 标准合规建模 |
(v1-32k) | ★★☆☆☆ | ★★☆☆☆ | ★★★★☆ | ★★☆☆☆ | 移动端轻量应用 |
注: “★”代表适用; “☆”代表不适用.
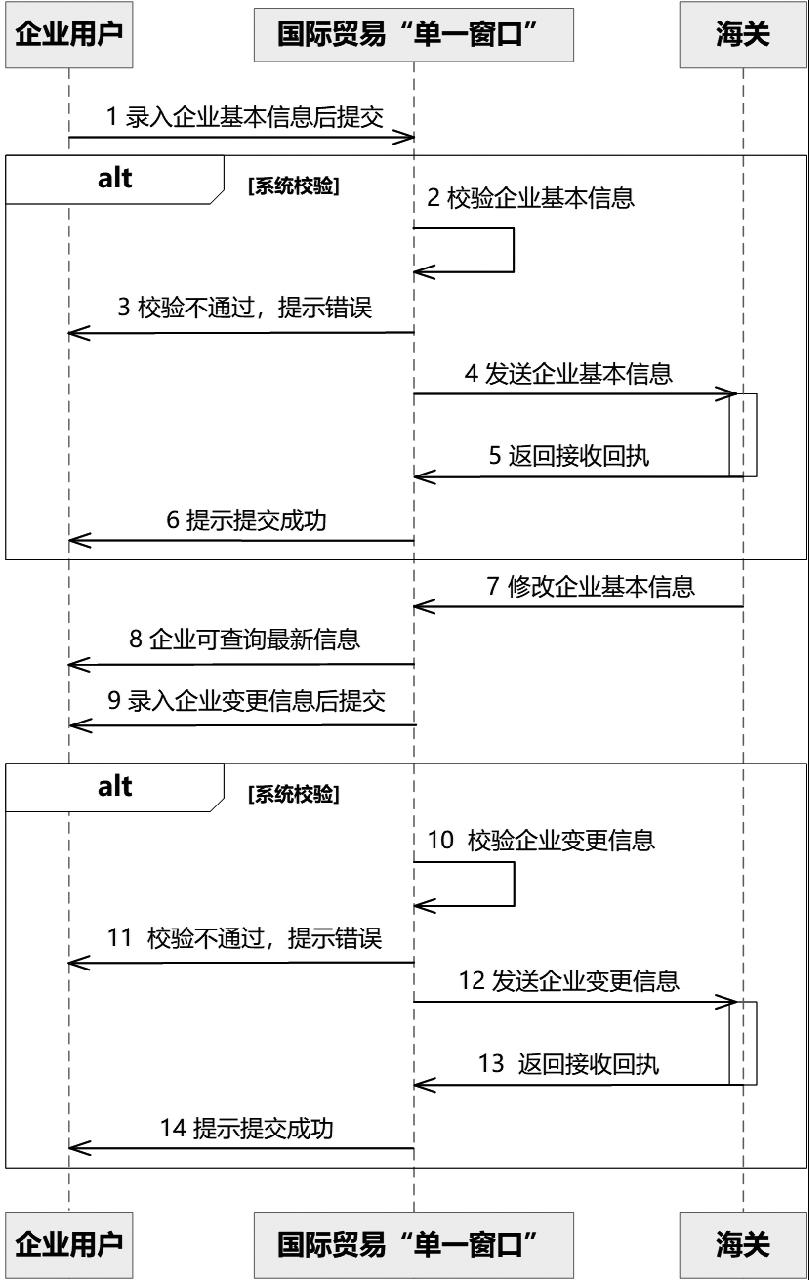
图2 优化后时序图
Fig.2 Optimized sequence diagram
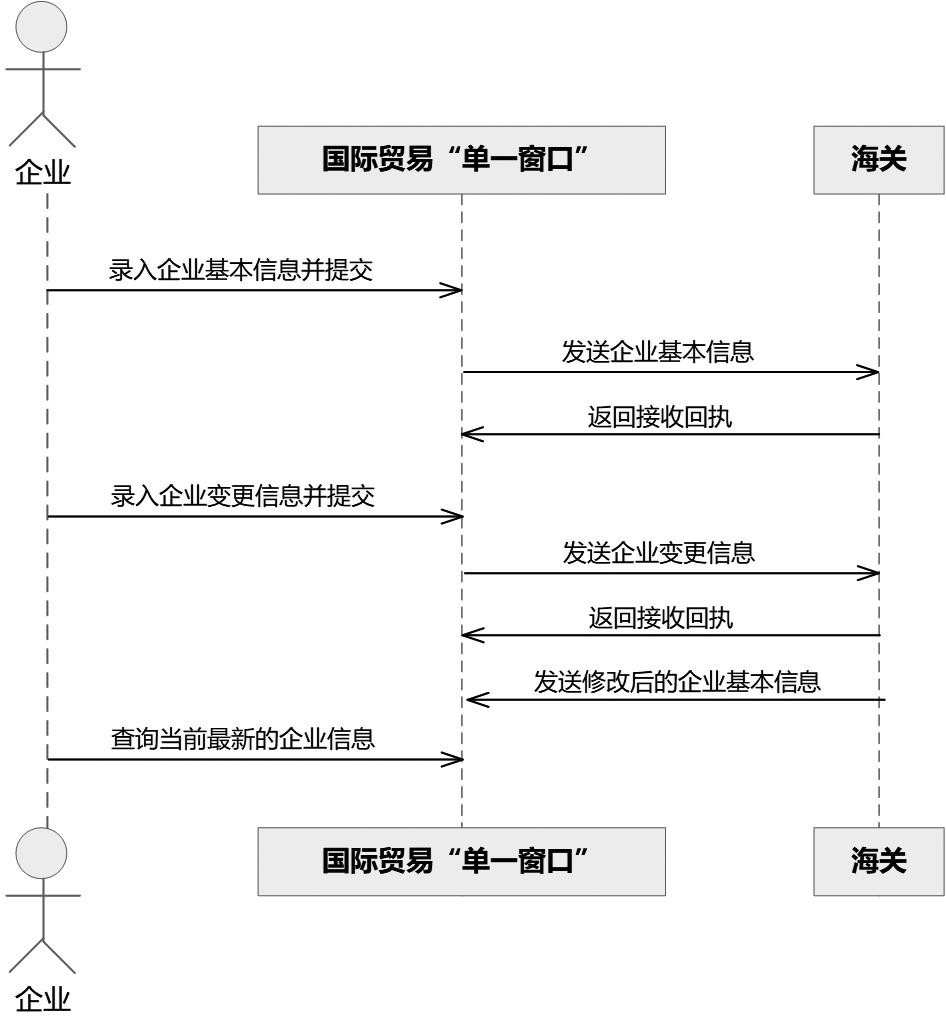
图1 PlantUML生成的初版时序图
Fig.1 Initial sequence diagram generated by PlantUML
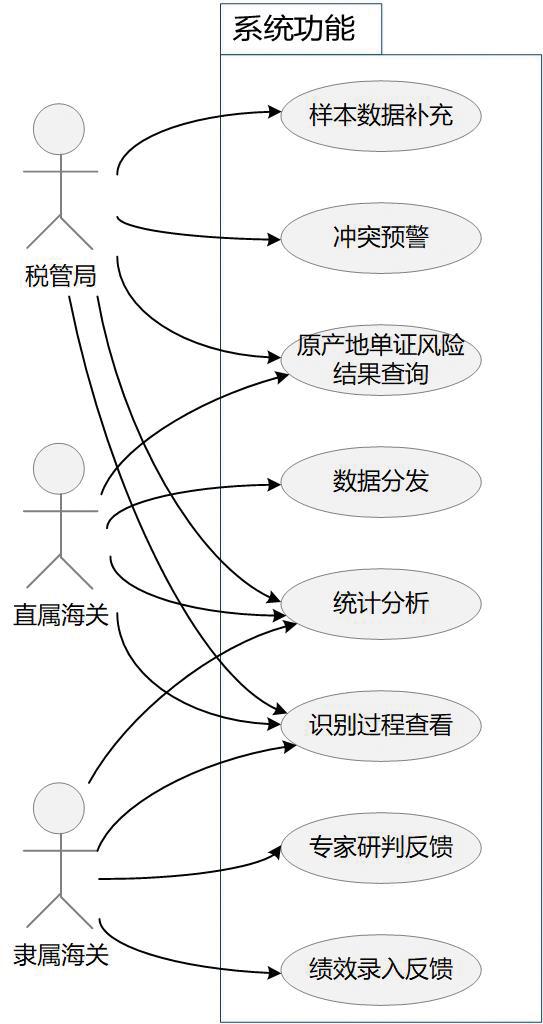
图3 PlantUML生成用例图
Fig.3 Use case diagram generated by PlantUML
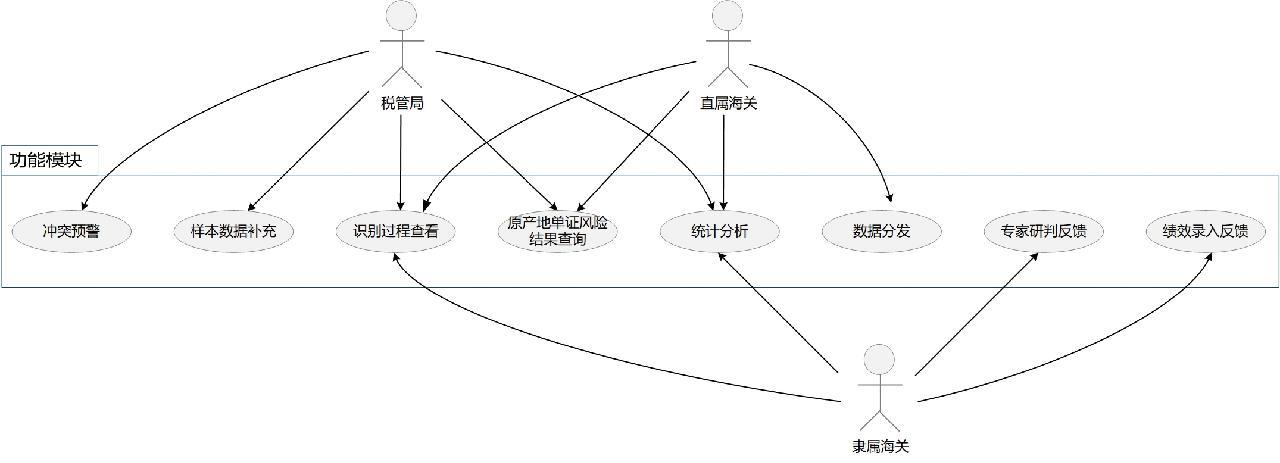
图4 调整后用例图
Fig.4 Adjusted use case diagram
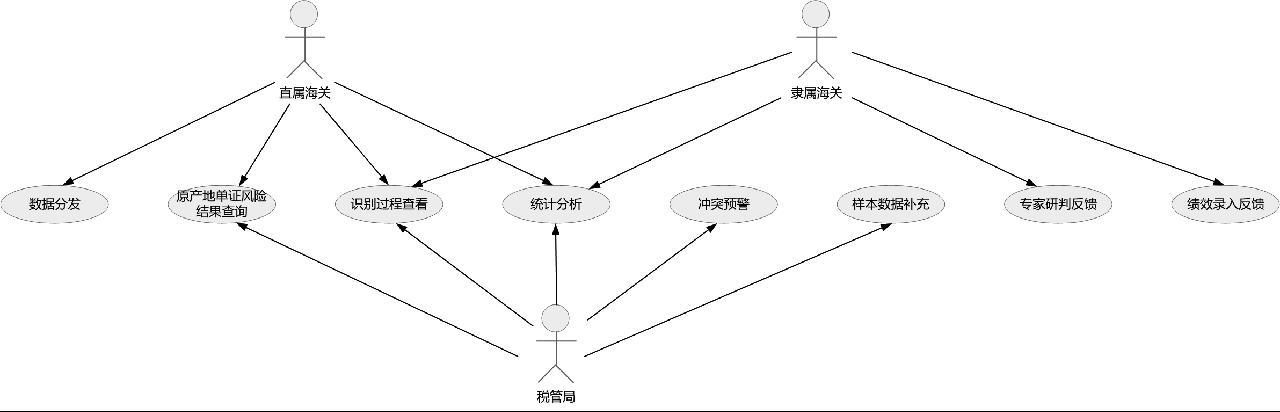
图5 优化后用例图
Fig.5 Optimized use case diagram
图6 PlantUML生成状态图
Fig.6 State diagram generated by PlantUML
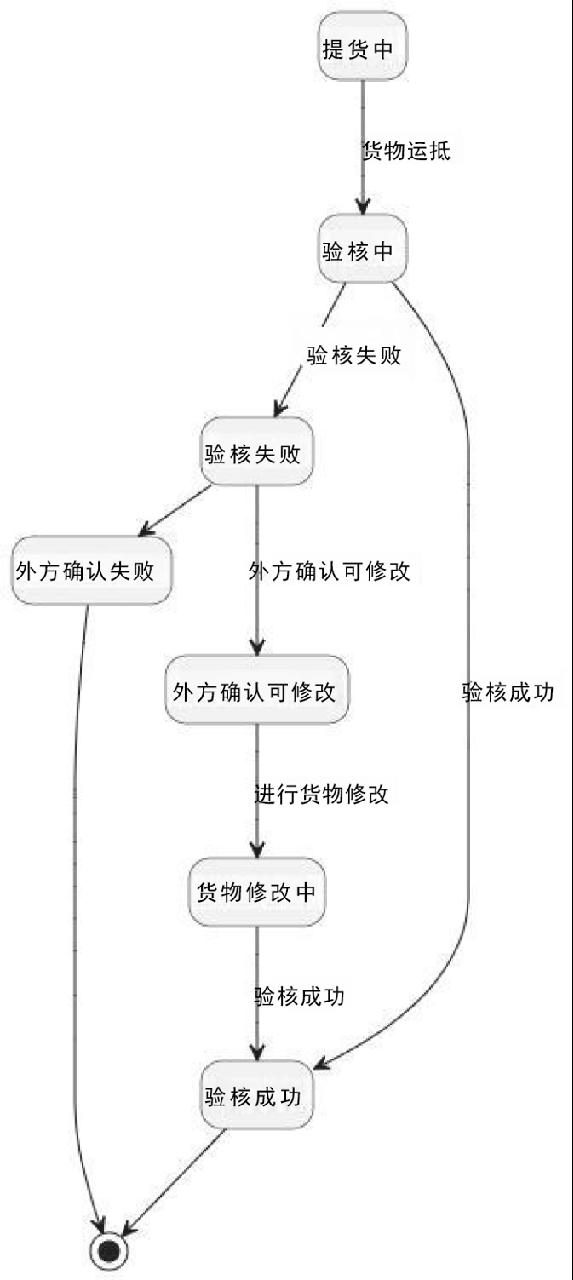
图7 优化后状态图
Fig.7 Optimized state diagram
第7卷 增刊
2025年7月
应用开发 / Application & Development Inspection
微服务架构在海关信息化建设中的应用实践
李 飞 1 李志鹏 1 孙 培 1
摘 要 本文系统梳理了微服务架构在海关信息化建设中的实践路径与方法,结合容器化、服务通信、分布式计算与云原生等关键技术,构建了标准化、模块化的应用开发体系,可为海关复杂业务场景下的分布式系统构建提供支撑。首先,本文分析了微服务架构发展的技术驱动力,明确了海关微服务应用的开发技术路线与设计原则;其次,结合海关微服务架构的落地部署,解析了前后端分离、服务拆解、注册发现、配置管理与服务治理等关键能力的系统设计;最后,结合分层SDK与公共组件库的建设经验,提出组件化、可运营、可持续的支撑框架体系。研究成果为行业级复杂业务系统构建提供了参考,对保障微服务架构的可扩展性、可维护性与标准化具有实践价值与推广意义。
关键词 微服务架构;容器;云原生;统一开发框架;组件库;软件开发工具包
Application and Practice of Microservice Architecture in Customs Informatization Construction
LI Fei 1 LI Zhi-Peng 1 SUN Pei 1
Abstract This paper systematically reviews the practical paths and implementation strategies of microservice architecture in customs informatization construction. Leveraging key technologies such as containerization, service communication, distributed computing, and cloud-native platforms, a standardized and modular development system has been established to support distributed systems under complex customs control scenarios. The paper first analyzes the technological drivers behind the evolution of microservice architecture and outlines the technical roadmap and design principles adopted in customs applications. It then examines the practical deployment of the microservice architecture, focusing on system design aspects such as frontend-backend separation, service decomposition, service registration and discovery, configuration management, and service governance. Furthermore, based on the development experience of layered software development kits (SDK) and common component libraries, the study proposes a component-based, operable, and sustainable framework. These practices offer valuable references for building large-scale business systems and contribute to improving the scalability, maintainability, and standardization of microservice architecture in the public sector.
Keywords microservice architecture; containerization; cloud-native; unified development framework; component library; software development kit (SDK)
海关统一应用开发架构作为海关信息化建设的重要成果,采用云计算、微服务技术,对海关信息化技术服务能力和业务服务能力予以深度整合,构建了标准化、模块化的技术体系,为信息化应用建设和运行提供了强大的公共支撑能力。
1 微服务架构发展的技术驱动力
微服务架构的普及伴随着一系列关键技术的成熟与发展,这些技术共同构成了微服务架构落地的基石,推动了其从理论走向实践,并最终成为主流的应用开发架构。
(1)容器技术的兴起为微服务架构提供了稳定的运行环境。Docker等容器技术通过轻量级的虚拟化方式,实现了应用及其依赖的标准化打包和部署,解决了微服务架构下服务数量庞大、环境复杂带来的挑战。容器技术的快速启动、资源隔离和弹性伸缩等特性,完美契合微服务架构对敏捷性、可扩展性和资源利用率的需求。
(2)服务网络通信技术,尤其是网络虚拟化的发展,为微服务架构在开发与运维过程中的可靠性与灵活性提供了坚实支撑。通过虚拟网络对服务通信路径的抽象,微服务之间的连接不再依赖底层物理网络配置,极大简化了部署与拓扑调整的复杂度。表述性状态转移应用程序编程接口(Representational State Transfer Application Programming Interface,RESTful API)、高性能远程过程调用框架(Remote Procedure Calls,gRPC)等高效通信协议简化了服务之间的数据交互[1-2],进一步实现了服务通信逻辑与业务代码的完全解耦,通过统一提供负载均衡、服务发现、熔断限流、安全控制等服务治理能力,显著提升了微服务系统的可观测性、可维护性和故障应对能力。
(3)分布式计算技术的成熟为微服务架构提供了坚实的理论基础和实践经验。分布式数据库、分布式缓存等技术解决了微服务架构下的数据一致性和性能问题,而分布式事务框架保障了跨微服务的数据一致性。这些技术的发展有效应对了微服务架构带来的分布式系统复杂性挑战。
(4)云原生技术的发展进一步加速了微服务架构的普及。容器编排引擎(Kubernetes,K8s)等容器编排平台简化了微服务的部署和管理[3-4],开发与运维(Development and Operations,DevOps)理念和实践则促进了开发和运维的协同,提升了应用的交付效率。此外,基础设施即服务(Infrastructure as a Service,IaaS)和平台即服务(Platform as a Service,PaaS)的成熟也为微服务架构提供了强大的基础设施支持。IaaS提供了弹性的计算、存储和网络资源,使得微服务能够根据需求动态扩展;PaaS则通过提供消息队列、API网关、服务注册发现、日志管理等托管服务,提高了微服务应用的开发和运维效率。
总之,通过容器、服务通信网络、分布式计算和云原生等关键技术的革新,共同推动了微服务架构的普及。这些新技术解决了微服务架构落地过程中遇到的各种挑战,使其能够更好地满足应用开发对敏捷性、可扩展性和可维护性的需求。目前微服务架构已成为海关信息化建设主要的分布式开发架构。
2 微服务应用开发技术路线与设计原则
在基于微服务架构开展应用开发时,遵循明确的技术路线和设计原则至关重要。通过建立一个统一、高效、可靠的开发架构和支撑框架,可以进一步提高应用开发效率、提升代码质量、降低维护成本、增强系统的稳定性。海关信息化应用在使用微服务架构研发时,需遵循7项关键技术路线与设计原则。
(1)采用B/S架构与前后端分离模式。海关信息化应用采用B/S架构,前端使用Node.js开发环境,技术栈包括Vue、TypeScript和JavaScript;后端采用Java语言,基于SpringCloud和SpringBoot构建。前后端分离的设计使得前端和后端可以独立开发、测试和部署,降低了系统耦合度,提升了开发和维护效率。同时,这种模式能够更好地支持多端适配和快速迭代,满足业务灵活性和扩展性需求。
(2)基于平台化原则开发。海关信息化应用依托海关应用云平台、海关大数据云平台和移动支撑平台进行开发。通过海关应用云平台和电子口岸PaaS平台,发布统一定制化的开发脚手架,为微服务应用提供一致的环境和工具链。这种平台化开发模式能够显著降低开发和运维复杂度,提升资源利用效率,并确保系统的一致性和标准化。
(3)符合国产化环境要求。在应用开发架构设计时,需严格遵循国产化硬件、操作系统、数据库、中间件和浏览器的相关技术要求。通过国产化适配,提升系统的自主可控性和安全性,降低对国外技术的依赖,保障业务连续性和数据安全,同时满足政策合规性要求。
(4)优先选用海关已采购的第三方产品。对于分布式缓存、消息队列(Message Queue,MQ)、全文检索、实时计算、NoSQL数据库和时序数据库等第三方产品,优先选择已采购的产品。对于超出已购范围的产品,需从必要性、技术成熟度、技术支持可获得性、资源需求、授权费用等多维度进行评估。这一原则主要为了降低技术选型风险,减少采购和维护成本,同时确保系统的稳定性和可扩展性。
(5)通用业务与技术能力的封装复用。对于具有通用性的业务或技术能力,按照服务化思想进行设计和建设,确保功能的可复用性和处理效率。服务接口以RESTful API方式对外提供,并纳入海关能力目录统一管理,其他应用可通过HTTP+JSON方式进行调用。通过通用能力的封装和复用,减少重复开发,提升开发效率。
(6)遵循高内聚、低耦合的设计原则。每个微服务应专注于单一业务功能,服务之间通过RESTful API接口、数据报文、消息队列或者海关事件发布平台进行通信。高内聚、低耦合的设计能够提高系统的模块化程度,降低服务间的依赖,便于独立开发、测试和部署。
(7)强化安全集成约束设计。应用集成海关H4A平台实现身份管理、认证授权和用户登录;使用统一审计日志平台实现日志记录和监控告警;采用支持国密的统一密码服务,实现数据存储加密、传输加密、签名和验签等功能;对重要数据和核心数据采取技术保护措施。通过强化安全设计,保障微服务应用的安全性,满足海关信息化系统对数据安全的高要求。
总之,通过明确的技术路线与设计原则,使得应用能够在微服务架构下实现高效开发、稳定运行和灵活扩展。这些原则不仅提升了系统的可维护性和可扩展性,还降低了开发和运维成本,为应对业务的持续发展和复杂需求提供了有力支撑。同时,国产化要求和安全设计的强化进一步保障了系统的自主可控性和安全性,为信息化建设奠定坚实技术基础。
3 微服务开发在海关的实际落地架构
微服务架构相较于传统单体架构主要在两个方面具有优势,一是微服务架构具备独立部署与维护的特性,能够有效控制故障影响范围,避免因局部问题导致整个系统崩溃。二是微服务架构凭借轻量级通信协议,实现了更为高效的服务间通信,并可依据业务需求动态扩展服务实例,提高服务开发治理的效能。
目前,微服务架构已经成为海关信息化应用建设的主流架构,H2018通关管理系统已基于微服务架构重构,通过将复杂的应用拆解成多个小型、独立的服务模块(例如计税、修撤、验估、放行、结关等微服务),每个模块负责特定的业务功能,并能够独立部署、扩展和维护,提升应用业务快速变化的技术响应能力。本文结合图1所示对微服务架构的实现原理和关键模块进行阐述。
目前的微服务应用开发架构中已实现落地的模块构成包括前端模块(Web服务)、后端微服务模块(Service服务)、服务注册与发现、配置中心、健康检查与监控以及后台作业处理等多个组件。架构图中Framework-web(海关作业系统统一入口)、aaa-main-web和bbb-main-web代表了应用的前端,它们处于同一层级,分别负责不同的应用前端程序。用户通过域名访问应用集群的入口,通过ALB反向代理将用户请求转发到对应的应用前端程序[5]。所有应用前端当要通过后端服务获取、处理数据时,通过访问统一的Web网关将请求发送给应用后端进行处理,实现应用系统基本的前后端分离设计模式。
部署在集群中的应用后端由多个部署组及微服务构成,如图1所示aaaa-main-service、bbbb-main-service、cccc-main-service等分别代表了一个微服务。这些微服务负责实现具体的业务逻辑,每个服务分别单独部署,并通过架构抽象层(图中标记为蓝色的file-service、heps-api-service、heai-api-service等公共SDK和公共服务)访问后台Redis缓存数据库、交易型和分析型数据库、MQ和文件系统等各类存储介质。
服务之间通过Feign通信客户端进行调用,Feign作为声明式HTTP客户端简化了服务间调用的复杂度,提升了微服务间的协作效率。在微服务通信的过程中,Web网关(处理携带用户登录信息的请求)和应用网关(处理不携带用户登录信息的请求)作为流量的中转站,负责将前端的请求转发给相应的后端服务。
在海关的微服务架构中广泛应用了容器技术,所有的微服务都在Docker容器中运行,海关应用云平台(微服务PaaS平台)负责进行容器编排和管理,实现服务实例的动态调度、扩展以及负载均衡,保持众多微服务系统在高负载下的稳定性和灵活性。
微服务架构包含服务注册与发现功能,集群里集中部署了服务注册中心,每个微服务实例在启动时都会将自身注册到注册中心,其他服务则通过服务注册中心获取到需要调用的服务实例的地址信息。这种方式保证了微服务的动态扩展与缩减,服务发现机制还使得系统能够根据实际负载自动调整服务实例数量,进一步提高了系统的可用性和灵活性。
微服务架构还包含了配置中心的核心功能,通过配置中心,所有微服务的配置文件可以集中管理,并且支持动态更新,开发人员可以在不中断服务的情况下更新系统的配置,确保不同环境下的配置一致性。为确保服务的健康运行,微服务架构中还引入了健康检查与监控机制[6-7]。每个微服务都定期执行健康检查,系统自动发现并处理异常服务实例,避免用户请求被转发到已宕机的服务。
总之,在海关微服务架构实际部署应用过程中,通过将业务功能模块化、容器化部署、使用服务注册与发现、集中式配置管理以及健康检查与监控等技术,确保了系统的高可用性、灵活性与可维护性。目前,H2018通关管理系统已基本采用微服务架构建设,在平台化运维、应用上线部署效率、资源扩展能力、故障诊断处置等方面相比传统架构均有很大提升,持续保障了通关系统的运行稳定。
4 架构SDK分层研发与应用
在推动微服务架构落地的过程中,研究团队逐渐认识到实施统一的技术架构标准,研发复用标准化的公共组件SDK,可显著降低应用系统对基础功能服务的重复开发,为应用架构自主可控提供了重要抓手。
为实现公共组件SDK在应用开发中的有效利用与高效维护,研究团队提出了一种分层化的组件设计模式,即核心包、扩展包与增强包三层结构[8],按照图2所示,内容包括:
核心包(Core Package)位于SDK分层架构的底层,为微服务应用提供最基础且必需的公共组件,包括服务注册与发现功能、微服务网关、调用链路追踪组件、集中配置管理工具、数据库抽象访问层以及异常统一处理机制等。这些组件属于微服务架构的基础性技术服务,支撑整个微服务体系的稳定运行,因而要求核心包具备极高的稳定性与可靠性,代码质量需满足严格的质量管控标准,防止频繁变动影响整个架构的稳定性。
扩展包(Extension Package)位于核心包之上,主要面向具体业务场景提供更丰富的功能组件。该层包括认证与权限管理模块、分布式事务支持、审计日志记录服务、文件管理服务、数据交接、数据预定接口以及统一作业调度组件。扩展包重点关注组件的业务适配性、通用性和可扩展性以适应不同业务场景(业务类及政务类场景等),从而满足不同业务需求的研发要求。
增强包(Enhancement Package)处于公共组件SDK的最高层,强调对技术平台与第三方工具的深度封装和高度集成,以满足应用在技术能力方面更高级别的需求。增强包包括但不限于对统一门户入口、存储附件平台、工作流引擎的封装,更重要的是涵盖对第三方技术服务平台的集成与封装,例如即时通信、视频会议等主流技术工具。这一层组件的设计重点在于抽象和统一第三方工具的技术接口,屏蔽底层技术差异,降低技术接入门槛,实现统一的技术服务能力供各应用系统便捷调用。
总之,通过设计、研发分层结构的公共组件SDK,明确了不同层组件的功能边界、技术实现目标与质量控制标准,既满足微服务架构对稳定性的基本要求,又能实现对多样化业务场景和复杂技术需求的快速适配,促进应用开发架构的推广落地。
5 公共组件库运营机制的构建
公共组件库的高效运营是保持微服务架构体系可持续发展的重要保障。通过提出公共组件库的闭环运营机制,进一步阐述公共组件库运营机制建设的战略意义与长期效益。具体设计如图3所示。
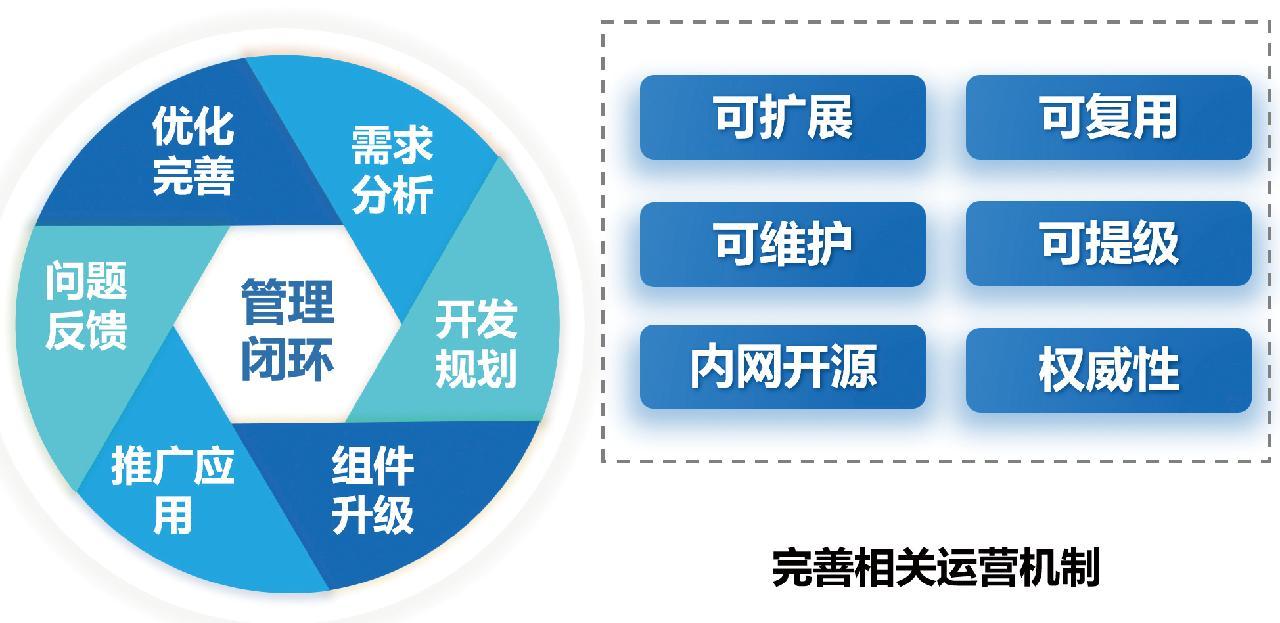
图3 公共组件运营闭环图
Fig.3 Closed-loop diagram of common component operations
公共组件库闭环运营涵盖需求分析、开发规划、组件升级、推广应用、问题反馈和优化完善6个关键环节,体现了组件库从规划到落地实施再到持续优化的全过程管理模式。通过从管理部门、实施单位、研发技术人员反馈、技术合作方等渠道收集、分析公共组件的技术需求,为公共组件的开发规划提供明确的方向和依据;通过版本管理和功能迭代,保持公共组件的持续优化与升级,用以适应业务与新技术的快速变化;通过从署级、关级实际应用项目中吸纳优秀组件,并改造提升为公共组件,不断丰富完善组件库内容;通过积极的宣传、培训和示范应用等手段,加快组件库在署级项目中的广泛应用。
问题反馈环节应注重构建有效的问题收集渠道和快速响应机制,确保在组件使用过程中发现的问题能够迅速得到处理与解决。最终,通过优化完善阶段,将反馈意见和积累的知识经验纳入组件的持续改进中,形成长期有效的良性循环。
公共组件库运营强调可扩展、可复用、可维护、可升级、内网开源和权威性6个方面的关键特征。可扩展性使组件能够快速适应不断变化的业务需求与技术环境;可复用性保证组件能够广泛应用于不同的业务项目,有效避免重复开发;可维护性着重强调组件的长期稳定运行和低维护成本;可提级可转化性使得组件库能够吸纳优秀的项目成果,持续丰富技术与业务能力,内网开源机制则鼓励开发资源的开放共享,增强团队之间的协作互动;权威性特征通过制定明确的标准规范与严格的质量控制体系,保证组件库的可靠性和可信赖性,进一步提升成果质量。
总之,通过构建实施闭环运营机制并按照6个方面的目标推进实施,保障开发技术资源的利用效率,保持微服务架构体系的长期稳定和可持续发展。
6 展望
随着新一代信息技术的持续演进,微服务架构已成为支撑大型复杂业务系统建设的重要基础。在海关信息化体系的建设过程中,通过引入以容器化、服务通信、分布式计算和云原生技术为核心的微服务架构,初步实现了架构标准统一、开发运维解耦、系统弹性伸缩与服务可观测性的提升。
本文结合海关应用场景,系统性总结了微服务架构的关键技术支撑、开发原则与落地实践,从架构设计、组件复用、SDK分层开发到组件运营闭环,全面展示了微服务架构在海关信息化建设中的工程化推进路径与阶段性成效。实践证明,统一的架构治理体系不仅显著提升了系统的可维护性与敏捷交付能力,也为技术服务能力的持续演进提供了坚实基础。
面向未来,随着业务的不断复杂化和数字化转型深入推进,海关信息化系统需进一步加强研发生态运营、技术平台自主可控能力建设以及微服务治理的智能化水平,从而在复杂业务环境下持续构建安全、稳定、灵活、高效的技术支撑体系,全面支撑海关信息化建设迈向更高阶段。
参考文献
[1] Richardson C. Microservice Patterns and Best Practices: Designing Fine-Grained Systems [M]. Manning Publications, 2019.
[2]腾讯云. 腾讯云微服务实践白皮书[EB/OL]. https://cloud.tencent.com/developer/article/2425592?policyId=1004.
[3]腾讯云. 腾讯云容器服务TKE微服务治理指南[EB/OL]. https://cloud.tencent.com/document/product/649/16621.
[4] Davis C. Cloud Native Design Patterns: Building Applications and Systems with Containers Serverless and Cloud Foundry [M]. O’Reilly Media, 2019.
[5]张逸. 基于Spring Cloud的微服务落地. Java技术栈[EB/OL]. 2018-04-06. http://zhangyi.xyz/micro-service-based-on-spring-cloud/.
[6]侯诗军. 腾讯云原生微服务治理实践及企业落地建议.微信公众号[EB/OL]. 2024-09-17. https://mp.weixin.qq.com/s?__biz=MjM5MDE0Mjc4MA==&mid=2651219064&idx=3&sn=8c94ae8b59cb48b1ba7b74ebab5c2d2d&chksm=bc4a44d6bee21fbf8d7acacc454f626cc9e27a43c96da7e8648c4803a516789e6d66729a2dda#rd http://theory.people.com.cn/n1/.
[7] Allen.Wu.微服务化框架的模型和治理能力设计后端系统和架构[EB/OL]. 2023-01-03. https://cloud.tencent.com/developer/article/2230713?policyId=1004.
[8]杨勇.微服务框架落地实践之路. EAWorld[EB/OL]. 2016-10-17. https://cloud.tencent.com/developer/article/1081301?policyId=1003.
第一作者:李飞(1982—),男,汉族,北京人,本科,主要从事海关作业类系统开发测试工作,E-mail: lifei@mail.customs.gov.cn
1. 全国海关信息中心(全国海关电子通关中心) 北京 100005
1. National Information Center of GACC (General Administration of Customs of China), Beijing 100005
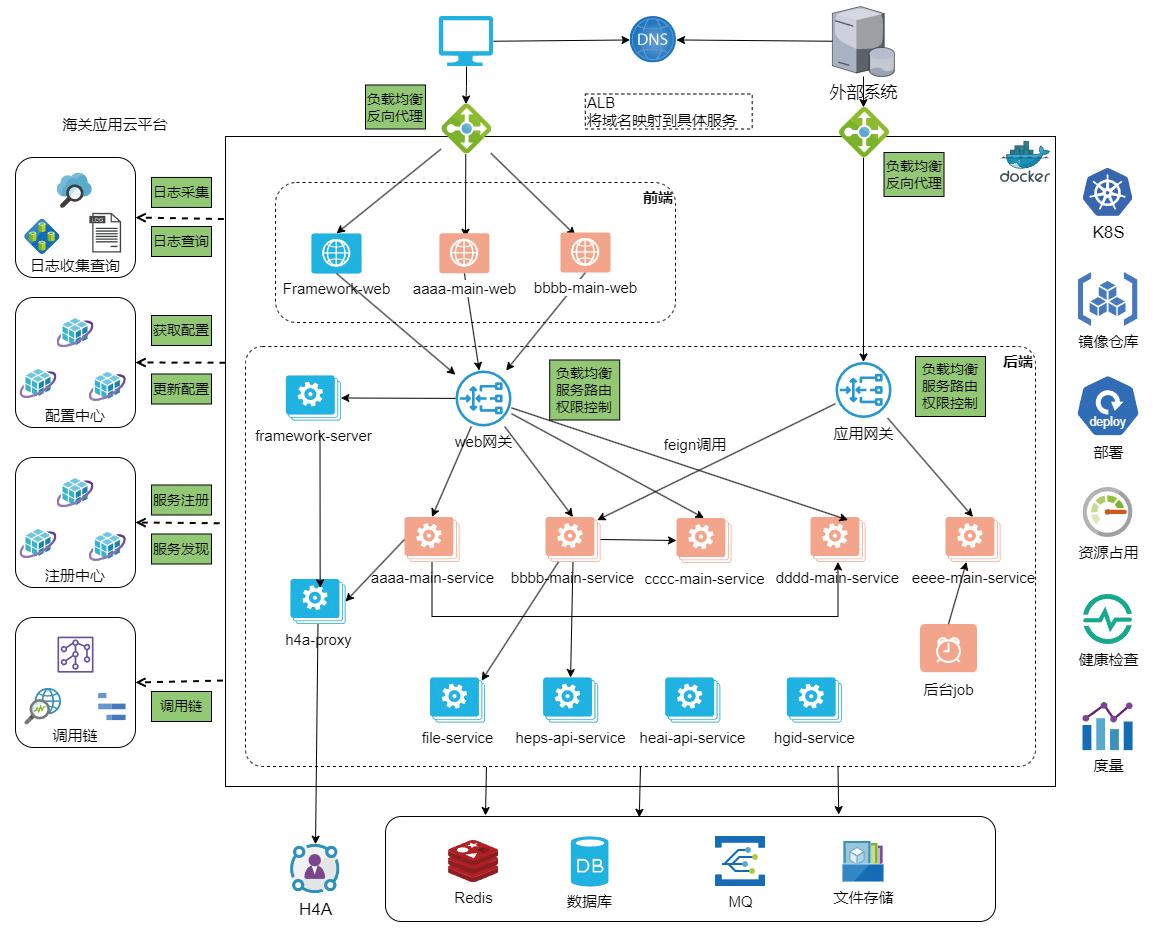
图1 微服务应用架构示意图
Fig.1 Application architecture diagram of microservice
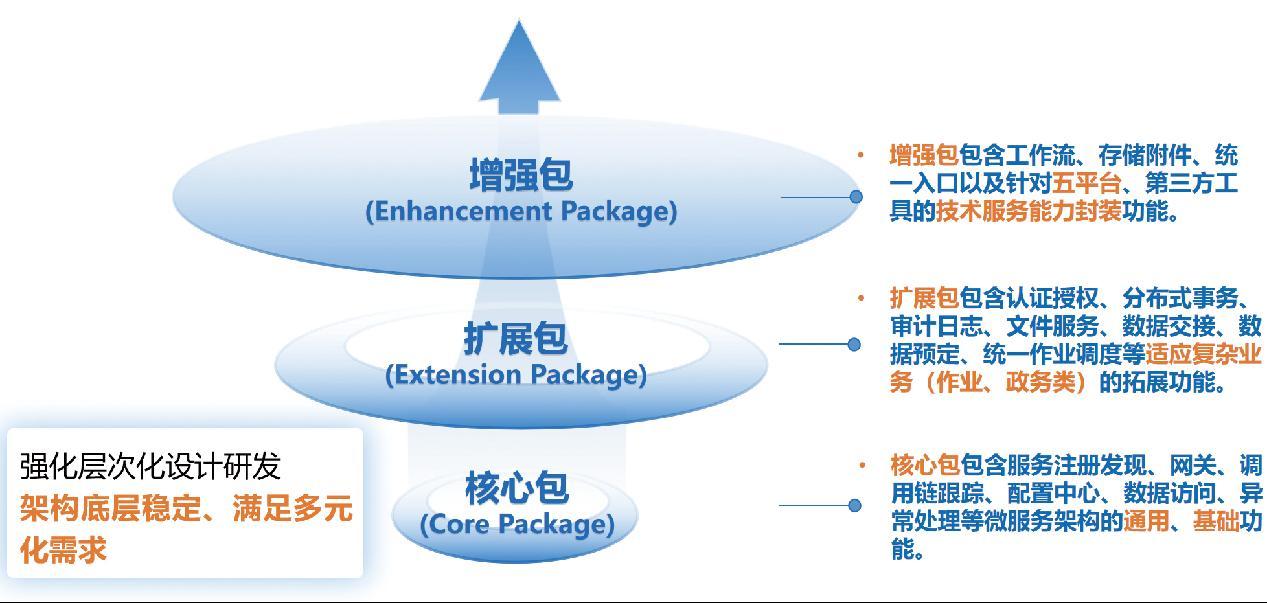
图2 架构SDK分层图
Fig.2 Layered architecture diagram of SDK
第7卷 增刊
2025年7月
Application & Development Inspection / 应用开发
海关政务应用整合技术研究与设计
顾 岩 1 袁 勇 1 李 俊 1 吴 奇 1 单春磊 1
摘 要 海关政务信息化建设起步较早,经过多年努力,各业务领域已建立了完整的应用。然而,这些应用大多相互独立,为加强系统间交互协同,政务应用整合技术应运而生,成为提升服务效率、优化业务流程、实现数据互联互通的关键手段。本文深入研究政务应用整合技术,设计基于海关云平台、微服务架构、应用集成技术的政务应用整合方案,为海关政务应用整合持续建设提供有益参考。
关键词 政务应用;应用集成;消息集成;流程引擎;云平台;容器化
Research and Practice on Integration Technology of Customs Administration Applications
GU Yan 1 YUAN Yong 1 LI Jun 1 WU Qi 1 SHAN Chun-Lei 1
Abstract After years of efforts, the customs has established a complete application in various fields of government affairs. However, most of these applications are independent of each other. In order to effectively solve these problems, government application integration technology emerged and became a key means to improve service efficiency, optimize business processes and achieve data interconnection. This paper conducts an in-depth study on the integration technology of government affairs applications and designs a government affairs application integration scheme based on the customs cloud platform, microservice architecture and application integration technology, providing a useful reference for the continuous construction of application integration of customs affairs.
Keywords customs administration; application integration; information integration; process engine; cloud platform; container
随着海关政务信息化、数字化建设的深入推进,各类政务应用从分散化、碎片化逐步向集约化、一体化转型。传统政务系统因建设时间不同、技术框架各异、数据标准不统一,系统相对独立,在进行跨部门业务协同、跨系统数据共享方面有待改进。在此背景下,政务应用整合技术成为解决上述问题的关键路径,通过整合异构系统、优化业务流程,实现政务应用的一站式办理,提升政务应用协同性和高效性,推动政务信息化向更高水平发展。本文旨在深入探究政务应用整合的关键技术,结合海关实际需求设计一套科学、合理、可行的政务应用整合方案,为海关政务应用整合建设提供有力支撑。
1 海关政务应用整合现状
1.1 应用概况
海关政务应用是海关政务管理部门应用信息化技术,借助海关科技力量自主研发或外部资源采购等方式建设的应用项目,这些应用在海关内部环境搭建部署,并与海关统一身份、统一认证和统一授权体系集成,部分应用通过菜单链接、消息集成等方式进行初步整合,为全国海关用户提供各类政务信息化服务,为海关垂直管理、服务职能提供支撑。应用分类情况见表1。
1.2 面临的现状
当前海关各类政务应用数量众多、种类繁杂,在提升政务工作效率方面发挥了一定作用,但仍存在一定的提升空间。一方面,不同时期、不同部门建设的政务应用相互独立,整合的功能还有待完备,以更好地支撑政务应用整体的整合要求。例如,办公应用对外提供配置和接口,可快速添加菜单并集成待办事项,但对事项的批量操作功能还有待完善,对服务集成能力、容错能力还有待提高。另一方面,不同部门的政务应用往往是基于各自业务需求所开发的,应用界面风格、操作标准并不一致,增加了使用难度及后期运维成本。例如,同名的表单要素在不同应用界面有不同的业务含义,同类操作按钮存在操作时序差异,影响了用户体验;同一功能的修改需在不同的技术平台实现,增加了技术复杂度。此外,由于各类应用的数据格式、接口标准也不统一,对政务服务效能的进一步提升也会产生一定影响。
1.3 整合意义
政务应用整合旨在将分散的政务应用进行有机融合,实现“一站式”政务服务和管理。其目标包括消除系统孤立现象,促进数据共享与流通,使各部门能够实时获取所需信息,为决策提供全面数据支持;优化业务流程,打破部门间的业务壁垒,实现业务协同办理,提高政务服务效率和用户体验。政务应用整合是政务服务数字化转型的基础,为构建高效、便捷、智能的政务服务体系提供支撑。
2 海关政务应用整合技术研究
2.1 技术思路
遵循国家关于政务信息系统整合方面的政策方针,按照海关信息化建设总体要求,充分利用海关现有技术体系,加强海关政务应用顶层设计,做好架构管控,以深度整合海关各类政务应用为目标,构建完备的政务应用体系,从用户视角出发,打造一体化的政务平台[1-3],实现各类政务应用的统一管理。依托海关现有政务应用建设成果,本文从以下几方面开展研究。
2.1.1 清理老旧应用
对各类在线运行的政务应用开展自查,对于用户长期没有访问、与实际业务长期脱节、服务端资源长期处于空闲、运行维护工作长期停滞的应用,考虑进行清理下线,回收或报废相关硬件资源。对于功能已被其他应用替代、未完成历史数据迁移、存在新旧双轨运行期的应用,考虑加速新应用替代进程,逐步开展旧应用下线。
2.1.2 统一技术架构
通过标准化、服务化、集成化的顶层设计,将分散的政务应用、数据服务、资源组件等进行有效整合,构建可复用、可扩展、可快速集成、可灵活部署且适用于政务应用的技术底座,提供统一技术标准和规范,使不同的政务应用能够在共同的技术平台上进行集成和交互,提高政务应用的效率和质量。
2.1.3 统一应用入口
打破政务应用条线分割的壁垒,将众多分散的政务应用进行整合,为用户提供集中式、一站式的访问通道。通过统一入口,用户可以根据自身需求快速找到日常工作所需各类应用及服务,并根据用户层级、身份、权限、使用偏好等提供个性化定制、自动化推送服务,极大地提升用户便捷性和用户体验。
2.1.4 统一界面风格
按照简洁、易用、一致的原则,规范政务应用界面风格,为用户提供布局合理、界面美观、操作简单的应用界面。视觉体验方面,色彩搭配合理,使用统一的图标、字体、字号等,进行场景化布局,主次分明,避免层级过多、色彩图形堆叠,能够使用户快速聚焦主题;交互体验方面,简化用户操作步骤,操作效果符合用户预期,提供引导示例和帮助文档,方便用户快速上手。
2.1.5 统一应用集成
通过抽取、汇聚、重构政务应用中可重用、可共享的功能和服务[4-5],持续优化并提升政务应用集成服务能力,将不同业务、不同架构、不同功能的政务应用整合到统一的应用场景下,实现界面融合、消息集成、流程共享,实现政务应用服务的一体化和高效化。
2.1.6 统一服务管理
制定政务应用统一数据标准[6-8],规范不同政务应用对同一类基础数据的定义、格式、参数等,确保不同应用的同一类数据在语义、语法上的一致。建立政务应用数据服务管理机制,明确数据服务对接方式,规范传输协议、接口定义、调用标准等,通过整合分散的数据服务接口,促进数据跨部门、跨应用的互联互通。
2.2 关键技术方法
基于上述技术思路,为提高政务系统整合的扩展性、灵活性、可维护性,采用微服务架构方式对政务应用进行拆分,采用的关键技术主要包括微服务架构、界面集成、消息中心、工作流引擎、接口管理等。
2.2.1 微服务架构
微服务架构[9-10]能够有效解决传统政务应用的资源孤立、弹性不足、迭代缓慢等问题,通过容器化、服务化、开发运维一体化等技术,构建弹性、敏捷、安全的政务技术底座。微服务具有模块化、动态化、可扩展的特点,通过对服务注册、发现、负载均衡、熔断与降级等治理机制,保证微服务架构稳定可靠。
2.2.2 界面集成
界面集成是通过统一界面设计、交互的方式,将不同政务应用的菜单、界面等元素整合到一个用户界面的过程,主要包括页面布局集成、嵌入式集成、链接式集成、API接口集成等方式,为用户提供一致的视觉体验和操作感受。
2.2.3 消息中心
消息中心是支撑跨应用实时通信、异步协作、通知预警的核心服务,主要由消息路由、队列存储、流量监控、容错补偿等核心组件构成,支持高并发处理,通过事件驱动触发服务调用,及时、准确地传递给目标用户各类消息。
2.2.4 工作流引擎
工作流引擎是实现跨部门数据流转自动化、标准化、智能化的核心服务,通过图形化定义建模,建立串行、并行、自动节点等工作任务,驱动流程实例执行,通过网关路由、微服务接口支持跨系统服务调用,并根据流程数据挖掘,生成优化建议。
2.2.5 接口管理
规范政务应用接口的设计、开发、测试、版本、发布等全生命周期管理,提供帮助、实例等操作指引,促进团队协作、数据交换共享。
3 海关政务应用整合设计
3.1 总体架构设计
总体架构采用分层设计[10],主要分为底层云平台、应用支撑层、应用功能层、应用集成层和应用展示层,如图1所示。
底层云平台主要依托海关现有基础设施云平台和应用云平台的资源和能力,为应用整合的设计、开发、部署、运维提供环境与支持。
应用支撑层以微服务架构开发、前后端分离的技术体系建设为主,使用容器化及虚机部署模式。应用服务包括消息中心、流程中心、文档中心、文件校对、全文检索、配置中心、短信引擎等服务。应用组件包括在线编辑、在线预览、文档跟踪、意见控件、会签控件、批量上传、机构选择、常用意见、送阅交流等组件,为整个上层应用的正常运行提供技术支撑。
应用功能层主要包括办公、科技、财务、人事、后勤、党建、教培等功能模块,负责接收用户请求、实现业务逻辑并返回处理结果,按照实际业务需求进行定制集成、数据交换等。
应用集成层通过菜单定制、统一样式、消息接口、流程集成等形式对外提供服务能力,实现多应用对接、异构应用集成。
应用展示层为用户提供统一的访问界面,与用户完成交互,按照用户化思维,将要我办、要我看、我要办、我要查的内容予以集中展示,并提供收藏、关注、提醒等辅助功能,支持个性化设置和系统自动推送。
3.2 政务门户设计
政务门户设计[11]以用户为中心、服务为导向,构建统一、高效、便捷、友好的服务平台。前端展示包括门户网站和用户工作台。门户网站以现有内网网站平台为技术基础开展各类子站建设及替代。用户工作台按照“要我办理的”和“我要办理的”两条主线整合各类消息、功能等,提供预警、收藏、关注、在岗状态、代办设置、统计等辅助功能。
3.3 应用集成设计
海关各类政务应用前期已完成统一身份、认证、授权的集成,本研究将重点对菜单、界面、消息、流程方面进行集成设计。
3.3.1 菜单集成
菜单兼顾不同用户群体使用频率、使用便捷程度,支持动态配置、智能推荐。菜单层级不宜过深,控制在三层之内,方便用户快速查找定位,一级菜单可按照业务主题、主管部门、服务对象等多个维度进行划分,三级菜单为具体事项,点击后通过弹出、内嵌、跳转等方式集成。
3.3.2 界面集成
参照海关信息系统应用界面设计指南相关要求,统一政务应用页面布局、配色方案、字体样式、图标风格、交互方式等内容。
3.3.3 消息集成
消息中心对外提供RESTful API、WebSocket两种协议接口进行消息集成。主要包括消息接收、消息路由、消息补偿、消息查询、新消息提醒、消息转发等。消息主体包含发送人、标题、链接、紧急程度、开始时间、过期时间、接收人等信息。
3.3.4 流程集成
流程中心对外提供RESTful API接口支持应用集成访问。主要包括流程定义、流程跟踪、流程时效、组织机构管理、流程实例管理、权限配置、流程管理等。在接入流程中心前,外部应用使用前须完成应用注册和授权。
3.4 服务管理设计
构建统一服务发布管理平台,实现对各类政务公共服务的统一管理[12],主要包括服务地址、构造说明、版本变化、接入要求、适用场景、帮助手册等。
3.5 部署设计
整合后的政务门户考虑异地容灾方案,在主节点和异地备份节点部署两套环境,通过防火墙进行保护,共享存储和数据库在两节点之间进行实时同步,保证数据的异地容灾。
4 结语
政务应用整合是一项复杂而系统的工程,结合海关政务信息化建设情况,采用云平台、微服务架构、应用集成等技术,设计科学合理的整合方案,可以有效地整合政务应用,提升政务工作效率和服务质量。未来,随着人工智能、大模型等新兴技术的发展,政务应用整合将不断深化和拓展,并持续优化,实现更智能化、高效化的政务服务,为智慧海关建设提供政务支撑,推动海关政务信息化建设现代化水平不断提升。
参考文献
[1] 陈慧娟. 数字背景下的政务信息系统整合和共享[J].数字技术与应用, 2024, 42(6): 50-53.
[2] 廖英豪, 杨璐涛, 宋希良, 等. 政务信息系统整合的技术思路与实践[J]. 互联网周刊, 2023(12): 36-38.
[3] 李亮, 黄文斌. 浅谈信息系统整合思路与实现[J]. 中国管理信息化, 2021, 24(23): 94-96.
[4] 谢敏, 徐晓婧, 侯一俊, 等. 数字政府门户建设下的政务资源整合研究与实践[J]. 自然资源信息化, 2024(5): 15-22.
[5] 陈晓龙, 李林, 杨航. 政务信息系统整合共享研究与实践[J]. 网络安全和信息化, 2021(2): 36-38.
[6] 王航. 多源异构数据整合系统的设计与实现[D].西安: 电子科技大学, 2020. DOI:10.27005/d.cnki.gdzku.2020.001173.
[7] 叶树江, 耿生玲, 谢锟, 等. 数据共享与数据整合技术[M]. 人民邮电出版社, 2019: 406-469.
[8] 谢天豪. 基于微服务架构的系统整合框架设计与实现[D]. 杭州: 杭州师范大学, 2023. DOI:10.27076/d.cnki.ghzsc.2023. 000980.
[9] 龚亮涛. 基于微服务架构的旅游系统整合的研究与实现[D]. 北京: 北京邮电大学, 2021. DOI:10.26969/d.cnki.gbydu.2021.003083.
[10] 陈志宏, 姚元. 基于云计算的政务信息系统整合研究[J]. 电信科学, 2021, 37(9): 118-128.
[11] 宛宁. 信息门户系统的数据整合与集成关键技术研究[D]. 长春: 长春工业大学, 2017.
[12] 孙柏林. 新时期政务服务系统整合对接模式探析[J]. 计算机时代, 2020(10): 120-124.
第一作者:顾岩(1984—),男,汉族,江苏江宁人,本科,高级工程师,主要从事海关政务信息系统建设、整合、运维等工作,E-mail: guyan@mail.customs.gov.cn
1. 全国海关信息中心(全国海关电子通关中心) 北京 100005
1. National Information Center of GACC (General Administration of Customs of China), Beijing 100005
表1 海关政务应用分类表
Table 1 Application classification table
序号 | 分类 | 主要内容 | 应用架构 | 部署模式 |
1 | 网站类 | 海关总署各司局、直属海关、事业单位等综合性门户网站 | B/S | 集中 |
2 | 办公类 | 配套公文传输、公文交换等辅助软件 | B/S | 集中、分布 |
3 | 科技类 | 海关科研管理、项目管理、运维管理、安全管理等 | B/S | 集中 |
4 | 财务类 | 海关财务预算管理、核算管理、税费管理、支付管理、资产管理等 | B/S | 集中 |
5 | 人事类 | 海关人事信息管理、关衔管理、干部管理、考勤管理、年度考核等 | B/S、C/S | 集中、分布 |
6 | 党建政工类 | 海关党建工作管理、好差评管理等 | B/S | 集中 |
7 | 后勤类 | 海关办公用品、会务管理、人车来访、门禁授权、接待服务等 | B/S | 集中 |
8 | 教培类 | 海关教育培训、在线学习、在线考试、在线交流等 | B/S | 集中 |
9 | 其他类 | 海关邮件、即时通信等 | B/S、C/S | 集中 |
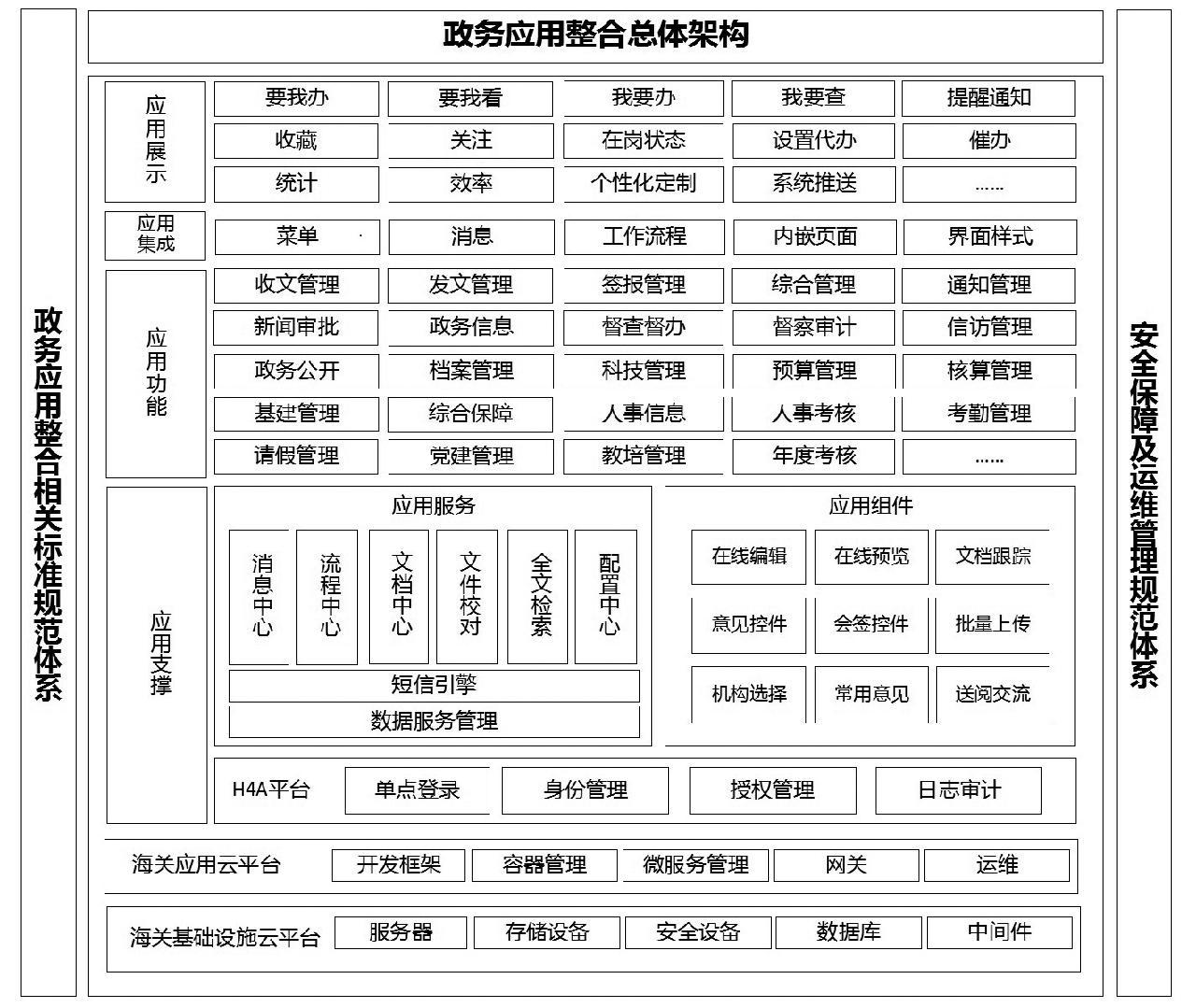
图1 政务应用整合总体架构图
Fig.1 Government application integration overall architecture diagram
第7卷 增刊
2025年7月
Application & Development Inspection / 应用开发
区块链技术在特殊物品通关监管中的
应用探索
胡自强 1 周 艳 1 陆 地 2
摘 要 本文主要从出入境特殊物品通关监管作业流程出发,分析出入境特殊物品通关的业务逻辑、基于区块链技术的系统架构设计,阐释区块链技术在数据共享、数据溯源以及智能合约等场景的应用,为建设海关通用区块链系统提供相应思路。同时,本文提出区块链技术在整体规划、系统性能、法律观念等方面所面临的挑战,并提出针对性应对建议。
关键词 区块链;智慧海关;海关监管
Exploration of the Application of Blockchain Technology in Customs Clearance of Special Goods
HU Zi-Qiang 1 ZHOU Yan 1 LU Di 2
Abstract This paper primarily examines the customs clearance and regulatory workflow for special inbound and outbound goods. It analyzes the business logic of their clearance procedures and proposes a blockchain-based system architecture design. This paper presents the application of blockchain technology in scenarios such as data sharing, traceability and smart contracts, offering development insights for building a universal blockchain system for customs. Additionally, it highlights challenges faced by blockchain technology in areas like overall planning, system performance and legal concepts, and puts forward relevant suggestions.
Keywords blockchain; smart customs; customs supervision
海关货物通关监管作业流程汇聚多元主体协同合作,涵盖海关、进出口企业、国内外监管部门及跨境电商等主体,在数字化转型进程中,海关监管面临着提升数据共享水平、优化数据溯源体系、强化跨境协作机制等发展机遇。伴随国际贸易的发展,海关监管部门通过技术创新持续提升监管资源效能。区块链技术凭借其数据不可篡改、流程透明化和智能合约自动化等特性,为构建海关信息协同网络、完善多方信任体系提供了创新解决方案。本文从出入境特殊物品通关监管业务场景出发,对区块链技术在海关监管作业中的数据实时共享、数据查证溯源以及智能合约方面的应用开展研究。
1 区块链概述及技术特点
1.1 区块链概述
区块链是一种基于密码学、分布式网络与共识机制的新型技术架构,其核心是通过去中心化方式构建多方参与的信任网络。区块链以“区块+链式结构”组织数据,每个区块包含交易记录、时间戳及前序区块哈希值,形成不可逆的时序链条。所有节点共同维护同一份分布式账本,数据全网同步且透明可查询,天然适用于需要多方协作、信任成本高的场景。
1.2 技术特点
(1)去中心化:摒弃传统中心化机构控制,数据存储与验证由全网节点共同完成。消除单点故障风险,提高系统的抗攻击能力和容错性。
(2)不可篡改性:采用哈希算法和链式结构存储数据,任何修改均需变更后续所有区块哈希值,且需获得超51%节点认可,技术上几乎不可行。
(3)透明可追溯:链上数据对所有授权参与者开放,交易全程可追溯。
(4)可编程性:支持自动执行的智能合约,基于预设规则的自动化程序,触发条件达成时自动执行。
(5)共识机制:通过算法如工作量证明(Proof of Work,PoW)、权益证明(Proof of Stake,PoS),确保节点间数据一致性。联盟链和私有链多采用实用拜占庭容错(Practical Byzantine Fault Tolerance,PBFT)算法,在保证效率的同时控制参与节点权限[1-3]。
(6)安全可信:采用非对称加密算法如RSA算法(Rivest-Shamir-Adleman,RSA)、椭圆曲线算法,保障身份与数据安全,同时依赖各分布节点算力开展工作量证明等共识算法,抵御恶意攻击,保证数据不可篡改和伪造。
区块链以去中心化架构为核心,通过不可篡改、可追溯等技术特性重构信任机制,在金融、政务、供应链等领域展现出颠覆性潜力4]。区块链技术的价值在于,在没有可信任中央节点情况下,各分布点达成共识建立互信5],并通过分布式节点的验证和共识机制解决了去中心化系统的双重支付问题。
2 海关监管信息化应用现状及分析
2.1 海关监管信息化应用建设概况
海关监管信息化建设是提升海关管理效率、优化贸易便利化水平的重要举措。近年来,随着金关工程二期、海关智慧监管平台以及智慧海关等项目的建设,通过引入云计算、大数据、人工智能等新兴技术,海关已逐步搭建了高可用、弹性扩展的信息化基础设施,建设、完善互联互通、协作紧密、运转高效的监管信息化应用,构建了数字化、智能化的监管体系。海关监管作业系统涵盖通关管理、查验管理、运输工具管理、风险管理、动植物检疫、卫生检疫、商品检验、企业信用管理等。这些信息化应用的建设,为海关履行进出境货物物品、运输工具、人员监管职能提供有力支持6]。
2.2 海关与外部单位数据交互方式特点
目前,海关与外部单位(如境外官方机构、其他监管部门、企业)的数据交互方式和特点如下:
(1)数据交换通道方式与中心化数据库对接方式。数据交换通道方式,海关内部中心化系统通过点对点数据交换通道或者接口方式与外部进行数据交换。例如,海关通关管理系统与中国国际贸易“单一窗口”使用消息队列(Message Queue,MQ)进行报关单等数据交换,如图1所示。中心化数据库对接方式,是通过数据库模式、文件模式等实现数据交换。例如,在海关网络隔离区(Demilitarized Zone,DMZ)部署前置节点,与国家级数据共享交换平台DMZ区前置节点实现数据库模式的数据交换。
(2)长数据链条和层级化信息传递。数据需通过多级机构层层传递,流程冗长且存在信息滞后,影响实时监管能力。同时,涉及多方协作需逐一建立安全通道,任何一个节点信息系统故障或者数据传输处理出现问题,都需要逐个排查数据链条上各节点系统运行情况。这种链条式、层级化信息传递方式,对现场问题处理响应时效、海关信息化应用运维效率,都提出挑战。
以上海关与外部单位的数据交换方式的特点,决定了不同部门单位的数据无法实时同步共享,数据流转过程中的查证和溯源手段有限。与此同时,随着海关业务量日渐增多,利用科技手段赋能海关监管工作,进一步提升海关监管资源效能,对智慧海关建设具有积极意义。
3 特殊物品通关监管应用场景分析
3.1 业务流程
海关通关作业涉及业务领域多,监管职能包括进出口货物监管、征税、打击走私、出入境卫生检疫、出入境动植物及其产品检验检疫、进出口商品法定检验等,监管对象涵盖进出境货物物品、运输工具、旅客等。以进出入境特殊物品监管业务为例,其通关业务流程简述见表1。
3.2 应用场景分析
3.2.1 数据实时共享
通过部署联盟链节点,将特殊物品监管全流程的各参与方数据上链,减少数据流通传输环节,实现数据实时共享,提升监管效率,缩短货物通关时长。涉及上链的单证及数据元如下:
(1)报关代理:主要单证为贸易合同、发票等,数据元为货物名称、品名、价格、数量等。
(2)货运物流:主要单证为运输单据、装箱单据等,数据元为货物名称、品名、数量等。
(3)海关及监管单位:主要单证为报关单、特殊物品行政许可、特殊物品审批单等,数据元为HS编码、货物名称、品名、数量、收发货人、查验记录等。
(4)使用单位:主要单证为特殊物品后续使用情况,数据元为货物名称、品名、数量等。
3.2.2 数据查证和追溯
各参与方数据实时上链,通过哈希链式存储+分布式账本存证,实现数据确权共享,保证货物信息数据在通关监管过程中的不可篡改。一方面,保证监管部门能够对特殊物品信息进行查证和溯源,实现从行政许可证书、申报、查验、检测以及后续监管的全流程溯源监管;另一方面,有助于企业及时获得货物通关过程状态和问题,及时进行处理和反馈,实现贸易便利化。
3.2.3 智能合约的应用
智能合约代码通常分布在区块链各个节点,当数据上链后,拥有合约的各个节点将会自动执行智能合约,如果上链的数据触发智能合约执行动作,各节点均能知悉相关数据状态并采取后续处理措施。在“去中心化”协作体系下,各参与方均可以不再单纯依赖某一方提交的“自证”信息,而是基于参与各方提供的“他证”信息开展各自业务流程[7]。例如,海关可以在特殊物品通关放行环节,结合报关代理、货运物流的货物信息以及监管单位的许可和审批信息,自动触发特殊物品审批单数量核销动作。
4 特殊物品监管区块链系统架构设计
为了实现海关监管作业过程中各参与方系统的互联互通,高效传输数据和实时数据共享,建立高效的去中心化高可信数据共享模型,使用区块链技术连接海关监管信息化应用和相关参与方系统,实现海关、特殊生物资源协同监管机构、第三方检测机构、特殊物品生产企业等相关数据上链。系统架构设计如图2所示。
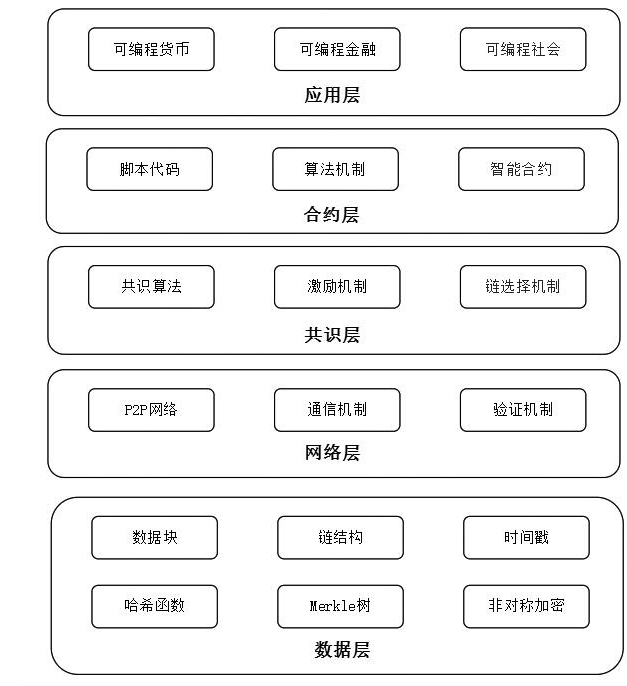
图2 区块链架构图[4,8]
Fig.2 Blockchain architecture diagram[4,8]
区块链系统架构包括五层核心结构,每层功能明确,协同实现区块链的核心特性(去中心化、不可篡改、透明可信)3-4,6,9],具体如下:
(1)数据层。实现数据存储与链式结构维护,确保数据不可篡改,将数据按照区块进行存储,通过哈希值将区块按时间顺序链接,形成不可逆链条,同时采用数据加密算法,保障数据安全和完整性,防止篡改。负责持久化存储链上的区块、交易、状态等账本数据,并对外提供索引和查询功能。该层主要存储特殊物品产品备案数据、特殊物品审批单数据以及核注核销等数据。
(2)网络层。P2P网络(Peer-to-Peer,P2P),实现节点间组网通信与数据传播,维持网络一致性,节点间直接通信,无中心服务器依赖。一般具备的功能特性包括:节点网络身份认证、具有安全保障的节点间数据通信、扩展节点支持自动发现和组网。
(3)共识层。在分布式场景中,将面临网络丢包、节点宕机、节点作恶等故障情况,共识层应当采用合适的共识算法,容忍和处理这些故障,保证多个节点取得相同的数据状态,确保所有节点对数据状态达成一致,防止双重支付等攻击。公有链常用的算法包括PoW和PoS,这两种算法的优点是可以支持的节点数量多,缺点是每秒事务处理量(Transactions Per Second,TPS)较低和交易确认时间长。联盟链常用的算法包括:Raft算法(Reliable, Replicated, Redundant, And Fault-Tolerant, Raft)和PBFT算法,这类算法的优点是TPS较高,缺点是支持的节点数量有限。
(4)合约层。合约层是区块链系统的核心之一,将复杂的业务规则(如风险控制、合规检查)编码为可执行的合约代码,实现流程标准化。预设条件(如特殊物品报关单审单、放行)自动触发操作(如特殊物品审批单检查、核销),替代人工干预,自动执行业务逻辑,保障交易的可靠性与透明度。
(5)应用层。面向用户的业务功能实现界面交互,落地具体应用场景。常见应用包括区块链管理平台、区块链浏览器、自定义API服务等,方便用户和系统访问区块链平台,可以为用户提供特殊物品行政许可查证、特殊物品审批单查证、审批单核销溯源和特殊物品溯源。
5 区块链在海关监管的深化应用展望
当前,区块链技术正在逐步应用到海关业务体系中,海关在应用模式探索、监管效能提升方面积累了丰富的经验。在此基础上,可以从以下方面持续深化技术应用:
一是加快统筹布局,构建协同生态。积极推进区块链应用顶层设计,通过整合现有试点资源构建统一技术平台,有效避免重复投入。规划筹建海关区块链生态,借助高质量共建“一带一路”,开展跨境协作,丰富应用落地场景7,10]。
二是强化技术攻坚,突破性能瓶颈。一方面,应研究采用高性能的、自主可控的区块链技术方案(例如,根据公开资料显示,我国自主研发的长安链交易吞吐量可以达到10万TPS);另一方面,应制定合理上链数据标准规范和管理制度。
三是推动制度创新,提升监管效能。明确区块链数据的法律效力,加强数据验证和数据保护,确保链上数据的真实性和可靠性,并最大限度地保护参与方数据安全11],提升监管效能。
6 结语
区块链技术在未来海关监管应用的发展方向将围绕数据可信共享、流程自动化、跨境协同监管等核心领域展开。数据可信共享方面,区块链通过哈希链式存储和分布式账本实现不可篡改的数据存证,实现全链条数据透明化和数据溯源。流程自动化方面,区块链技术的去中心化特性和智能合约功能,可以实现贸易数据的实时自动处理,提高通关效率,提升贸易便利化水平。跨境协同监管方面,为不同国家和地区的海关之间建立一个安全、可信的数据交换平台,促进跨境贸易的合作和发展。
综上所述,区块链技术在海关监管领域的应用前景广阔,通过重构海关监管的数据信任与流程协作机制,将引发海关监管领域的颠覆性革新与智能化转型。随着政策与技术的双轮驱动,应用场景将持续向多维度延伸,区块链技术有望在海关监管信息化应用发挥更加重要的作用,为全球贸易的繁荣和发展作出积极贡献。
参考文献
[1] 高娜, 周创明, 杨春晓, 等. 基于网络自聚类的PBFT算法改进[J]. 计算机应用研究, 2021, 38(11): 3236-3242.
[2] 刘懿中, 刘建伟, 张宗洋. 区块链共识机制研究综述[J]. 密码学报, 2019, 6(4): 395-432.
[3] 邵奇峰, 金澈清, 张召. 区块链技术:架构及进展[J]. 计算机学报, 2018, 41(5): 969-988.
[4] 袁勇, 王飞跃. 区块链技术发展现状与展望[J]. 自动化学报, 2016, 42(4): 481-494.
[5] Fan Jie, Yi Le-Tian, Shu Ji-Wu. Research on the technolo-gies of Byzantine system[J]. Journal of Software, 2013, 24(6):1346-136.
[6] 刘建军, 孙玉健, 张智, 等. 区块链技术在海关智慧通关领域的应用研究[J]. 天津科技, 2021, 48(1): 77-82.
[7] 王翔. 基于区块链技术服务贸易畅通探讨[J]. 中国口岸科学技术, 2020(3): 4-12.
[8] 蔡晓晴, 邓尧, 张亮. 区块链原理及其核心技术[J]. 计算机学报, 2021, 44(1): 84-131.
[9] 周金萍, 陈烁. 区块链电子提单实施方案及应用场景研究[J]. 中国口岸科学技术, 2024, 6(10): 84-90.
[10] 陈华, 张子寒. 区块链如何助推国际贸易转型升级[J]. 科技与金融, 2020(6): 18-24.
[11] 傅一旋, 匡增杰. 区块链技术在我国海关监管中的应用:现实问题与实施路径[J]. 海关与经贸研究, 2023, 44(2): 30-42.
基金项目:国家重点研发计划项目(2023YFC2605800)
第一作者:胡自强(1982—),男,汉族,浙江东阳人,本科,高级工程师,主要从事海关信息化应用建设工作,E-mail: 13701059540@139.com
1. 全国海关信息中心(全国海关电子通关中心) 北京 100005
2. 中国海关科学技术研究中心 北京 100026
1. National Information Center of GACC (General Administration of Customs of China), Beijing 100005
2. China Customs Science and Technology Research Center, Beijing 100026
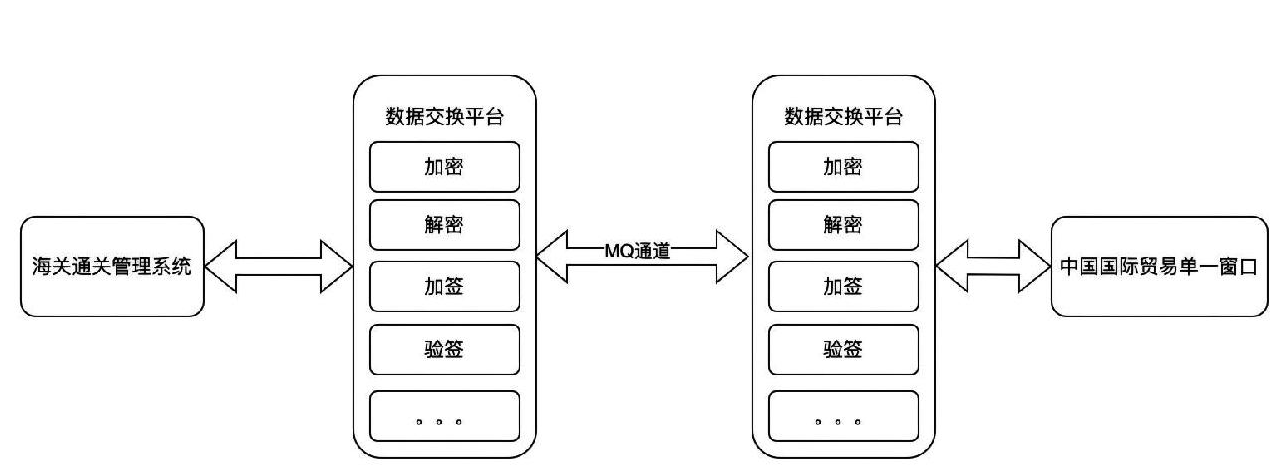
图1 数据交换通道方式
Fig.1 Data exchange channel methods
表1 特殊物品通关监管业务流程简述
Table 1 Overview of customs clearance regulatory process for special items
序号 | 业务步骤 | 简述 |
1 | 特殊物品行政许可申请 | 部分出境特殊物品需要按照国家有关规定的要求, 申请行政许可. |
2 | 特殊物品审批单申请 | 出入境特殊物品的货主或代理人, 提交特殊物品产品、生产企业等相关信息, 向海关申请特殊物品审批. |
3 | 报关申报 | 进口货物收货人或代理人 (出口货物发货人或代理人) 填报报关单, 向海关提交报关申请. |
4 | 查验 | 海关对被风险布控命中的特殊物品货物进行查验, 如发现异常情况登记特殊物品不合格案例数据. |
5 | 检测 | 必要情况下, 由实验室或第三方检测机构对特殊物品进行检测鉴定. |
6 | 处置 | 海关对特殊物品进行退运或者转第三方专业公司实施销毁处理. |
7 | 放行 | 海关放行货物. |
8 | 后续监管 | 海关对特殊物品使用单位进行后续监管. |
第7卷 增刊
2025年7月
Application & Development Inspection / 应用开发
混沌工程与可靠性测试技术研究
杨 硕 1
摘 要 本文以混沌工程技术为核心,通过注入可定义、可控的软硬件异常,探索复杂系统中的脆弱环节,重点验证可靠性中的容错性与易恢复性。结合国家标准,提出针对容错性(通过避免宕机率、抵御误操作率等指标)和易恢复性(通过平均恢复时间、修复有效性等指标)的测试方法,并基于混沌工程平台开展实践。研究通过两类实验验证系统可靠性:网络丢包异常注入导致系统性能显著下降且未能自动恢复,暴露容错性与易恢复性缺陷;服务不可用异常注入后系统快速恢复,表明部分环节具备预期可靠性。实验遵循混沌工程最小化爆炸半径、稳态假说等五大原则,强调在生产或模拟生产环境中通过自动化手段发现薄弱环节。研究证明,混沌工程能够有效识别微服务架构中的潜在风险,为提升系统可靠性提供实践依据,同时为同类复杂系统的测试方法优化提供参考。
关键词 混沌工程;可靠性测试;容错性;易恢复性
Research on Chaos Engineering and Reliability Testing Technology
YANG Shuo 1
Abstract This paper focuses on chaos engineering, exploring vulnerabilities in complex systems by injecting definable and controllable software/hardware anomalies, with an emphasis on validating fault tolerance and recoverability. Aligned with national standards, specific testing methods are proposed for fault tolerance (measured by indicators such as downtime avoidance rate and error resistance rate) and recoverability (evaluated by indicators such as average recovery time and repair effectiveness). Practical experiments are conducted using the JD Cloud Tai Chaos Engineering Platform. The study validates system reliability through two types of experiments: network packet loss anomalies caused significant performance degradation and failed automatic recovery, exposing deficiencies in fault tolerance and recoverability; service unavailability anomalies demonstrated rapid system recovery, indicating partial reliability compliance. The experiments follow five major principles such as minimizing the explosion radius in chaos engineering and the steady-state hypothesis, emphasizing automated detection of vulnerabilities in production or simulated environments. The research proves that chaos engineering can effectively identify potential risks in microservices architectures and provide practical insights for enhancing system reliability. It also offers a reference for optimizing testing methodologies in similar complex systems.
Keywords chaos engineering; reliability testing; fault tolerance; recoverability
近年来,微服务架构凭借其松耦合、高扩展性和敏捷开发等优势,在海关信息系统建设中得到广泛应用。然而,随着服务规模与依赖关系的指数级增长,系统的复杂性也显著提升。在此背景下,如何确保分布式系统在异常场景下的可靠性(尤其是容错性与易恢复性),成为亟待提高和优化的核心问题。
混沌工程(Chaos Engineering)作为一种新兴的故障主动探测方法,为上述挑战提供了创新性解决方案。其核心理念在于通过可控的异常注入,模拟真实故障场景,系统化验证复杂系统的鲁棒性。相较于传统测试,混沌工程强调主动制造可控的故障,遵循最小化爆炸半径、稳态假说、自动化实验等五大原则,以科学实验的方式识别系统薄弱环节,推动可靠性优化。近年来,该技术已在金融、电子商务等领域成功实践,但其在海关信息化系统中的适用性仍需深入探索。
本文以海关大平台微服务系统为研究对象,结合国家标准GB/T 25000.10—2016《系统与软件工程 系统与软件质量要求和评价(SQuaRE)第10部分:系统与软件质量模型》[1]、GB/T 25000.23—2019《系统与软件工程 系统与软件质量要求和评价(SQuaRE)第23部分:系统与软件产品质量测量》[2]中对系统可靠性的定义与度量要求,提出基于混沌工程的容错性与易恢复性测试框架。通过某混沌工程平台,设计并实施网络丢包、服务不可用两类典型异常实验,量化分析系统在故障注入下的响应能力与恢复效率。研究旨在解决以下问题:(1)如何精准定位微服务架构中的脆弱节点;(2)如何通过实验数据验证容错性与易恢复性指标;(3)如何将混沌工程原则融入现有测试流程,降低系统上线风险。
1 混沌工程的意义
随着海关大平台微服务总体技术架构的推进和应用项目规模的扩大,在单一节点或实例上出现的异常产生的影响往往不会局限于该节点或实例,而是会对整个系统造成不可预知的影响。因此,测试人员需要尽可能及时地识别风险,针对性地进行加固和防范,以避免异常出现时带来的不可预知的严重后果。为此,本文引入了混沌工程技术,该项技术通过注入可定义可控制的异常,主动找出复杂系统中的脆弱环节,从而提高复杂系统可靠性,提早在测试环境中发现系统可靠性方面的问题和缺陷,降低修复成本和上线风险。
2 系统可靠性的定义和测试方法
根据GB/T 25000.10—2016的定义[1],可靠性是指系统、产品或组件在指定条件下、指定时间内执行指定功能的程度。可靠性的子特性包含成熟性、可用性、容错性、易恢复性和可靠性的依从性。
容错性的度量指标包括正常运行度、抵御误操作率,易恢复性的度量指标包括重启成功度和修复成功度,不难发现,对于混沌工程而言侧重于可靠性中的容错性和易恢复性。
目前,业界对于可靠性测试研究和实践还处于探索阶段,对于测试技术的要求较高,原因在于可靠性测试所需的部分数据难以采集,部分测试条件难以实现。例如,容错性测试中的宕机率、易恢复性测试中需要实现可控的故障和失效,都对可靠性测试方法提出了挑战。
而通过引入混沌工程技术则能够解决上述问题。在对GBT 25000.10—2016[1]和GB/T 25000.23—2019[2]进行深入探讨和研究后,结合测试理论和混沌工程技术,本文针对可靠性测试中的容错性测试和易恢复性测试提出了具体测试方法,并根据测试方法在实际项目中进行了实践。
2.1 容错性及其主要测试方法
根据GB/T 25000.10—2016[1]的定义,容错性是指在存在硬件或软件故障的情况下,系统、产品或组件的运行符合预期的程度,可用正常运行度、抵御误操作率等指标进行度量。测试内容包括软件产品在由于非法数据、非法操作、误操作等原因导致无法正确运行和参数传递出现错误的情况下,能否为用户提供相应服务器的能力。
容错性可通过避免宕机率、避免失效和抵御错误的操作率进行测试。前者的测试内容为在测试过程中,软件出现异常或故障时不应引起整个运行环境死机;后者的测试内容为软件即使在所使用的容量高达规格的极限、企图使用超出规定极限的容量、用户造成的不正确的输入等情况下,也能避免关键性或严重的失效。
2.2 易恢复性及其主要测试方法
根据GB/T 25000.10—2016[1]的定义,易恢复性是指发生中断或失效时,产品或系统能够恢复直接受影响的数据并重建期望的系统状态的程度,可用重启成功度、修复成功度等进行度量。测试内容包括产品需明确在软件发生失效的情况下,采取何种措施重建,为用户提供相应服务和恢复直接受影响数据的能力。
易恢复性可通过平均恢复时间、修复有效性进行测试。前者的测试内容为计算每次从失效起到完全恢复所花费时间的平均值;后者的测试内容为验证系统从失效中恢复后功能未受到影响,依然能维持规定的性能级别。
3 混沌工程技术研究
当前新一代架构转型由传统的面向服务的架构(Service-Oriented Architecture,SOA)向分布式架构、去中心化发展,当前还进阶到注重云化支持和异构化微服务支持的服务网格模式。一方面,由于技术异构性、具备弹性伸缩、可扩展性等优势,微服务架构得到迅速推广;另一方面,微服务架构在使用过程中又会面临诸多挑战,如由于系统级依赖增多而带来的不确定性风险指数级增长。
在微服务架构转型的驱动下,混沌工程实践方案可以通过规范化、流程化的方案对系统进行一定程度的“随机破坏”,让故障在可控范围内频繁发生,在此过程中可以深入地认知故障和系统,并达到持续改进的效果。
微服务与SOA架构的区别是微服务更强调“业务需要彻底的组件化和服务化”,其特性如客户端负载均衡、微服务容错保护、API服务网关、分布式链路跟踪等均为此服务。而传统的非功能测试方法只能覆盖到业务逻辑维度,无法覆盖和测试到上述微服务特性[3]。
混沌工程与传统测试的不同点在于传统测试用例会有“期望结果”和“实际结果”,通过将两个结果加以比较,或者对用户行为的预期,来判断测试通过或失败;而混沌实验类似于“探索性测试”,实验本身没有明确的输入,是通过对系统和服务的不同组合干预,来观察系统的“反应”。具体操作时,可以将混沌工程原则融入到测试过程中:在测试环境/准生产环境小规模模拟系统故障组合并定期自动化执行实验,通过实验结果与正常结果进行比对,观察系统对故障的承受和反应能力[4-6]。
应用系统通常运行在其最大概率的运行状态,因此常规软件测试也应处于应用系统最大概率运行状态下执行。而混沌工程通过故障注入,会导致系统进入从未经历过的状态,在这种状态下,系统是否稳定是未知的。实施混沌工程需要遵循五大原则,设计好每一个实验,以避免不可控制的风险[7-8]。
混沌工程的五大原则包括:(1)最小化爆炸半径。在生产环境中进行实验可能会引发真实的故障发生,所以在执行试验时需要确保影响范围最小化且可控。(2)稳态假说。关注可测量输出,而不是系统内部属性,建立一个围绕稳定状态行为的假说;短时间内的度量结果,代表了系统的稳定状态;验证系统是否工作,而不是如何工作。(3)真实事件。通过潜在影响或预估频率确定事件的优先级;任何能够破坏稳态的真实事件都是混沌实验的一个潜在变量。(4)生产环境。系统的行为会根据环境和流量模式而变化,为了保证系统行为的真实性与当前部署系统的相关性,混沌工程强烈推荐在生产环境中进行实验。(5)自动运行实验。手工运行实验是不可持续的工作,所以需要把实验变为自动化且持续的执行[8]。
此外,系统发生不可接受影响的原因多种多样,威胁发生后会经历从薄弱环节、异常表现的循环,直至系统产生不可接受的影响。首先,威胁一般是不可消除的,而且存在一定的发生概率,在拉长时间线后可以认为故障一定会发生,比如硬盘一定会损坏,软件缺陷一定无法完全消除。但是,测试人员可以通过强化系统中存在的一系列薄弱环节,消除系统中的异常表现,或降低其出现的概率,如磁盘做磁盘阵列(Redundant Arrays of Independent Disks,RAID),通过过程改进降低软件的缺陷逃逸率,使用网络双链路等,最终消除不可接受的影响或降低出现概率。因此,发现和识别薄弱环节对提高系统稳定性和可靠性具有重要的意义。
混沌工程理念就是尽可能从注入各种异常表现入手,从而发现系统中存在的可能导致不可接受影响的缺陷或薄弱环节,从而提高系统的稳定性和可靠性,避免在威胁真正发生时,会穿透一系列的薄弱环节,最终造成不可接受的影响。因此,测试人员不能简单地通过重启、升级、扩容等方式解决表面现象,而应直面系统中的薄弱环节,深究问题发生的根本原因和系统中的薄弱环节[4,6,8]。为此,测试人员使用专业的混沌工程平台作为本次研究混沌工程的工具,在项目中进行了实践。
4 混沌工程的项目实践
在项目实践中测试人员选择某核心系统的2个环节,分别注入2种不同的异常,进而验证这2个环节的可靠性。
4.1 网络丢包异常
首先找到集群中2个实例的位置,作为注入异常的目标。在混沌工程平台中将某核心系统中某功能模块集群中2个实例中的1个丢包率设置为100%,此时该实例的网络应为不可用状态,因为所有网络传输数据包全部丢失。之后,设定爆炸范围,避免实验导致的异常无法恢复后,混沌实验的场景设置即告完成。
正如前文所述,混沌实验不能单独存在,应在生产环境进行,如果无法在生产环境中执行,也应在测试环境中模拟生产环境。因此,必须在测试环境中模拟生产环境的日常负载,验证异常出现后对系统造成的影响。为此,测试人员使用性能测试工具模拟了100个用户访问该功能模块的操作,并在设置好混沌工程实验后启动了性能测试场景,从而得以监控系统产生的负载和流量。此时系统中产生的事务数和每秒点击数随着并发用户的增加逐步增长,随后达成了稳态,不再有大的波动。
启动混沌工程实验,验证网络异常会对该功能模块造成的影响,以及该功能模块如果产生失效,是否能够从失效中自动恢复。通过测试网络数据包的命令即可证实,与实例之间的网络丢包异常已经生效,测试网络数据包命令无法返回实时延迟。此时,在性能测试场景中,每秒事务数与每秒点击率均出现大幅下降,并报出了大量错误和失败事务,在混沌工程启动后10秒即出现了362个失败事务和1054个错误。
通过网页进入某核心系统实际功能操作界面进行操作,界面无响应,打开开发者工具可以看到后台报出了Http 504错误,即网关超时错误。此时在集群中的2个实例中只有1个实例存在网络丢包异常,如果系统的容错性满足需求,K8s注册中心应及时发现1个实例出现异常,处于不可达的状态,将系统所有流量转向正常的实例,或根据设置启动1个新的实例以保证系统功能和性能不出现问题。但根据实际测试结果,被测的功能环节并未实现以上异常处理,而是导致性能场景出现大量错误事务,实际功能操作无法进行,后台报出网关超时错误,可靠性中的容错性出现明显问题。
在混沌工程实验启动一段时间后,测试人员再次检查了性能测试场景与功能操作环节,其中功能操作共进行了5次操作,仅有1次成功,3次报出Http 504网关超时错误,1次报出Http 502无效网关错误。而在性能测试场景中,自从启动混沌工程实验,系统的每秒事务数和每秒点击率大幅下降,且一直未能恢复,同时报出的错误和失败事务不断增加,从刚启动混沌工程实验时错误1054个增长至5348个,失败事务由362个增长至2345个。
综合实际功能操作与性能测试场景不难得出结论,系统未能从异常中自动恢复,可靠性中的易恢复性出现明显问题。因此,该核心系统某查询环节的可靠性测试不能通过。
4.2 服务不可用异常
首先依然按照上文混沌工程的标准选择资源,设置服务不可用的异常,并在性能测试工具中设置性能测试场景,模拟生产环境日常负载。然后,启动混沌工程实验,向系统注入服务不可用的异常。在对性能测试场景进行验证时发现在注入异常后每秒事务数和每秒点击率均出现大幅下降,同时出现了错误与失败事务,分别出现了100个失败事务和200个错误,系统明显受到了注入的服务不可用异常影响。
但在混沌工程实验启动30 s后,系统迅速从异常中恢复,每秒事务数与每秒点击率均增加至注入异常前的水平,错误数与失败事务数也不再增加。
此时在功能界面进行操作系统能够正常响应,系统功能未受影响。因此,该核心系统某查询环节可靠性中的容错性和易恢复性均未出现问题,可靠性测试能够通过。
5 结语
本文深入探讨了混沌工程与可靠性测试技术,旨在提升海关大平台微服务架构的系统可靠性。研究表明,随着系统规模扩大,单一节点异常可能对整体系统造成不可预知的影响,传统测试方法难以满足可靠性评估需求,混沌工程应运而生。
混沌工程通过主动注入异常,模拟复杂环境中的故障场景,提前发现系统脆弱环节,验证容错性和易恢复性。与传统测试不同,混沌工程类似“探索性测试”,无明确输入和预期结果,通过系统和服务的不同组合干预观察系统反应。
在项目实践中,测试人员选择了某核心系统的2个环节,分别注入网络丢包异常和服务不可用异常,通过在某混沌工程平台进行的混沌实验,以性能测试工具模拟生产环境负载,观察系统在异常下的表现。网络丢包异常实验中,系统出现大量错误和失败事务,功能操作界面无响应,暴露了容错性和易恢复性不足。服务不可用异常实验中,系统在异常注入后迅速恢复,功能界面操作正常,验证了系统的可靠性。
综上所述,混沌工程通过主动注入异常,能有效发现系统中的薄弱环节,提高系统的稳定性和可靠性。在项目实践中,网络丢包异常实验暴露了系统某查询环节在容错性和易恢复性方面的不足,而服务不可用异常实验则验证了系统另一查询环节的可靠性。这表明混沌工程在复杂系统可靠性评估和提升方面具有显著效果,值得进一步研究和应用。同时,也强调了在面对系统异常时,应积极发现和识别系统中的薄弱环节,避免简单通过重启、升级等方式解决表面问题,与混沌工程实践的理念相契合。
参考文献
[1] GB/T 25000.10—2016 系统与软件工程 系统与软件质量要求和评价 (SQuaRE) 第10部分:系统与软件质量模型[S]. 北京: 中国标准出版社, 2016.
[2] GB/T 25000.23—2019 系统与软件工程 系统与软件质量要求和评价(SQuaRE) 第23部分:系统与软件产品质量测量[S]. 北京: 中国标准出版社, 2019.
[3]王宪刚, 孙晓璇. 分布式核心系统混沌测试探索与实践[J]. 金融电子化, 2022(2): 75-76.
[4]王蒙, 黄永厚. 基于混沌工程的数据库故障演练平台研究与实践[J]. 网络安全和信息化, 2024(10): 58-60.
[5]铁锦程. 基于混沌工程理念的数据中心稳定性体系探索与实践[J]. 网络安全技术与应用, 2023(10): 18-21.
[6]田雷, 封亮, 李海峰. 基于失效模式的软件可靠性评估模型[J]. 软件工程, 2023, 26(7): 54-57.
[7]王敏. 故障注入在智能网络管控系统测试中的应用研究[J]. 电脑知识与技术, 2023, 19(2): 75-77.
[8]凯西·罗森塔尔, 诺拉·琼斯. 混沌工程:复杂系统韧性实现之道[M]. 北京: 机械工业出版社, 2021: 125-143.
第一作者:杨硕(1980—),男,汉族,北京,本科,工程师,主要从事海关信息系统开发测试工作,E-mail: yangshuo@customs.gov.cn
1. 全国海关信息中心(全国海关电子通关中心) 北京 100005
1. National Information Center of GACC (General Administration of Customs of China), Beijing 100005
第7卷 增刊
2025年7月
数据分析 / Data Analysis
海关大数据资源一体化管理
与共享架构的研究
徐龙宁 1 何长庚 1 孙建明 1
摘 要 本文围绕海关大数据资源管理、大数据资源共享一体化的要求,研究海关跨集群、跨平台、跨地域的大数据资源管理、大数据资源共享的新架构。该架构以数据资源目录为基础,构建全国海关大数据资源“一本账”,实现全国海关大数据资源一体化共享。同时,强化海关大数据应用服务保障能力,助力形成横向打通、纵向贯通、一体化、智能化的数据共享、数据管理新格局。
关键词 大数据;数据资源目录;数据资源管理;数据资源共享
Research on Integrated Management and Sharing Architecture of Customs Big Data Resources
XU Long-Ning 1� HE Chang-Geng 1 SUN Jian-Ming 1
Abstract Based on the requirements of the integration of customs big data resource management and big data resource sharing, this paper studies the new architecture of customs big data resource management and big data resource sharing across clusters, platforms and regions. By establishing a data resource catalog as the foundation, the research aims to create a “unified registry” for nationwide customs big data resources, achieving integrated sharing across China’s customs system. It emphasizes enhancing big data application service capabilities to facilitate the establishment of a horizontally integrated and vertically connected intelligent data sharing and management ecosystem, ultimately forming a new pattern that combines horizontal coordination with vertical connectivity in data governance.
Keywords big data; data resource catalog; data resource management; data resource sharing
近年来,国家发布相关文件指出加快建设全国一体化政务大数据体系[1],推进各部门政务数据平台与核心枢纽对接。当前,海关总署深入推进大数据信息化建设,直属海关按照有关要求陆续建设了关级大数据平台,在此背景下,数据交互需求变得更加迫切。此外,海关关于“十四五”大数据应用规划的有关要求中也提出,建立海关大数据资源目录,完善数据统一管理,实现海关大数据资源一体化共享。本文基于海关信息化建设工作要求,研究跨集群、跨平台、跨地域的海关大数据资源管理、数据资源共享新架构,为数据管理人员、开发人员、分析人员提供“管数、找数、看数、用数”统一平台,以标准化的数据服务满足各种精细化需求,支撑海关大数据资源一体化共享,为智慧海关建设提供技术支持。
1 海关大数据建设概述
海关总署构建了业务网大数据基础设施,汇聚海关内外部数据形成了总署层面大数据池。直属海关自主构建本级大数据平台,汇聚海关总署下发、本地产生和外部获取的数据,开展数据采集、加工、清洗,并建立相应的智能模型应用。海关总署、直属海关大数据资源存储在不同地域、不同平台,数据来源广泛、治理整合难度较大,需要建设统一数据服务门户,完善数据资源目录编制标准,提升总署与直属海关之间安全、高效、便捷双向流动能力,更好服务全国海关大数据应用[2]。
伴随海关大数据建设,大数据应用已取得显著成效,在智能化监管、便利化通关、风险防控及数据共享协作等方面发挥了重要作用。但是,数据共享、数据服务仍然在多个平台以不同的技术体系开展,增加了数据应用难度。现有大数据应用多基于账号直连方式使用数据,上层应用和底层平台耦合度较高,全国海关剧增的大数据应用需求必将给数据服务保障带来更大挑战。
另外,随着全国一体化政务大数据体系建设推进,海关总署不断推进政务数据资源开放共享,充分释放海关公共数据要素潜能,与国家政务服务平台对接,有效扩大公共数据供给。目前,直属海关直接申请、使用国家政务服务平台数据资源存在一定困难,需完善总署与直属海关之间数据通道,支撑国家政务服务平台资源直达基层,高效、便捷服务直属海关数据应用。
2 相关技术实践的研究
为探索全国海关一体化数据资源管理与共享新架构,本文研究了数据资源管理与数据共享相关技术实践。在大数据背景下,充分利用大数据等信息化技术手段,加强政务信息资源统筹整合,在跨部门和跨层级的信息资源交换共享基础上,为公众提供一站式服务[3]。建设统一的政务数据共享交换平台,有效实现政务不同数据库之间的交换,为各政务部门提供统一的信息跨部门应用能力[4]。
数据编织和数据网格均注重于数据发现、数据访问和数据整合,将分散的数据资源整合为一个统一的数据视图,可以解决海关数据资源分布不同地域、不同平台的问题,使其能够将可信数据从所有相关的数据源以灵活的、业务可理解的方式推送给需要的人,让“人找数据”变为“数据找人”[5]。隐私计算在保护数据的同时可以实现安全的数据处理和数据分析,需要可信的硬件和执行环境[6]。海关内部数据共享,具备隐私计算安全的相关保障条件,因此应用隐私计算的必要性不强。
数据虚拟化技术将数据资源封装为数据服务,以一种抽象和统一的方式访问和查询分散在多个数据源中的数据,而无需将数据复制或集中存储。数据虚拟化将多个数据源的数据视为一个逻辑统一的数据源,将数据表示为抽象的数据模型,使用户能够以更简单的方式理解和使用数据[7]。数据目录包括业务元数据、技术元数据、管理元数据,将不同类型、不同层次的数据按照一定的分类体系进行编目,用以描述数据的特征,实现数据检索、数据取用方便。规范的数据目录建设可以体现数据的连接和发现能力、协作和分享能力、检索筛选和自组织能力、安全和开放能力[8]。
3 体系架构设计
3.1 总体设计思路
本研究参照数据编制、数据网格、数据虚拟化、数据目录的技术,将全国海关不同平台、不同地域的大数据资源一体化、标准化进行编目,编制的资源目录形成逻辑统一的海关大数据资源池,一体化、智能化服务全国海关大数据应用。坚持“数据可用不可见”“数据安全可控”原则,优先提供标准化数据共享服务,数据共享支持行列灵活控制,总署与直属海关数据管理、数据安全边界清晰。总体设计思路如图1所示。
根据本研究设计的全国海关“两级”数据目录架构,海关总署管理使用总署数据目录、直属海关上报数据目录;直属海关管理使用本级数据目录、总署下发数据目录。目录承载数据管理,以数据分类分级、数据一数一源为基础,建立数据资源目录体系,实现海关大数据资源的统一组织、动态更新。目录驱动数据共享,以数据资源目录为载体,挂载物理数据资源,驱动数据在海关总署和直属海关之间双向快速流动。
3.2 总体架构
海关大数据资源一体化平台采用“1+N”两级架构。其中,“1”是指海关总署核心节点,是海关数据资源管理的总枢纽、数据服务的总通道;“N”是指N个直属海关子节点,支撑本关区数据资源目录编制、数据资源管理、数据共享服务等,并与核心节点实现目录互联、数据互通。支持跨地域、跨平台数据资源管理能力、数据共享服务能力,可实现与大数据平台对接。直属海关没有本级大数据平台,无数据管理需求,仅部署前置节点,支撑与总署的数据共享。总体架构如图2所示。
3.2.1 数据服务门户
数据服务门户提供数据资源“一本账”展示、“一站式”申请、“一平台”调度,支持数据资源目录展示和检索、资源申请和审批、统计管理、通知公告等功能。
3.2.2 数据目录管理
支持对大数据平台数据资源进行编目、修改、发布、撤销;支持在线编目、目录导入等灵活数据编目方式;支持目录探查,当数据资源发生变化时,及时更新数据资源目录并同步到直属海关。
3.2.3 数据共享交换
提供跨平台、跨地域一体化的数据服务共享能力,与全国海关的大数据平台对接,通过接口调用、库表推送、文件推送等方式将各节点数据资源灵活便捷地共享给各节点上层应用。支持低代码数据服务开发,具备数据安全控制、数据服务快速构建能力。
3.2.4 节点级联管理
海关总署核心节点展示所有级联节点的拓扑图及数据共享链路情况(接口、库表、文件等链路及各链路业务负载统计)。该节点可以将发布的数据资源目录下发至直属海关,若撤销,直属关节点不再展示已下发资源目录,对应数据链路断链。直属海关节点上报目录到海关总署节点,海关总署可将其下发至其他直属海关节点。
3.2.5 安全保障
提供数据分类分级、敏感数据识别、数据脱敏、安全审计等数据安全防护能力,支持系统IP访问控制、请求业务参数管理、“黑白名单”管理、服务流量控制。支持从服务和应用两个维度、从不同的时间周期进行限速,达到限速阈值后邮件告警。保障数据推送、数据汇聚等共享服务数据安全性,满足数据全生命周期安全防护的要求。
3.2.6 管理机制
构建标准统一、管理协同、安全可靠的全国海关一体化大数据资源管理制度及共享规范,解决数据管理机制不健全、数据供需对接不顺畅等问题,促进全国海关大数据资源依法有序高效流动。设置不同数据资源管理角色,负责数据资源目录维护、数据资源审批等。
3.3 两级架构必要性分析
本文从海关大数据应用全局出发,面向海关总署、直属海关两级数据应用,通过统筹全国海关大数据资源分布、研究一体化的数据共享和使用模式,设计“海关大数据资源一体化平台”。具体而言,数据服务门户是全国海关数据资源共享事项办理的集中交互载体,解决数据资源“找得到”的问题。数据目录管理将分布在不同平台的数据资源,形成接口、库表、文件、实时数据流等不同类型数据资源目录,助力构建海关大数据资源一本账,解决数据资源“看得懂”的问题。数据共享服务包括数据查询、数据推送、数据汇聚等服务能力,支持数据资源跨区域、跨层级、跨平台共享流通,支撑海关大数据共享服务融入全国一体化政务大数据体系,解决数据资源“用得上”的问题。
在管理方面,两级架构满足直属海关管理关级数据资源、按需上报直属海关数据目录到海关总署的需求,也能确保数据安全管理边界清晰,降低发生单点故障的可能性。在便捷使用方面,直属海关应用通过本地节点用数,便于及时应对关级灵活多样的数据应用需求。在网络安全方面,两级架构能大幅降低网络安全风险,只需开通海关总署节点和直属海关节点之间的防火墙。在数据安全方面,两级架构能实现节点之间双向通道均是加密传输,符合数据加密安全要求。
4 典型应用场景
海关大数据资源一体化平台支撑海关总署、直属海关开展一体化数据资源管理、数据共享应用,涵盖数据接口服务、数据推送服务、数据汇聚服务等七大应用场景。
4.1 海关总署与直属海关之间接口方式共享流程
在海关总署节点,对数据资源进行编目,将数据资源一键转化为接口服务挂载到目录下并发布为接口类资源,按需将审批的目录下发至直属海关。在直属海关节点,展示海关总署下发目录并申请数据。数据申请信息同步到海关总署节点,经审批通过后,接口服务自动代理到直属海关。直属海关各应用只需进行本地接口调用即可,接口方式共享流程如图3所示。
4.2 海关总署与直属海关之间库表交换流程
在海关总署节点,对数据表资源进行编目,同时将物理数据表资源挂载到目录下并发布为库表类资源,按需将审批的目录下发到直属海关。在直属海关节点,展示海关总署下发目录并申请数据,申请数据与信息同步到总署节点,经审批通过后,平台周期性将数据资源推送到直属海关的本地存储。直属海关应用从本地存储中获取数据并进行使用,库表交换方式共享流程如图4所示。库表交换优先应用于加工和治理后结果数据,原则上原始明细数据不走库表交换方式。
直属海关侧数据满足不了本关智能模型训练时,借助海关大数据资源一体化平台上传模型训练的程序、数据到海关总署大数据平台,在此平台上开展模型训练,并借助一体化平台接口调用或者库表交换能力,自动、便捷回传训练模型结果及参数。
4.3 直属海关之间数据共享服务
海关大数据资源一体化平台中海关总署节点汇聚全国海关的数据资源目录,并按照业务需求向各直属海关下发资源目录,各直属海关可通过本级节点上数据资源目录对数据资源进行查看、申请并获取数据资源。直属海关之间数据共享流程如图5所示。
4.4 全国海关外部数据交换服务
海关大数据资源一体化平台与国家政务服务平台对接,支撑与其他部委及省市之间的数据共享交换,提供库表、文件、接口3种方式,实现海关政务数据交换数出一门。对接国家政务大数据体系后数据交换的流程如图6所示。
海关总署从国家政务服务平台订阅、同步的资源目录到海关总署核心节点,按需批量下发资源目录到直属海关节点上,解决直属海关“看不到”国家平台上数据资源目录问题;直属海关节点可以查看海关总署下发资源目录,按需申请订阅对应数据资源,订阅需求自动汇总到海关总署核心节点。总署核心节点汇总各直属海关数据资源订阅需求,审核同意后批量自动提交到国家政务服务平台,并实时同步国家政务服务平台上审批流转状态及审核结果到各直属海关节点,解决直属海关“申请不了”国家平台数据资源问题;基于海关大数据资源一体化平台,实现海关与外单位政务数据交换全流程在线处理、工作闭环。
5 实践成效
本研究设计的海关大数据资源一体化平台已经作为署级信息化项目立项建设,可以在海关总署和直属海关两级节点提供数据服务门户、数据目录编制、数据资源共享功能,并实现目录互联、数据互通。基于资源目录,实现跨云、跨平台、跨地域的数据资源管理能力,进而服务海关总署、直属海关大数据应用。目前,研究成果已在部分直属海关开展试点应用,进一步打通了海关总署到直属海关之间双向数据通道。
6 结语
全国海关大数据资源一体化的数据共享和使用模式,实现上层应用与底层大数据平台的隔离,形成新型数据服务体系,将不断提升全国海关大数据资源一体化管理、一体化共享水平,推动数据治理成果在全国海关范围内充分共享利用,助力智慧海关建设。
参考文献
[1] 国务院办公厅. 国务院办公厅关于印发全国一体化政务大数据体系建设指南的通知, 国办函〔2022〕102号[EB/OL]. (2022-10-28)[2025-03-11]. https://www.gov.cn/zhengce/zhengceku/2022-10/28/content_5722322.htm.
[2] 何长庚. 海关数据资产化治理发展方向研究[J]. 中国口岸科学技术, 2023(53): 48-51.
[3]赵豪迈, 付玉环. 大数据背景下政务信息资源整合与共享中主要问题的探讨[J]. 图书情报导刊, 2021, 6(8): 25-32.
[4]王平. 大数据背景下政务信息资源共享平台的应用[J]. 办公自动化, 2024, 29(10): 28-30.
[5] 胡庆勇. 数据编织[M]. 北京: 清华大学出版社, 2024: 10-50.
[6] 闫树, 袁博, 吕艾临. 隐私计算: 推进数据“可用不可见”的关键技术[M]. 北京: 电子工业出版社, 2022: 11-31.
[7] 祝守宇, 蔡春久. 数据标准化: 企业数据治理的基石[M]. 北京: 电子工业出版社, 2023: 53-73.
[8] DAMA国际. DAMA数据管理知识体系指南(原书第2版)[M]. 北京: 机械工业出版社, 2020: 10-23.
第一作者:徐龙宁(1987—),男,汉族,山东菏泽人,硕士,主要从事数据治理、数据共享相关工作,E-mail: xulongning@mail.customs.gov.cn
1. 全国海关信息中心(全国海关电子通关中心) 北京 100005
1. National Information Center of GACC (General Administration of Customs of China), Beijing 100005
图1 总体设计思路图
Fig.1 Main design approach diagram
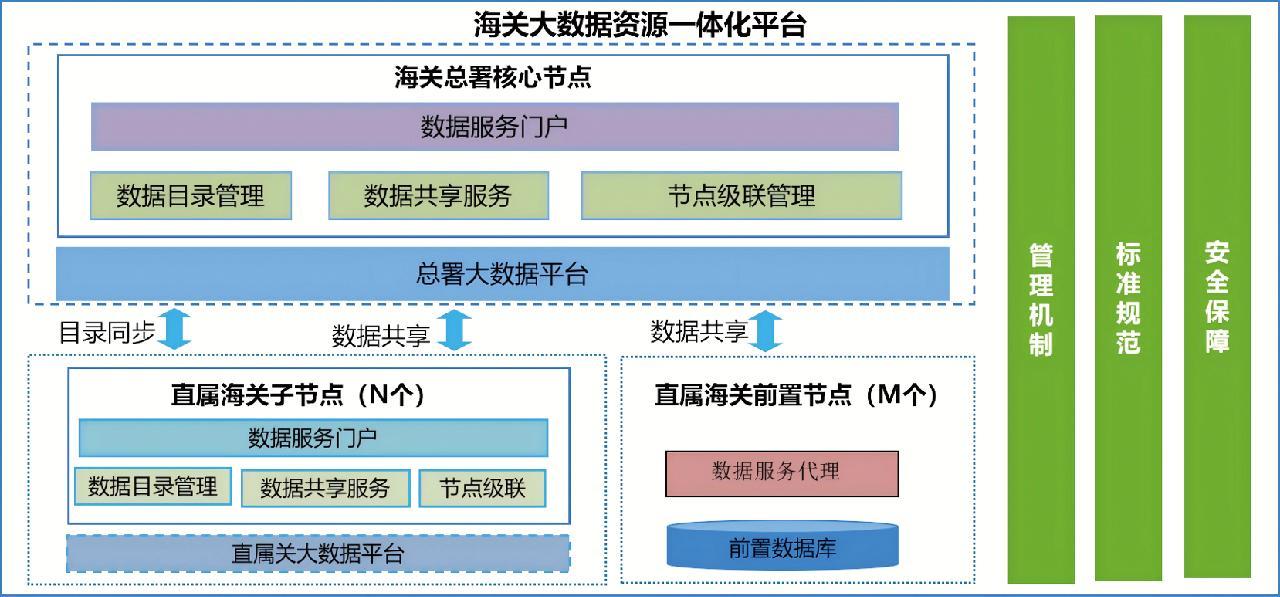
图2 总体架构图
Fig.2 Main architecture diagram
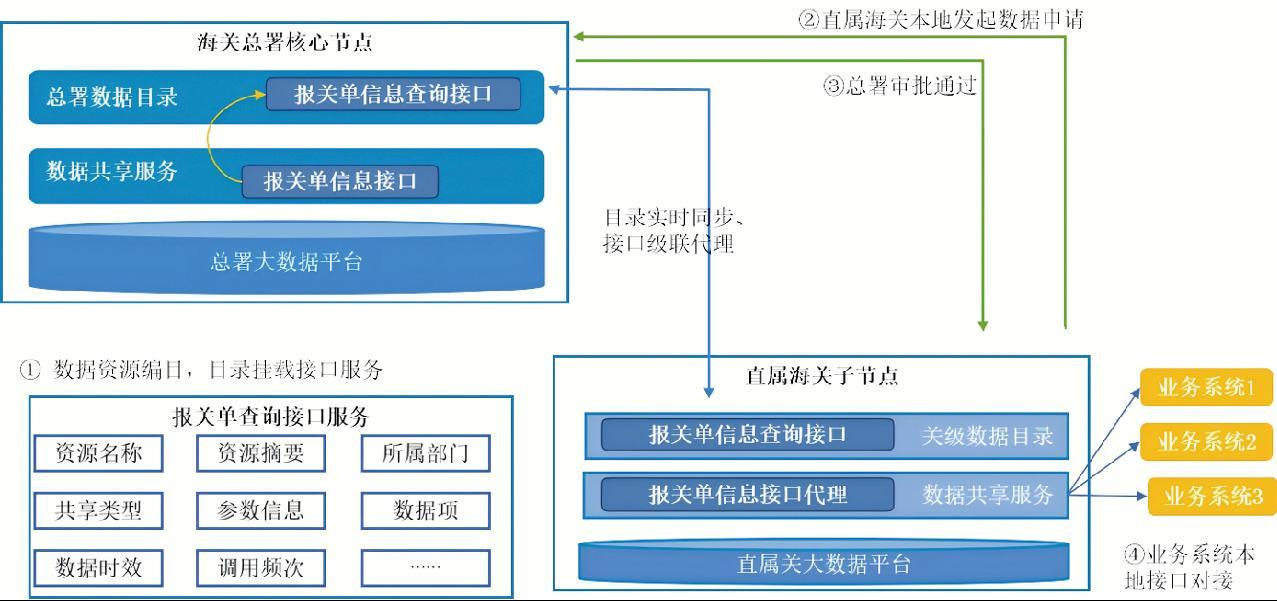
图3 接口方式共享流程图
Fig.3 Interface-based sharing process
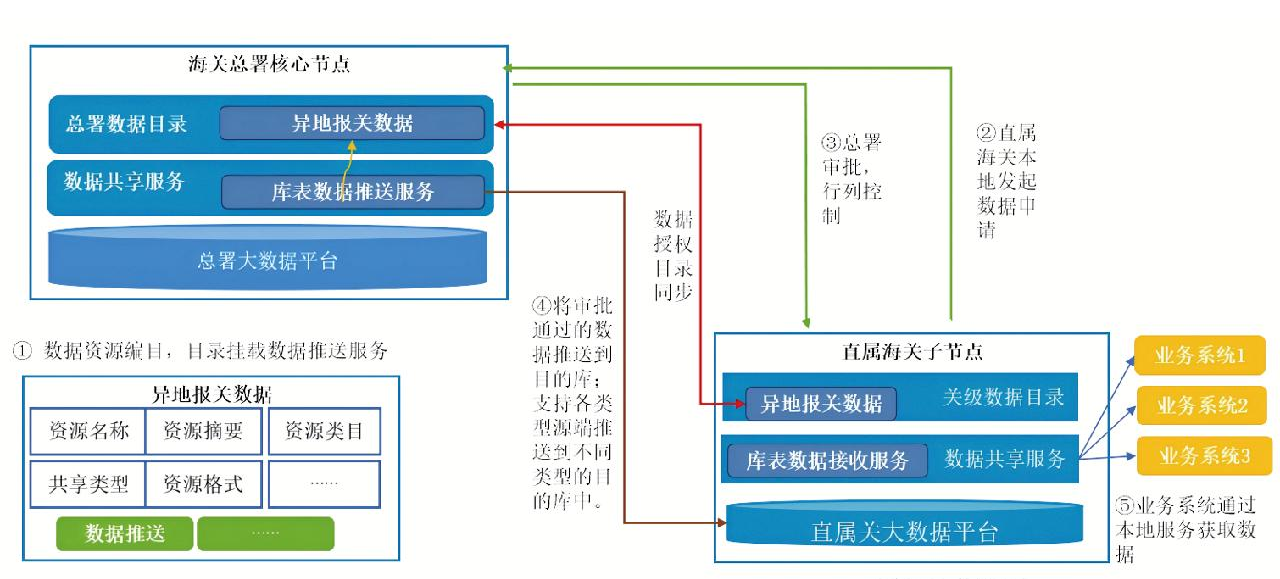
图4 库表交换方式共享流程图
Fig.4 Table-based sharing process
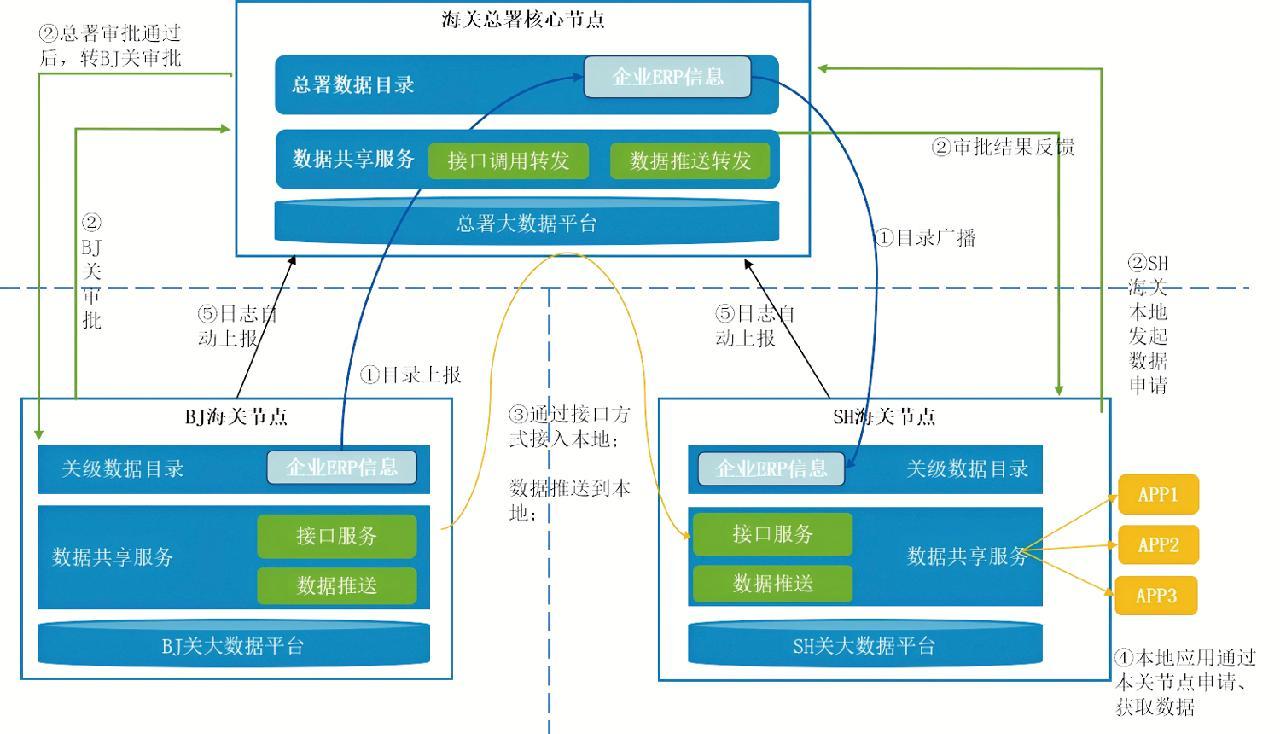
图5 直属海关之间数据共享流程图
Fig.5 Data sharing process between customs offices directly under the leadership of the GAC
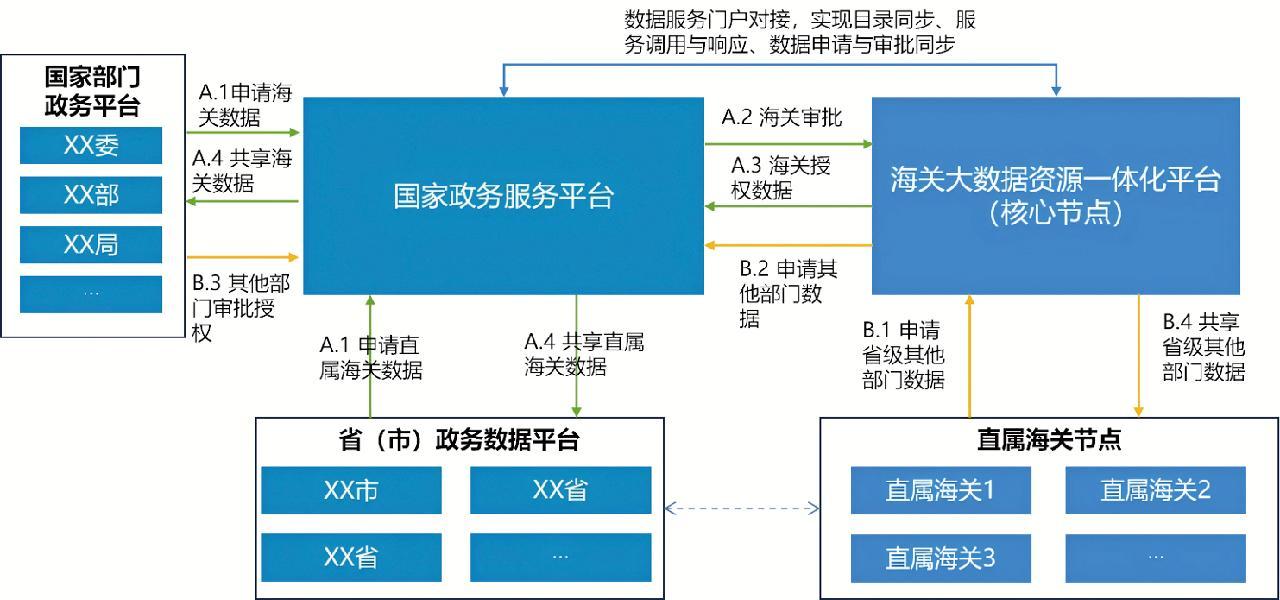
图6 政务数据交换流程图
Fig.6 Government data exchange process
第7卷 增刊
2025年7月
Data Analysis / 数据分析
基于AIGC技术的自动生成分析报告研究
马群凯 1 王 齐 1 王佳蕾 1 李 玄 1 文 杨 1 赵碧君 1 张济凡 1
摘 要 本文聚焦人工智能生成内容(Artificial Intelligence Generated Content,AIGC)的理论研究、经典模型以及在海关领域的应用。其中,理论研究方面,涵盖其基础架构预训练语言模型基本原理、发展历史和架构特点;经典模型方面,介绍了生成式预训练的Transformer模型(Generative Pre-trained Transformer,GPT)和基于Transformer的双向编码器表示模型(Bidirectional Encoder Representations from Transformers,BERT)以及衍生的AIGC概念。在此基础上,通过业务报告自动生成场景,采用业界主流的“大语言模型+知识库”的AIGC技术架构,探索对业务文本信息数据进行自动汇总分析,生成报告或摘要,并对生成结果从可信度和实用性两个方面进行评价。经分析专家团队审核,生成结果可信度和实用性评分均达到预期。
关键词 人工智能生成内容;预训练语言模型;大语言模型
Research on Automatic Generation of Analysis Reports Based on AIGC Technology
MA Qun-Kai1 WANG Qi1 WANG Jia-Lei1 LI Xuan1
WEN Yang1 ZHAO Bi-Jun1 ZHANG Ji-Fan1
Abstract This article focuses on the theoretical research, classic models, and applications of AIGC generative artificial intelligence in the customs field. In terms of theoretical research, it includes the basic principles, development history and architectural features of the underlying infrastructure and pre-trained language models. Regarding classic models, it introduces GPT and BERT as well as the AIGC concept derived from them. In terms of applied research, test scenarios are automatically generated through business reports. The mainstream “large language model + knowledge base” AIGC technical architecture in the industry is adopted to explore the automatic summary and analysis of business text information data, generating reports or summaries, and evaluating the generated results from the aspects of credibility and practicality. After review by the analysis expert team, the credibility and practicality scores of the generated results have both met expectations.
keywords Artificial Intelligence Generated Content; pre-trained language models; large language models
近年来,随着人工智能技术应用逐渐深入,构建智能模型对文本信息进行生成式分析的业务需求逐渐增加。自然语言处理技术的快速发展,应用预训练大模型在海量文本数据中开展无监督(半监督)学习已经成为增强语言模型性能的新方向,并直接催生了人工智能生成内容(Artificial Intelligence Generated Content,AIGC)技术的发展。预训练机制打破了传统语言模型构建时普遍存在的领域隔阂现象,使语言模型的应用模式更加贴近人类习惯。这类模型代表如基于Transformer的双向编码器表示模型(Bidirectional Encoder Representations from Transformers,BERT)和生成式预训练的Transformer模型(Generative Pre-trained Transformer,GPT)等,在多项语言任务测试中仅需在基础模型上进行参数的微调即可达到较好效果。而AIGC同时兼具预训练技术、多模态技术和生成式算法等特点,是目前前沿的人工智能研究方向之一。
海关业务工作中涉及提取、分析大量文本类信息。通过研究AIGC技术,并与典型业务需求相结合,可为海关业务工作智能化升级提供更多技术支持。一直以来,海关信息分析研究方向选择和报告编写工作高度依赖一线业务专家提供的线索及分析人员的经验积累。通过引入AIGC技术,对收集的国际贸易、稽查等相关信息进行汇总,快速生成高质量报告或摘要,有助于分析人员高效了解研究领域的热点信息。
1 理论研究
目前AIGC的核心技术是大语言模型,核心构建手段是预训练方式,应用这些技术构建的生成式大语言模型是目前AIGC的主流研究方向之一,ChatGPT和DeepSeek是其中的典型代表。
1.1 预训练语言模型简介
语言表示的目的是将自然语言(如汉语、英语等)表示成计算机能处理的形式,即用数字化的向量来表示不同的字、词、句、段落等。语言向量表示的两种常用方式分别为独热编码和分布式表示。语言模型即通过制定的训练任务(目标)来更好地学习词向量的分布式表示。例如,早期较有代表性的Word2vec模型,通过设计两种模型任务来学习词的分布式表示。通过上下文的词来预测当前词(Continuous Bag-of-Words模型),以及通过当前词来预测上下文(Skip-gram模型)。
广义上的预训练语言模型可以泛指提前经过大规模数据训练的语言模型,包括早期的以Word2vec、GloVe为代表的静态词向量模型,以及基于上下文建模的CoVe、ELMo等动态词向量模型。预训练模型改善了传统语言模型的两个主要缺陷:一是传统的语言模型只能在少数做好标签标注的数据集上开展训练,无法利用海量的无标注数据进行学习;二是传统语言模型构建需要根据不同的场景任务独立设计模型结构,并进行大量重复学习。由于预训练结合迁移微调的应用方式跳过了大量基础语言特征的学习,使语言任务更加专注于学习具体的业务场景知识,这就极大地加快了模型训练的收敛速度,进一步简化了应用难度。
1.2 预训练语言模型的发展
目前主流的预训练模型都是基于深度学习的神经网络模型发展而来。在深度学习提出早期,Geoffrey E Hinton等[1]发现在无监督学习后接有监督学习的语言模型结构具有较好的效果。2010年, Dumitru Erhan等[2]提出了预训练效果显著的两个猜想:一是具有更好的损失优化能力,二是可以进行更好的正则化。2019年,Nikunj Saunshi等[3]提出了潜在类别的概念,解释了某些预训练模型和下游微调任务之间的关联,并在此基础上证明了下游任务的最大损失不可能超过预训练模型,这样就保证了下游应用的效果。
2013年Word2vec模型的提出开启了预训练模型的先河。2014年GloVe模型引入了动态词向量,增强了语言表示的适应性。2014年Dzmitry Bahdanau等[4]提出了Attention注意力机制,提高了对文本序列中局部重要信息的关注度,并且加快了模型训练的速度。2017年诞生了以注意力机制为基础的Transformer模型,后续被广泛应用的BERT和GPT等模型均是在该模型基础上构建形成。
1.3 架构和经典模型
2017年,Transformer在 Attention注意力机制框架下构建形成[5],主要由3个模块组成:词嵌入(Embedding)模块用于把自然语言转换成数字向量;编码(Encoding)模块用于进行词嵌入的上下文表示计算;解码(Decoder)模块用于将学习到的词向量生成自然语言。Transformer相较于传统的循环神经网络模型(Recurrent Neural Network,RNN),主要有三方面的优势:可以实现并行计算,具有更高的计算效率;可以捕捉序列中不同位置之间的依赖关系,实现上下文感知;采用预训练加微调的方式可以学习到更多的语言特征和模式,微调过程可以根据具体任务进行有监督学习,进一步提高了模型的准确性和泛化能力。
GPT模型诞生于2017年,开创了预训练加微调的大语言模型应用范式,通过仅使用Transformer 模型的解码模块作为特征抽取器,在大规模文本上进行语言知识学习。GPT模型设计的任务是通过一系列前序词来预测下一个单词,主要用来生成下文,属于生成式模型。BERT模型于2018年发布[6],同样基于Transformer构建。BERT模型的设计任务主要有两个,一是通过上下文预测中间词,二是通过上下文预测某句话是否为另一个句子的下文。BERT模型只使用了Transformer的编码模块,不涉及生成下文,只学习上下文的语言表示。
1.4 模型应用
在前述技术理论基础上,业界研究构建出了多个生成式大模型应用,如ChatGPT、通义大模型、盘古大模型等。本文以ChatGPT为例,介绍大模型现阶段应用特征和优化技术。
ChatGPT发布于2022年11月,其特点是可以通过对话的方式执行多模态任务,比如回答查询、撰写邮件、代码、文案、翻译等任务。目前以ChatGPT为代表的生成式大模型在构建过程中均以GPT模型架构为基础,在训练过程中引入强化学习思想,能够学习人类偏好和主观意识[7]。这使得模型可以根据少量的人类反馈结果不断优化模型参数,并生成更符合人类价值观的结果。
目前在使用ChatGPT等生成式大模型过程中,通常可以采用3种方式优化模型输出结果,即参数调优、提示词工程[8],或两者的结合。参数调优按照参数调整的范围不同又可分为全局参数调优和局部参数调优(如参数高效微调,Parameter-Efficient Fine-Tuning,PEFT[9])。一般来说,对于下游特定任务,由于全局数据量支撑性较弱,全局参数调整可能会对模型整体效果产生较大影响,且需要更多的图形处理器(Graphic Processing Unit,GPU)计算资源,因此更多采用微调方式。目前效果较好的有LoRA方法[10]和Soft Prompts方法等。生成式大模型可以通过调整输入得到更优的结果。提示词工程通过构造在角色、背景、目标以及语法结构上有针对性的输入形式或模板,可以更好地帮助大模型“回忆”学到的相关知识,这给研究应用人员提供了另一个除了微调之外即可优化模型输出的有效手段。
2 研究应用
本文选择盘古大语言模型和通义大模型作为研究用预训练语言模型。盘古大语言模型起步版(380亿参数)部署在海关内网,自带知识库,参数为默认值。该模型不能训练只有推理,具备基本自然语言能力,包括阅读理解、知识问答、代码生成、公文写作等能力。通义大模型(720亿参数)部署在互联网网段,可查询互联网资源,通过智能体工具调用。通过分析模型生成结果,不断调整Prompt提示词,并对生成结果从可信度(真实性、幻觉检测、偏见)和实用性(上下文理解、一致性、连贯性) 2个方面进行评价。
研究过程主要涉及提示词的调整。第一轮测试并未专门设计提示词,盘古大语言模型和通义大模型均出现幻觉,自动生成大量与问题无关的内容。从第二轮测试开始,逐步扩充提示词内容,如限定身份(海关业务分析人员)、限定交互风格(专业、严谨)、限定生成内容结构(题目、概述、关键事件回顾、市场背景与挑战、分析与建议、小结)等,大模型输出逐渐与期望接近。
基于分析工作中的研究重点选取木材、固体废物等互联网信息。研究过程中的数据处理包括:将文本转换为txt格式,单个文件大小在1 M以内;处理缺失值和异常值,统一数据格式确保文本的一致性等。
2.1 使用盘古大语言模型
将木材、固体废物等若干篇在互联网搜索得到业务热点文章上传至向量库,在大模型界面中选择智能问答模块,测试对某行业业务文本信息中违法行为的列举、摘要及报告生成功能。
功能列举场景下,输入“请根据木材相关新闻列举违法进出口木材的品类”后,大模型仅根据一篇新闻中的信息进行品类列举,无法实现业务分析人员的统计需求。
摘要生成场景下,输入“请根据违法进出口行为相关新闻生成摘要”,大模型仅根据一篇新闻中的信息进行摘要生成,且基本引用原文,摘要生成效果较差。
报告生成场景下,输入“请对固体废物相关新闻中的信息进行汇总,写一篇业务分析报告”,此版本大模型暂不能根据要求撰写分析报告。
以上为举例说明,研究中每个用例均经多次测试生成成果。对已部署盘古大语言模型生成结果进行分析,在可信度方面:生成结果信息准确无误;结果信息与测试样本数据及常识一致度较高;归纳总结能力较弱,输出结果易受个别样本影响,偏见倾向较高。在实用性方面:对基于上下文的请求理解能力较弱;在不同表述请求下,一致性较差。
在未进行微调和预训练的情况下,预期目标中当前可实现的功能为:输入的问题会实时检索知识库,准确抽取相关信息;问题答案能够查看信息来源,直接比对问答结果与原始信息;大模型能够智能理解文档。改变请求语言的表述方式,可能会出现无法回答的情况;在不同行业中,提出相似请求,效果相差较大,有的可以输出结果,有的无法输出结果,模型对样本数据的理解能力需进一步增强;归纳总结能力、推理能力较弱。
2.2 使用通义大模型
基于互联网数据信息,测试对某行业文本信息中违法行为的列举、摘要及报告生成功能。
功能列举场景下,输入“请根据木材相关新闻列举违法进口木材的品类”,大模型输出的结果包括原因分析、常见木材品类举例、影响和应对措施等。品类列举全面且与实际情况相符,能够满足分析人员相关需求。
摘要生成场景下,输入“请根据某商品违法进出口新闻生成摘要”,大模型输出各国打击某商品违法进出口的情况概要,列举了海关、警方破获案件情况,并给出打击行动的意义。大模型能够对相关新闻进行提炼,且能将多篇新闻摘要进行汇总,基本满足分析人员需求。
报告生成场景下,输入“请汇总2023年查获走私固体废物的新闻写一篇分析报告”,大模型输出的内容包括报告题目,以及概述、2023年关键事件回顾(海关专项打击行动、典型案例发布)、市场背景与挑战、分析与建议(加强国际合作、完善法律法规、公众参与与教育)、小结等内容。大模型具有一定的报告生成能力,但与分析人员的需求差异较大,结构框架需要调整,内容深度不足。
基于Prompt提示词工程生成报告场景,向大模型提供分析报告框架,包括摘要、引言、案件摘要、趋势分析、政策与手段、挑战、结论与建议等部分,其中案件摘要部分要列举2023年3个较大的案件,并对相关名词进行解释,如违法进口活动趋势是指活动的变化趋势,执法行动趋势是指执法行动的效率和效果。要求大模型根据上面的分析报告框架,写一份关于2023年我国查获的走私固体废物的分析报告。大模型的输出结果包括题目、摘要、引言(目的和背景)、案件摘要(3个案例)、趋势分析(违法进口活动趋势、执法行动趋势)、政策与手段、挑战、结论与建议等章节。通过Prompt提示词工程,大模型可以根据分析人员提供的结构框架,进行分析报告的初步生成,但内容较浅显,仅能为分析人员提供参考。
以上为举例说明,研究中每个用例均经多次测试生成成果。对此版本通义大模型生成结果进行分析,在可信度方面:生成结果信息比较准确;生成结果出现幻觉程度较低;生成结果信息与测试样本数据及常识一致度较高;大模型通过归纳总结若干篇参考文章输出结果,存在一定程度的偏见,但偏见较低。在实用性方面:对基于上下文的请求理解能力强;在不同表述请求下,一致性较强。
相较于内网部署的盘古大模型版本,在互联网端的通义大模型输入相同要求,能够得到上下文理解和归纳总结能力强、一致性和连贯性相对较好的输出结果。
互联网环境下的大模型产品借助在线搜索功能,能够提供的情报语料范围更广。但由于来源权威性参差不齐、搜索结果不可复现等原因,多次提出同样的要求后,得到的输出结果存在一定差异。
比较提示词工程前后的结果:在未进行Prompt提示词工程的情况下,可基本实现列举功能和摘要提取功能;分析报告生成功能与需求差异较大;通过Prompt提示词工程调整后,分析报告输出结构明显优化,但内容质量有所下降,仅可供分析人员进行参考。
与传统人工分析相比较,在做好检索增强生成(Retrieval Augmented Generation,RAG)参数设置和Prompt提示词的前提下,大模型能够按照分析人员要求快速生成分析报告,能够大大提升信息提炼汇总的效率。但大模型输出的内容较专家尚有一定的差距,需要在此基础上进行人工完善。
与长短期记忆网络(Long Short Term Memory,LSTM)等机器学习算法比较,传统的机器学习算法只能适用于特定的场景,如文本分类、地址识别等特定场景,在语义理解和无监督学习等领域距离大模型尚有差距。
最终生成的结果经分析专家团队审核,其可信度和实用性评分均达到预期。
3 研究结果与应用建议
3.1 研究结果
本文对AIGC技术理论,基础架构如预训练模型BERT和GPT等,及发展历程进行了梳理研究,并分析该技术领域发展近况和业界应用情况。在实际测试中应用 Prompt提示词工程技术对大模型结果进行优化,初步验证了大模型在海关分析报告或摘要生成场景下应用的技术可行性。
本文聚焦木材、固体废物等重点敏感物品,开展品类信息提取、热点文章摘要生成、分析报告生成等工作,并选取木材、固体废物等热点文章若干篇形成知识库。初步实现了在分析场景中对某特定行业非法进出口商品品类的列举、新闻摘要生成和分析报告生成,能够在分析场景中实现海量信息的关键要素提取,并按照提示词指定的要素和逻辑进行表达输出,对于分析人员确定研究方向起到一定的引导作用,也为报告编写提供了便利,有助于提升工作效率。由于内网部署的盘古大模型只能推理不能训练且缺少数据统计功能,互联网环境中使用的通义大模型虽然功能强大但缺少海关内部数据支撑,研究成果距离真正的分析报告尚有差距。
3.2 应用建议
随着大数据、人工智能等新技术应用深入开展,海关业务场景逐渐拓展到对复杂文本信息的分析和应用。预训练大模型的研究和应用越发具有现实意义。今后将结合海关工作实际,继续跟进预训练语言模型及AIGC应用等新技术的发展,如辅助写作等。此外,还可以在海关内网部署DeepSeek 671B等大语言模型,引入Agent能力和数据统计模块,对报关单等相关数据开展查询、清洗和分析。从完善Prompt提示词等角度对报告生成能力进行优化,不断充实报告内容,持续提升报告成果质量。
4 结语和展望
本文聚焦大模型技术在海关业务分析场景中的应用。通过引入“大语言模型+知识库”的AIGC技术架构,使用盘古大模型和通义大模型,探索对业务文本信息进行自动汇总分析,生成报告或摘要,生成结果的可信度和实用性评分均达到预期。下一步,将结合大模型微调和智能体技术,实现结构化数据提取、报告分析框架学习、相关法律法规大模型调用等更加全面的功能。
参考文献
[1] Geoffrey E Hinton, Simon Osindero, Yee-Whye Teh. A fast learning algorithm for deep belief nets[J]. Neural Computation, 2006, 18(7): 1527- 1554.
[2] Dumitru Erhan, Aaron Courville, Yoshua Bengio, et al. Why does unsupervised pretraining help deep learning[J]. In Proceedings of AISTATS, 2010: 201-208.
[3] Nikunj Saunshi, Orestis Plevrakis, Sanjeev Arora, et al. A theoretical analysis of contrastive unsupervised representation learning[C]. In Proceedings of ICML, 2019: 5628-5637.
[4] Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio. Neural Machine Translation by Jointly Learning to Align and Translate[DB/OL]. https://doi.org/10.48550/arXiv.1409.0473.
[5] Ashish Vaswani, Noam Shazeer, Nike Parmar, et al. Attention Is All You Need[DB/OL]. https://doi.org/10.48550/arXiv.1706.03762.
[6] Jacob Devlin, Ming-Wei Chang, Kenton Lee, et al. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[G]. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), 2016: 4171-4186.
[7]王晓华. 从零开始大模型开发与微调-基于PyTorch与ChatGLM[M]. 北京: 清华大学出版社, 2018: 250-251.
[8]王东清, 芦飞, 张炳会, 等. 大语言模型中提示词工程综述[J]. 计算机系统应用, 2025, 34(1): 1-10.
[9]王浩, 王珺, 胡海峰, 等. PMoE: 在 P-tuning 中引入混合专家的参数高效微调框架[J/OL]. 计算机应用研究. https://doi.org/10.19734/j.issn.1001-3695.2024.11.0484.
[10]汪伦, 艾斯卡尔·艾木都拉, 张华平, 等. 基于大语言模型的开源情报摘要生成研究[J/OL]. 情报理论与实践. https://link.cnki.net/urlid/11.1762.G3.20250214.1507.002.
第一作者:马群凯(1982—),男,汉族,吉林延吉人,硕士,高级数据建模分析师,主要从事人工智能工作,E-mail: mqk017@126.com
1. 全国海关信息中心(全国海关电子通关中心) 北京 100005
1. National Information Center of GACC (General Administration of Customs of China), Beijing 100005
第7卷 增刊
2025年7月
Data Analysis / 数据分析
大模型在海关统计工作中的应用研究
杜琳美 1 吕 涛 1 毕 滔 1 陈 衎 1
摘 要 大模型因其优秀的交互性和通用性已广泛应用于诸多领域。本文从大模型在政务领域的研究进展和应用情况出发,结合海关统计信息系统在数据规模激增、用户友好交互、实时决策需求等方面的挑战,系统探讨了大模型在数据采集、智能交互和智能预测等场景的应用潜力。另外,分析了大模型在海关统计工作中实际应用时面临的挑战并给出对策建议。随着大模型技术的持续优化,其在海关统计中的应用将推动数据治理效能的全面提升,为海关统计工作提供更强技术支撑。
关键词 大模型;海关统计;人工智能;数字政府
Research on the Application of Large Models
in Customs Statistics
DU Lin-Mei 1 LYU Tao 1 BI Tao 1 CHEN Kan 1
Abstract Large-scale AI models have been extensively deployed across multiple disciplines owing to their superior interactivity and cross-domainadaptability.This paper examines the research advancements and implementation cases of large-scale models in government affairs. To addressing critical challenges in information system for customs statistics, including explosive data growth, user-friendly interactionandtime-sensitivedecision-makingrequirements, it conducts a methodological investigation into the application prospects of these models across key scenarios: automated data acquisition, intelligent human-computer collaborationand data-driven predictive modeling. Furthermore, the paper identifies implementation barriers specific to customs statistical systems and formulates evidence-based mitigation strategies. With the continuous optimization of large-scale model technology, its application in customs statistics will promote the overall improvement of data governance efficiency and provide stronger technical support for customs statistics work.
Keywords large model; customs statistics; artificial intelligence; digital government
随着全球贸易蓬勃发展与数字化进程加速演进,海关作为国家进出境监督管理机关,积累了海量数据。海关数据来源广泛,包括报关单申报数据、企业备案信息、物流数据、跨境电商平台数据等。对贸易数据进行高效精准的统计分析,能够准确反映外贸形势和经济运行状况,为国家经贸政策制定提供重要依据。传统的数据管理方法难以满足快速、精准、智能的监管与决策需求。大模型作为人工智能领域的突破性技术,凭借其强大的数据处理能力、复杂模式识别和深度语义理解等特性,为海关统计领域带来了新的发展契机。
如何发挥大模型在海关统计工作中的潜力,解决数据统计分析中的现实问题,是提升海关数据管理与数据服务能力的关键课题之一。本文系统分析了大模型技术在海关统计场景中的现实需求及创新应用场景,探讨大模型在提升数据应用效能、便利统计工作、挖掘数据价值等方面的实际作用。同时,深入剖析大模型应用中的技术挑战,为海关统计工作与大模型融合应用提供参考。
1 大模型技术
1.1 大模型技术的理论基础
大模型(Large Model)是指基于海量数据训练、具有极大参数规模的深度神经网络模型。大模型是大语言模型(Large Language Model,LLM)概念的延伸。从输入数据种类区分,大模型包含语言大模型、视觉大模型和多模态大模型等。如今流行的大模型多数基于Transformer框架[1]。Transformer框架基本结构如下。
1.1.1 自注意力层
自注意力(Self-attention)层[1]通过计算输入序列中词与词相关性,动态分配权重,具有发掘长输入序列上下文关联性的能力。自注意力核心原理表达如下:
(1)
式(1)中, 、
、 、
、 指输入序列经分词(Tokenize)、嵌入(Embedding)、线性变换后形成的矩阵。Softmax函数为归一化指数函数。
指输入序列经分词(Tokenize)、嵌入(Embedding)、线性变换后形成的矩阵。Softmax函数为归一化指数函数。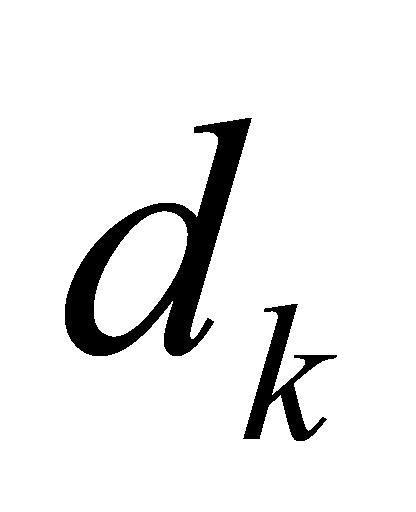 为矩阵
为矩阵 中键向量的维数,除以
中键向量的维数,除以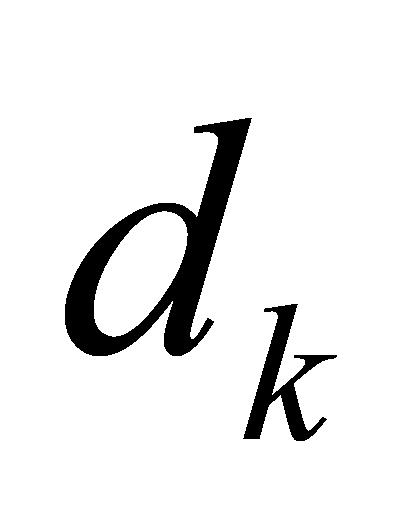 可以缓解梯度消失问题,提升计算稳定性。
可以缓解梯度消失问题,提升计算稳定性。
1.1.2 全连接前馈层
全连接前馈(Fully-connected Feed-forward)层是Transformer框架中的“海马体”,负责记忆模型预训练文本的语义模式,提供了类似键值对(Key-value Pair)的记忆功能,占据了模型约2/3的参数[2]。核心原理如下:
(2)
式(2)中, 为输入向量,
为输入向量, 和
和 分别为第一层和第二层的权重参数,
分别为第一层和第二层的权重参数, 和
和 分别为第一层和第二层的偏置参数。第一层起到键的作用,第二层起到值的作用。
分别为第一层和第二层的偏置参数。第一层起到键的作用,第二层起到值的作用。
1.1.3 归一化层
归一化(Normalization)层负责计算输入数据的均值和标准差,并归一化输入数据。归一化层可以加速模型训练过程并提升模型性能[3]。核心操作如下:
(3)
式(3)中, 为输入向量,
为输入向量,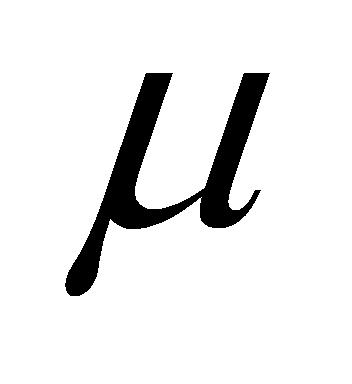 和
和 分别为
分别为 的均值和方差,
的均值和方差, 和
和 为可学习参数。
为可学习参数。
1.1.4 编码器与解码器
Transformer框架包含编码器和解码器两部分,两者均由自注意力层和全连接前馈层结合残差连接(Residual Connection)相互连接构建而成。两者的基本结构示意如图1所示。
基于Transformer框架,衍生出以下3种流行架构:(1)编码器(Encoder-Only)架构,专注于对输入序列进行理解分析,生成文本时往往会带来更多资源消耗,代表模型有GPT-1[4]、GPT-2[5]、GPT-3[6]、ChatGPT[7]等;(2)解码器(Decoder-Only)架构,采用自回归生成策略,每步生成仅考虑已生成文本,适合大量文本输出场景,代表模型有BERT[8]、RoBERTa[9]、ALBERT[10]等;(3)编码器-解码器(Encoder-Decoder)架构,模型参数规模相较于前两者往往更为庞大,一般在处理长序列输入时面临更大计算压力,同时处理复杂序列的能力更加强大,代表模型有T5[11]、BART[12]、DeepSeek等。
随着参数数量、训练数据或训练步骤的提升,模型解决特定问题的能力突然提升,这种现象称之为涌现能力(Emergent Ability)[13]。面对多步骤构成的复杂任务,当模型参数规模大到一定程度时,效果会急剧增长;而在模型规模小于某个临界值时,模型基本不具备任务解决能力。通过微调(Fine Tune)、提示词(Prompt)工程等方法,可以提升预训练通用大模型在特定场景下的应用效果。
1.2 大模型技术在政务领域的应用现状
我国大模型近年来发展迅猛,截至2025年3月31日,共有346款生成式人工智能服务在国家网信办完成备案;对于通过API接口或其他方式直接调用已备案模型能力的生成式人工智能应用或功能,共有159款生成式人工智功能在地方网信办完成登记[14]。2025年1月20日,DeepSeek-V3和DeepSeek-R1开源大模型的发布引发新一轮大模型应用热潮。2025年2月8日,深圳市龙岗区在政务外网信创环境首先完成DeepSeek-R1本地化部署[15]。根据各级政府官网公开消息,截至2025年3月,我国已有72个省级或市级政府部门完成DeepSeek模型私有化部署[16]。在政务领域,大模型因其优秀的交互性、强大的文本及图像处理能力,在政民互动、政务办公、行政执法、政策分析等等方面能够发挥独特作用(图2)。
图2 大模型在政务领域的部分应用场景
Fig.2 Application scenarios of large models in the government sector
2023年7月,《生成式人工智能服务管理暂行办法》印发,鼓励生成式人工智能在各行业和领域的创新应用,探索应用场景,构建应用生态体系。近年来,多地不断完善大模型支持政策。仅在2024年7月,《北京市推动“人工智能+”行动计划(2024—2025年)》《上海市促进工业服务业赋能产业升级行动方案(2024—2027年)》《深圳市加快打造人工智能先锋城市行动方案》《支持人工智能全产业链高质量发展的若干措施》(杭州市人民政府)四地政策文件印发实施。政策不断加力完善,从算力基础设施建设、模型生态打造、人才队伍支撑等多维度提供配套支持。
2 海关统计工作的现状和需求
根据《中华人民共和国海关统计条例》规定,海关统计是海关依法对进出口货物贸易的统计,是国民经济统计的组成部分。海关统计是国家宏观经济调控和贸易政策制定的重要支撑。当前,从报关单等数据的采集和录入到统计数据的分析计算再到统计报表和简报的生成已实现自动化。但多变复杂的国际贸易形势对海关统计决策支撑能力的灵活性和即时性提出了更高要求。
2.1 海关统计工作现状
2.1.1 海关统计数据采集与分析
海关积极应用先进信息技术,通过电子化报关系统和数据抓取技术,初步实现了统计数据采集的智能化和自动化。在数据处理环节,运用自动化算法和规则引擎对采集数据进行初步筛选,去除冗余数据、错误数据和识别异常录入。数据安全与隐私保护方面,海关在数据采集、传输和存储过程中实施加密、权限控制和日志记录等多重保护措施。在跨部门数据共享方面,海关建立了统一的数据管理机制,确保数据交换的规范性,实现全流程数据追溯和监管。
2.1.2 海关统计报表的生成与发布
统计报表作为海关统计信息的主要展示形式,直观反映进出口贸易的基本运行状况,是经贸措施制定和调整的重要依据。海关统计报表种类繁多,各指标之间相互关联且数据基数庞大,发布的时效性和准确性受到社会公众关注。目前,海关统计报表主要依靠定期数据汇总和人工调整设计,在数据更新、信息交互和数据展示方面还有提升空间。现有海关统计报表生成通过电子化报关系统和数据采集平台获取基础数据,在完成数据清洗和标准化后,形成中间数据库表,在此基础上计算并校验进出口额、同环比等统计指标,最后根据报表模板生成固定格式报表。报表新增或调整基于海关业务人员和技术人员的大量沟通和共同操作。可视化、智能化的报表维护和定义方式能够便捷海关业务人员,减轻基层工作负担且提升报表时效性和灵活性。
2.2 海关统计工作需求
随着跨境电商、离岸贸易、新型供应链模式的快速发展以及国际贸易形势的快速变化,海关贸易数据的体量、种类和实时性要求均大幅提高。因此,如何在保证数据质量和安全的前提下,实现海关统计数据的高效治理和深度应用,成为当前亟待解决的核心问题。
(1)构建更加智能的数据检控机制,提升统计原始资料质量。统计原始资料直接关系到统计数据的准确性。构建基于大模型的智能模型组,发掘可能存在的单据填制不规范、虚报出口骗取退税、瞒报单价或原产地逃税等行为,提升数据准确度。
(2)构建更加友好的数据交互服务,便利社会公众和业务人员取数用数。在保证数据查询准确性的基础上,提供智能化问数服务、智能化查询服务、智能化指标解答服务、智能化组合报表生成服务,提供更高质量统计数据公共服务。
(3)构建更加准确的预测预警系统,应对突发事件和异常波动。以多维度数据基础,搭建多样预测模型和情景分析框架,深入分析因果关系,揭示数据内在规律,支持即时决策和风险防控。在面对国际贸易摩擦、经济危机等外部冲击时模拟情景,评估各政策选项可能带来的影响,提供政策方案参考。
3 大模型在海关统计中的应用场景分析
3.1 数据质量检控
数据质量检控是指通过人工和技术手段,判定微观数据真实性,剔除虚假和无效数据,提升统计数据质量的行为。常见的数据质量检控手段使用3-sigma原则、四分位法等,逻辑预置于系统中,缺乏灵活性。
针对报关单等单据数据的特定风险场景,例如短期贸易量激增、新注册企业激增、物流兜转等,结合专家经验发掘数据特征,使用大模型构建智能模型组,开展风险识别工作。除了明确的风险场景,大模型还可以挖掘潜在的风险特征。通过对查获存在虚假贸易等行为企业和正常企业的贸易数据标注,结合监督学习等手段挖掘企业风险表征,为人工判别提供参考。
此外,结合大模型多模态能力,可以构建多数据来源的风险甄别模型。例如,构建港口集装箱-贸易量模型,对于非大宗散货的货物,贸易量与港口集装箱数正相关。使用大模型分析港口集装箱卫星照片变化与贸易量变动,预警两者的偏差情况,为进一步进行人工分析提供线索。基于不同来源的外部数据,可以辅助海关工作人员发现数据风险线索,更好地完成数据质量检控工作。
3.2 智能交互
传统的数据查询和报告报表生成维护方式难以满足用户对统计数据的多维交互和深度信息挖掘的需求。构建智能交互系统,将自然语言输入转化为结构化查询语句,把结果以指定形式输出,实现从数据检索到信息反馈的全流程自动化,有效帮助业务人员便捷快速地设计调整报表,进一步提高统计数据的利用效率和决策支持能力。
3.2.1 动态可视化的交互
动态可视化系统支持折线图、柱状图、饼状图、热力图、树状图以及网络关系图等多种图形方式,全面反映海关统计数据在时空维度上的变化。决策者通过拖拽、缩放、过滤等交互操作,自由组合不同数据视角,从宏观到微观层面对数据进行深入剖析[17]。例如,当某地区的进出口数据出现突变时,系统自动生成预警提示,提供数据信息细节和历史对比,协助决策者迅速定位异常原因。将大模型技术和BI(Business Intelligence)设计工具相结合,可以提升报表定义维护方法的灵活性。业务人员通过BI工具绘制报表模板,通过行索引和列索引,给出行列交叉点数据的采集方式和过滤条件。大模型提供BI使用建议和结果分析等辅助功能,进一步提升报表的维护操作直观性和准确度。
3.2.2 自然语言驱动的交互
传统数据查询工作需要海关业务人员掌握结构化查询语言(Structure Query Language,SQL),存在一定技术门槛。自然语言驱动的查询系统核心在于,将用户的自然语言输入转换为结构化查询语句,对接至数据库查询结果,提升信息检索效率。通过预训练和微调技术,大模型能够准确理解用户输入的查询需求,自动提取时间、地域、商品编码等关键要素,并将其转化为系统内部可识别的查询条件[4]。即使用户不具备专业的计算机知识,也能够直接通过日常语言获取所需数据和分析报告。例如,用户输入“2023年《区域全面经济伙伴关系协定》(RCEP)成员国对我国机电产品出口增长最快的3个国家的机电产品出口量”,系统从海关系统数据库和知识库中提取出信息,由大模型构建图表展示和生成报告。用户还可以就查询结果提出补充问题或进一步探讨数据背后的意义,模型通过语义理解和关联分析,提供详细解答和相关数据补充,实现人机交互无缝衔接[5]。结合大模型的报表生成,预计将原有的报表生成和调整流程由2个月左右压缩至数天,便利相关工作的开展。
3.3 智能预测
现有的传统分析预测模型虽然在一定程度上能够捕捉数据的周期性和趋势性,但面对多因素干扰、突发事件的影响时,其预测精度存在一定不足。智能预测技术通过引入深度学习模型、Transformer架构以及先进的机器学习时间序列分析算法,能够对历史数据进行深度特征提取和融合建模,提供更为准确的预测。
3.3.1 基于大模型技术的时间序列预测
在国际贸易环境中,海关统计数据不仅具有海量性和多样性,而且受到经济、政治、市场波动等多重因素的影响,数据变化呈现出复杂时序特征。传统的时间序列分析方法,如自回归整合移动平均模型(Autoregressive Integrated Moving Average Model)、季节性自回归整合移动平均模型(Seasonal Autoregressive Integrated Moving Average Model)等,虽然在一定程度上能揭示数据的周期性和趋势性,但面对多因素交互、异常波动和非线性关系时,其预测效果往往受限。基于大模型的时间序列预测则通过深度学习、Transformer架构和长短期记忆网络(Long Short-Term Memory Network)等先进技术,对历史数据进行深度特征提取和模式识别,从而实现对贸易数据的更精准预测[18]。大模型技术能够自动学习和捕捉数据中的微妙变化和长期依赖关系,通过大规模并行计算和多层次特征融合,显著提高预测精度[19]。在模型训练过程中,采用深度神经网络结合Transformer架构,使得模型能够在捕捉短期波动的同时,有效识别长期趋势和季节性特征。与传统线性模型相比,基于大模型的时间序列预测不仅具备更高的容错性和适应性,还能自动调整模型参数,适应外部经济环境的动态变化。通过历史数据训练,模型可以识别出影响进出口总量、单价波动及贸易差额等指标的关键因素,并通过自注意力机制,提供更为细致和精准的预测结果[2]。基于大模型的时间序列预测系统支持结果解释和敏感性分析,通过可视化工具直观展示关键特征变量的影响权重和变化趋势,提供深层次数据解读。
3.3.2 融合因果分析的大模型决策支持
在多因素共同作用影响海关进出口数据的背景下,因果关系的挖掘成为预测系统中不可或缺的一环。传统的因果分析方法往往依赖于线性回归或结构方程模型,其在面对高维数据、多重共线性以及非线性关系时存在一定局限,而大模型技术通过融合深度学习、图神经网络以及强化学习算法,实现了对因果关系的更加全面和精准的捕捉[20]。首先,该技术能够通过对历史进出口数据和外部经济指标(如汇率波动、国际政治局势、国内经济政策调整等)进行特征提取,通过构建多维度的变量网络图,实现因果链条的全面梳理。大模型驱动的因果分析不仅在数据的多维度整合和变量关系的动态调整上表现突出,还具备自我修正的能力。利用先进的反事实分析方法,这种系统能够模拟在不同政策情境下各变量变化对进出口数据的影响,从而为政策制定提供量化依据和风险预警[21]。此外,模型还可以引入迁移学习和对抗训练技术,使得因果关系分析具有更高的稳健性和泛化能力,确保在面对新兴贸易形势时,依然能够提供稳定、可靠的决策建议。
4 面临的挑战与对策建议
4.1 模型输出结果问题
大模型的预测和推理能力依赖训练数据,如果模型训练使用的数据中存在噪声或错误信息,会干扰模型学习,导致产生模型幻觉或预测偏差。在海关贸易统计领域,数据误差或模型幻觉可能导致错误结果,误导外贸形势研判。目前海关已经建立了较为完善的数据管理体系,包括数据采集、清洗、预处理和验证,能够保障数据的时效性和完整性,但仍需有针对性地处理历史数据中的偏差和噪音,可以开展人工集中审核或利用第三方验证工具进行双重审核,减少数据问题对模型的影响。同时,在模型应用过程中,需建立多层次结果验证和人机协同机制,提升输出的可靠性。
4.2 数据安全问题
海关数据涉及企业商业秘密,大模型训练和推理时需要频繁调用这些数据。为确保数据安全,训练海关统计行业大模型时,在海关内网配置训练环境和导出数据,在数据安全可控的商业环境下进行训练,需要综合安全性和性价比进行选择。无论选择哪种方式,都需要制定在大模型训练环境下海关数据安全使用规范,明确数据出域管理要求,增强数据安全管控技术手段,采用先进加密技术,确保数据传输与存储的安全。
4.3 模型结果输出问题
大模型输出结果可解释性差,这在监管决策对可靠性要求极高的情况下是一个关键问题。大模型的“黑箱”性质要求使用者自行验证输出结果正确性和合理性。在模型设计中,结合基于微调和提示词等技术,确保大模型输出符合业务逻辑,降低模型输出的不确定性。另外,人机协同机制是不可或缺的。现阶段大模型仅可作为辅助工具,输出结果只可作为参考,高风险决策必须由人工进行复核和校正。在关键领域应用大模型,配备专业的风控和合规团队,核实大模型的判断,确保决策的合理性是十分必要的。
5 结语
大模型自从2017年Transformer框架发布之后迎来了迅速发展的时期,模型的参数规模、处理和生成能力日新月异。目前大模型已经在政务领域得到了广泛应用,包括但不限于文档校对、语言翻译、行为识别、政策问答等。
根据海关统计工作的实际需要,通过模型预训练、微调、蒸馏、迁移学习等手段,通过大模型与现有系统和人工智能模型集成,可以在数据质量管理、数据查询与交互、数据预测与决策支持等方面提供支撑,提升工作成效。值得注意的是,在海关统计应用大模型的过程中,同样应该注意引入大模型可能带来的可靠性、安全性和稳定性等方面的问题。海关统计工作因其特殊性,对模型要求更严格,在模型参数规模提升的同时,平衡模型性能和成本同样是重要课题。随着大模型技术的持续优化,其在海关统计中的应用将推动数据治理效能的全面提升,为贸易政策制定提供更精准、更快速、更智能的决策支持。
参考文献
[1] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C/OL]//Advances in Neural Information Processing Systems 30 (NIPS 2017). Red Hook: Curran Associates, Inc., 2017: 5998-6008 (2017-06) [2025-05-08]. https://papers.nips.cc/paper_files/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf.
[2] GEVA M, SCHUSTER R, BERANT J, et al. Transformer feed-forward layers are key-value memories [EB/OL]. (2020-12-29) [2023-10-01]. arXiv:2012.14913. https://arxiv.org/abs/2012.14913.
[3] BA J L, KIROS J R, HINTON G E. Layer normalization [EB/OL]. (2016-07-21) [2025-05-08]. arXiv:1607.06450. https://arxiv.org/abs/1607.06450.
[4] Radford A, Narasimhan K, Salimans T, et al. Improving language understanding by generative pre-training [R/OL]. San Francisco: OpenAI(2018-06-11) [2023-10-01]. https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf.
[5] RADFORD A, WU J, CHILD R, et al. Language models are unsupervised multitask learners [EB/OL]. San Francisco: OpenAI, 2019 (2020-06-01) [2025-03-08]. https://storage.prod.researchhub.com/uploads/papers/2020/06/01/language-models.pdf.f.
[6] Brown T, Mann B, Ryder N, et al. Language models are few-shot learners[J]. Advances in neural information processing systems, 2020, 33: 1877-1901.
[7] Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. Advances in neural information processing systems, 2022, 35: 27730-27744.
[8] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[C]//Proceedings of the 2019 conference of the North American chapter of the association for computational linguistics: human language technologies, volume 1 (long and short papers). 2019: 4171-4186.
[9] LIU Y, OTT M, GOYAL N, et al. ROBERTA: A robustly optimized BERT pretraining approach [EB/OL]. (2019-07-26) [2025-05-08]. arXiv:1907.11692. https://arxiv.org/abs/1907.11692.
[10] LAN Z, CHEN M, GOODMAN S, et al. ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations [EB/OL]. (2019-09-26) [2025-05-08]. arXiv:1909.11942. https://arxiv.org/abs/1909.11942.
[11] Raffel C, Shazeer N, Roberts A, et al. Exploring the limits of transfer learning with a unified text-to-text transformer[J]. Journal of machine learning research, 2020, 21(140): 1-67.
[12] LEWIS M, LIU Y, GOYAL N, et al. BART: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension [EB/OL]. (2019-10-29) [2025-05-08]. arXiv:1910.13461. https://arxiv.org/abs/1910.13461.
[13] WEI J, TAY Y, BOMMASANI R, et al. Emergent abilities of large language models [EB/OL]. (2022-06-15) [2025-05-08]. arXiv:2206.07682. https://arxiv.org/abs/2206.07682.
[14]国家互联网信息办公室. 国家互联网信息办公室关于发布生成式人工智能服务已备案信息的公告 (2025年1月至3月)[EB/OL]. (2025-04-08)[2025-05-21]. https://www.cac.gov.cn/2025-04/08/c_1745817775881843.htm.
[15]龙岗政府在线. DeepSeek赋能!龙岗开启智慧政务新篇章[EB/OL]. (2025-02-11) [2025-03-10]. https://www.lg.gov.cn/xxgk/xwzx/zwdt/content/post_11994841.html.
[16]至顶网. “DeepSeek+政务”全国部署图表: 多地政府加快AI+政务落地进程[EB/OL]. (2025-03-11) [2025-03-18]. https://insights.zhiding.cn/2025/0311/3164201.shtml.
[17] Wang Y, Wald I, Wu Q, et al. IEEE transactions on visualization and computer graphics[J]. IEEE transactions on visualization and computer graphics, 2019, 25(6): 2168-2180.
[18] Salinas D, Flunkert V, Gasthaus J, et al. DeepAR: Probabilistic forecasting with autoregressive recurrent networks[J]. International Journal of Forecasting, 2020, 36(3): 1181-1191.
[19] Lim B, Arık S Ö, Loeff N, et al. Temporal fusion transformers for interpretable multi-horizon time series forecasting[J]. International Journal of Forecasting, 2021, 37(4): 1748-1764.
[20] Shalit U, Johansson F D, Sontag D. Estimating individual treatment effect: generalization bounds and algorithms[C]. International conference on machine learning. PMLR, 2017: 3076-3085.
[21] LOUIZOS C, SHALIT U, MOOIJ J M, et al. Causal effect inference with deep latent-variable models [C/OL]//Advances in Neural Information Processing Systems 30 (NIPS 2017). Red Hook: Curran Associates, Inc., 2017: 6449-6459 (2017-06) [2025-05-08]. https://papers.nips.cc/paper_files/paper/2017/file/94b5bde6de888ddf9cde6748ad2523d1-Paper.pdf.
第一作者:杜琳美(1978—),女,汉族,贵州安顺人,硕士,副高级工程师,主要从事统计信息系统建设、数据安全管理工作,E-mail: dulinmei@163.com
1. 全国海关信息中心(全国海关电子通关中心) 北京 100005
1. National Information Center of GACC (General Administration of Customs of China), Beijing 100005
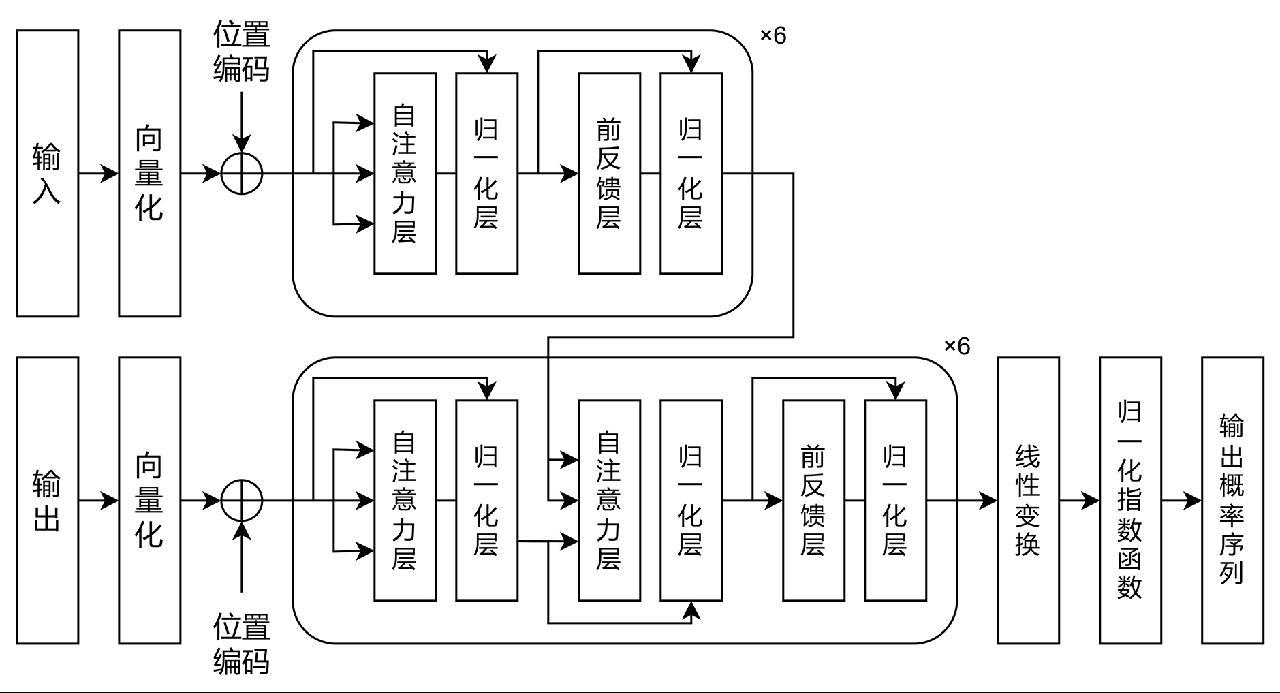
图1 Transformer框架中编码器和解码器的基本结构图[1]
Fig.1 Basic structure diagram of the encoder and decoder in the transformer framework[1]
第7卷 增刊
2025年7月
Data Analysis / 数据分析
光学字符识别技术研究
及在海关监管中的应用
孟庆铎 1 秦 力 1 宗超飞 2
摘 要 本文研究了基于深度学习的文本图像识别技术及其在相关行业中的应用现状,并构建了兽医卫生证书识别模型。研究结果表明,通过引入多维度质量评估与异常识别、形态学搜索模板匹配以及知识蒸馏模型优化等一系列算法改进措施,有效解决了大规模证书识别处理中的时效性和准确性问题,有助于海关实现证书的自动化审核,进而提升通关效率和管理水平。
关键词 深度学习;文本图像识别;兽医卫生证书;知识蒸馏
Research on OCR and Its Application in Customs Control
MENG Qing-Duo 1 QIN Li 1 ZONG Chao-Fei 2
Abstract This paper investigates deep learning-based text image recognition technology and its current applications in related industries, constructing a veterinary health certificate recognition model. By introducing a series of algorithmic improvements, including multi-dimensional quality assessment and anomaly recognition, morphological search template matching, and knowledge distillation model optimization, the issues of timeliness and accuracy in large-scale certificate recognition processing have been effectively addressed. This aids customs authorities in achieving automated certificate review, thereby enhancing clearance efficiency and management levels.
Keywords deep learning; text image recognition; veterinary health certificate; knowledge distillation
光学字符识别(Optical Character Recogni- tion,OCR)作为计算机视觉领域的一个重要研究方向,是一种将图像中的文字转换为可供计算机进一步处理的电子文本的技术。该技术可对图像中的像素进行特征提取与分析,并在此基础上使用字符识别方法获取其中的文字及信息。目前,OCR技术已在银行票据、车牌、证件等背景单一、文本整齐清晰的场景中得到广泛应用。
本文围绕海关业务,以兽医卫生证书为研究样本,通过研究基于深度学习的文本图像识别关键技术,自动提取兽医卫生证书中的关键文本信息并形成结构化数据,实现用“机器眼”代替人眼,为海关安全准入风险防控业务提供技术支撑。
1 光学字符识别技术概述
1.1 光学字符识别的发展
光学字符识别的概念最早于1929年由德国科学家Tausheck提出[1],随后美国科学家Handel也提出了文字识别的想法,但由于条件限制,这项技术并未被实现。20世纪50年代,随着计算机技术的发展,OCR开始进入实践阶段。早期研究集中于拉丁字母和数字的识别,例如,IBM等科技公司在20世纪50年代开始涉足OCR技术的研发,并推出了用于银行和金融行业的OCR系统,用来处理支票和票据。随着模式识别理论的发展,OCR技术开始向复杂文字体系延伸。IBM公司的工程师Casey和Nagy在1966年发表的首篇汉字识别相关的文章中[2],采用模板匹配方式实现了1000个印刷体汉字的识别。到20世纪90年代,LeNet5网络的提出在字符识别任务中取得了突破性进展,为后续深度学习在OCR领域的应用提供了重要参考。此后,随着深度学习的发展及识别网络和物体检测框架的不断优化,光学字符识别得到了长足发展,产生了一系列专用的文字检测及识别技术[3]。
1.2 光学字符识别技术
OCR技术的发展可以分为两个阶段:传统OCR技术和基于深度学习的OCR技术。
1.2.1 传统OCR技术
传统OCR技术通过将文本行的字符识别视为一个多标签任务学习过程,借助图像处理技术和相关的统计机器学习算法实现对图片文本内容的提取[4]。识别过程主要包括图像输入、图像预处理、版面分析、字符切割、字符识别等步骤。传统OCR技术对文字识别的准确率高度依赖图像的质量及文字的字体和布局,且识别过程未考虑上下文的语义关联信息,再加上其较多的处理流程及人工设计,使得该技术在处理较为复杂的文本图像时(如畸变或模糊不清),很难达到理想的识别效果。
1.2.2 基于深度学习的OCR技术
基于深度学习的OCR技术将文本图像识别分为文本检测和文本识别[5]两个主要步骤。其中,文本检测步骤主要用于定位文本的位置,文本识别步骤主要用于识别文本的具体内容。
(1)文本检测方法。基于深度学习的文本检测方法主要包括基于回归的方法和基于分割的方法[6]。基于回归的方法是在目标检测的方法上演变而来,首先预生成若干锚框,然后回归坐标和分类,最后经过非极大值抑制得到最终的检测结果,常见的算法主要有CTPN(Connectionist Text Proposal Network)、EAST(Efficient and Accuracy Scene Text)[7]等。基于分割的方法是将图像中的文字区域与背景区域进行分割,提取其中大的文字区域并进行检测。该类算法对于不规则形状的文本具有较好的检测效果。常见的算法主要有PSENet(Shape Robust Text Detection with Progressive Scale Expansion Network)、DBNet(Real-time Scene Text Detection with Differentiable Binarization)[8]等。
(2)文字识别方法。文字识别是对定位好的文字区域进行识别,主要解决的是将一串文字图片转录为对应字符的问题[9]。常用的方法主要有用于规则文字识别的基于CTC(Connectionist Temporal Classification)的方法、用于不规则文本识别的基于校正的方法和基于注意力(Attention)的方法。
2 模型构建
2.1 技术路线
兽医卫生证书以PDF格式存储,且可能存在图像表格比例失衡、图像倾斜过大、表格残缺不全等问题。本研究结合不同图像处理算法,同时参照PP-OCR框架对证书关键信息进行提取识别,具体技术路线如图1所示。
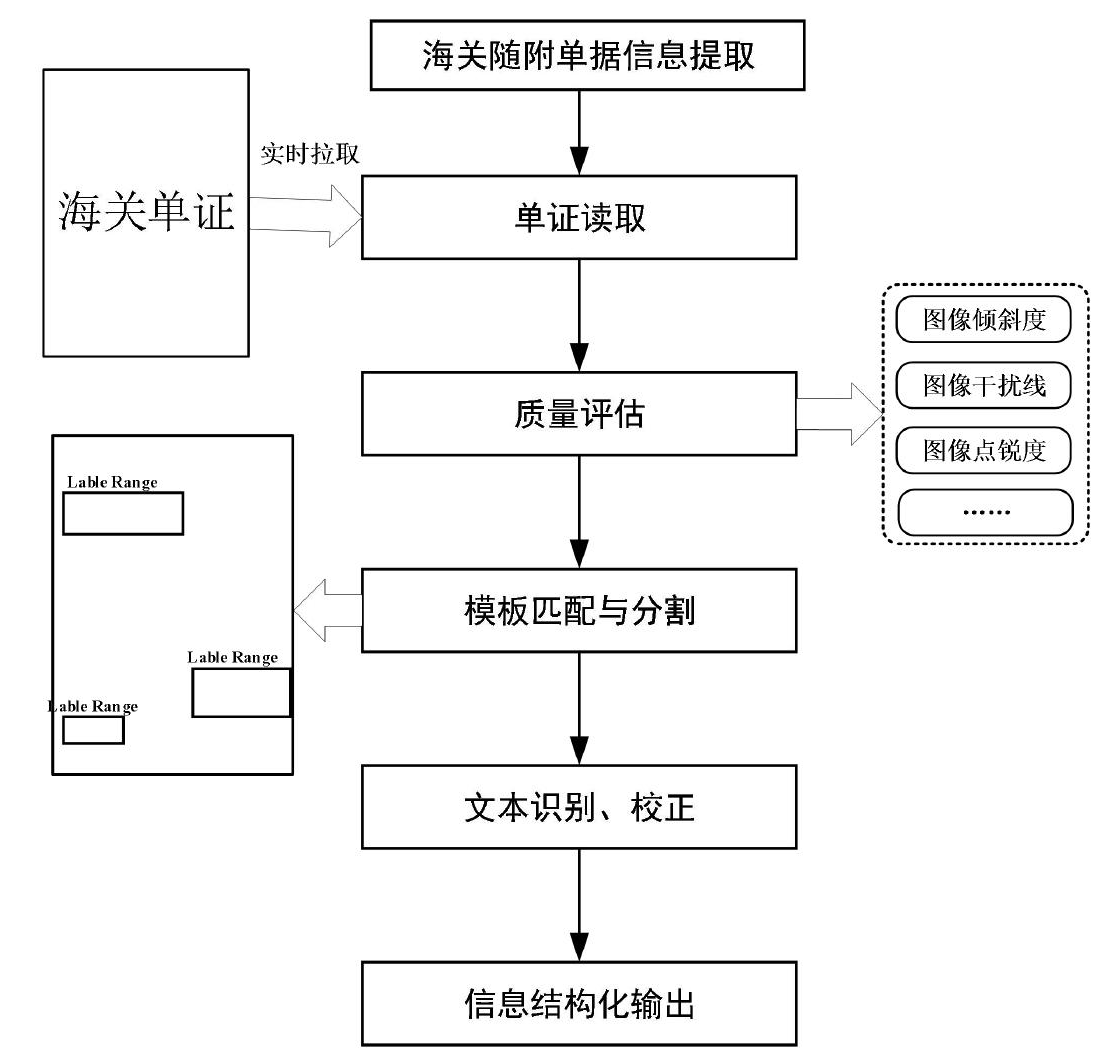
图1 兽医证书信息提取技术路线
Fig.1 Technical route for veterinary certificate information extraction
2.2 算法优化措施
2.2.1 基于结构化单证多维度质量评测与异常识别算法
本研究旨在提出一种全面考虑多个方面的单据质量评测与异常识别方法。该方法侧重评估图像的锐度、倾斜形变和干扰污染,这些因素对图像边缘清晰度、信息提取准确性和自动化系统性能至关重要。综合考虑这些关键因素,可以建立一个综合的单据质量评估模型,以自动判定单据图像的质量,并识别异常单据。该多维度评测方法,通过综合考量图像的关键维度,系统能够自动拒绝低质量图像,同时针对质量问题向用户提供精准反馈,从而提高提取结果的可靠性和准确性。
2.2.2 基于形态学搜索模板匹配算法
传统OCR文字识别方法对整张图像进行识别,耗时较长且包含大量无效信息,无法满足海关通关实时性需求。以兽医卫生证书为研究对象,本研究深入挖掘证书有效信息,发现其具有固定的模板。为提高OCR文字识别效率和准确性,本研究提出了一种基于形态学搜索的模板匹配方法,如图2所示。该方法首先通过轮廓检测定位有效信息区域,并利用自定义形态特征分布算子进行通道划分和特征匹配。通过基于岭回归的线拟合策略标记轮廓线,然后以类似方法搜索感兴趣区域的必要线分布并进行线校验。实现了感兴趣区域的精确分割,并将其送入后续OCR模块进行识别检测。
2.2.3 基于知识蒸馏的模型优化
文字识别是本系统的核心模块。由于在海关风险防控业务中涉及大并发量单据处理的场景,这要求模型具有快的推理速度以满足时效性。SVTR(Scene Text Recognition with a Single Visual Model)模型在精度具有竞争力的前提下,模型参数量更少,具有更快的推理速度,能够满足海关业务繁忙时高并发、数据量大的单据文字识别性能需求。
为应对海关场景高时效性、数据量大的特点,在实际训练和推理时,结合用于特征提取的MobileNetV1-Enhanced,它是一个多层的轻量级深度卷积网络,能够让网络在计算力较低的移动端运行并且保证网络的性能不会下降太多,可分离卷积代替传统卷积,大大减少模型参数,并提高了模型推理速度。
GTC(Global-to-local Transformer with CTC)是一种结合了Attention和CTC两种在文字识别中主流的方法。在训练时将两种方法结合起来对多种特征进行融合,能够获得更加准确、高效的模型。Attention只在训练时使用,而在推理时不会用到,因此也不会增加更多时间成本。其训练过程如图3所示。
将在大规模公开数据集上预训练的SVTR模型直接用于海关非结构化随附单据的文字识别,准确率很低,不能满足M2M间的高可靠、高置信度的需求。因此,考虑在预训练模型的基础上使用参数微调的方法对模型进行改进。相比于直接进行调优,使用知识蒸馏对模型的冗余参数压缩,能够改善模型复杂度。
在数据量足够大的情况下,通过合理构建网络模型的方式增加其参数量,可以显著改善模型性能,但是这又带来了模型复杂度急剧提升的问题。由于海关场景中需要面对大规模单据实时处理的情况,对模型的性能和处理时间都提出了较高的要求,大模型在实际场景中使用的成本较高,会耗费过多的软硬件资源。深度神经网络一般有较多的参数冗余,本文使用知识蒸馏方法对模型进行压缩,减小其参数量。知识蒸馏是指使用“教师模型”(Teacher Model)去指导“学生模型”(Student Model)学习特定任务,保证小模型在参数量不变的情况下,得到比较大的性能提升。在知识蒸馏任务中,衍生出了互学习的模型训练方法,使用两个完全相同的模型在训练的过程中互相监督,可以达到比单个模型训练更好的效果。蒸馏训练策略如图4所示。
文本识别问题可以看作是一个多分类问题,训练时字典中的字符个数可以看作分类数
,对于样本, = 1,2,...,n,其对应的标签为,i = 1,2,...,n。对于样本来说,每个种类m的概率为:
(1)
式(1)中,zm 表示网络的Softmax层的输出,预测概率最高类即为输出的字符。一般的多分类问题的损失函数被定义为预测值和标签之间的交叉熵损失L。
(2)
其中I被定义为:
(3)
传统的监督训练过程为图像输入到网络中进行前向传输,计算通过损失函数衡量预测与标签的差距反向传播。知识蒸馏是一种用于模型压缩和知识传递的技术,它通过将一个复杂的“教师模型”的知识转移到一个较小的“学生模型”上,以在计算资源有限的情况下保持较高的模型性能。知识蒸馏不仅可以用于模型压缩和加速训练,还可以用于提升模型的泛化能力和学习能力。通过知识蒸馏,可以利用“教师模型”的知识来辅助“学生模型”在小样本数据上进行训练,从而提高模型的泛化能力。
然而,两个相同的模型相互蒸馏则是在小样本情况下的一种新的探索和尝试。在这种方法中,两个模型(通常是相同结构的模型)同时充当“教师模型”和“学生模型”的角色,彼此交换知识,共同学习和提升。两个相同的模型共同训练和相互提炼来提高深度神经网络的性能,可以获得紧凑的网络,其性能优于传统知识蒸馏方法从强大网络中提炼出来的网络。
假设两个模型为和,它们的预测分别为和,利用KL散度(Kullback-Leibler Divergence)来衡量两个模型之间的分布差异,称为蒸馏互损失LDML(Distillation Mutual Loss),形式如下:
(4)
训练过程中,采用了CTC Loss和Attention Loss。通过引入一个特殊的空白标签来表示没有发生变化的时间步,并利用动态规划算法来寻找最可能的标签序列,CTC允许模型自动对齐输入和输出序列,无需人工标注。这种方法有效地提高了模型在处理序列预测任务时的性能和准确性。CTC模块在SVTR网络的FC层后计算CTC Loss,其输出为。Attention Module的引导,使模型从更强大的注意力中学习更好的对齐和特征表征,使模型可以保持稳健而准确的预测,同时保持较快的推理速度,其输出为,该模块的损失基于交叉熵函数计算的AL(Attention Loss)。此外,还有一个特征蒸馏损失(Feature Distillation Loss,FDL)需要被计算,它是用来优化特征提取模块的参数,以增强特征提取性能。通过计算输出和输入的均方误差来获得FDL的结果。
假设存在模型和,将它们的损失函数基于上面的内容进行改进,模型的自身损失为:
(5)
蒸馏互损失函数为:
(6)
式(2)中与分别表示在蒸馏时CTC蒸馏互损失与注意力蒸馏互损失的权重系数。
联合损失为:
(7)
类似的,模型的自身损失为:
(8)
蒸馏互损失函数为:
(9)
联合损失为:
(10)
这样,每个网络既能学会正确预测训练实例的真实标签也能匹配其同伴的概率估计。在训练时每个batch的迭代都会相互学习,根据联合损失函数更新模型参数。
2.2.4 知识超图的字段校正校验
为提升字段识别准确率和置信度,利用海关业务专家提供的资料构建校正校验规则对OCR识别结果进行后处理。知识图谱(Knowledge Graph,KG)可以表征实体之间结构化的关系,面对繁多的规则,针对每个字段基于知识图谱构建知识超图的字段校正校验规则集合。知识图谱被定义为有向图,其中,为节点的集合,代表海关随附单据待提取内容的实体标签,为边的集合,代表实体之间的关系。
当要对某个字段(Field)信息进行校正时,从改字段标签对应的查询节点出发,遍历节点之后图中的路径,找到与查询节点相关联的其他属性节点。遍历路径可以表示为一个路径集合,其中每个路径是一个节点序列,并且满足。在对每个字段进行校正校验时,需要遍历每个属性节点,每个节点对应校正规则或校验规则,因此对于每个路径,每个路径都有相同的权重,路径权重集合表示为。
知识超图根据每个字段的标签,获取对应的校正校验规则,例如使用编码规则对证书号码的置信度进行校验。通过上述方法,单据中的多个字段可以快速匹配到与其对应的规则,实现高效的字段校正和校验,大幅提高提取字段的准确率。
3 模型训练与效果
3.1 数据集准备与标注
本研究中使用了462张兽医卫生证书扫描件对提出的方案进行训练和测试。这些文件中需要提取的关键信息由人工标注。由于标注时依靠海关业务部门提供的先验知识参考和校对,其标注的可靠性能够得到保证。
3.2 模型训练
配置训练参数,训练参数见表1。文字识别的骨干网络为Mobile Net-V1 Enhanced,优化器为Adam。
表1 参数设置表
Table 1 Parameter setting table
参数名称 | 参数值 |
Epoch_num | 100 |
Batch_size | 12 |
Learning_rate | 0.0005 |
Algorithm | SVTR |
Backbone | MobileNetV1Enhanced |
Neck | SVTR |
Head | CTC |
3.3 实验结果
NRTR模型、基准模型SVTR模型以及蒸馏优化后模型MLKD-SVTR的对比实验结果见表2。
从表2中可以看到,MLKD-SVTR在性能上显著优于NRTR和SVTR,其字段错误率仅为28.34%,远低于NRTR和SVTR,同时推理速度最快,比SVTR和NRTR更高效。这一改进得益于知识蒸馏等技术,在保持轻量化的同时大幅提升识别精度和推理速度,更适合实际部署需求。
4 结语
本文模型中使用的算法改进措施显著提高了OCR技术识别的准确率和处理效率,特别是对于兽医卫生证书,通过优化的模型和算法,可以实现高效、准确的证书信息提取。这不仅满足了海关风险防控业务对实时性和准确性的高要求,也为海关的智能化监管和服务水平的提升提供了技术支撑。未来,模型的进一步优化和推广应用,将有助于通关效率的提升和海关业务流程的不断优化。
参考文献
[1] 朱成. 数字化转型对企业行政工作的影响[J]. 东方企业文化, 2023(S2): 44-46.
[2] 张静娴, 冷青轩, 陈航, 等. 基于图像滤波预处理的卷积神经网络汉字识别[J]. 电工技术, 2023(24): 69-73.
[3] 张策. 乌金体藏文古籍文档图像字符切分研究[D]. 兰州: 西北民族大学, 2023.
[4] 徐英卓, 王昊阳. 基于OCR的国家职业资格证书信息提取研究与应用[J]. 信息技术与信息化, 2024(5): 10-14.
[5] 邹卓峰, 张宝权, 李辉, 等. 基于图像识别技术的固井质量评价方法研究[J]. 钻探工程, 2024, 51(S1): 104-111.
[6] 蒋仕新, 邹小雪, 杨建喜, 等. 复杂背景下基于改进YOLO v8s的混凝土桥梁裂缝检测方法[J]. 交通运输工程学报, 2024, 24(6): 135-147.
[7] 张婷琳, 陈祥本, 丁晔, 等. 基于OCR技术的档案智能化收集方法研究[J]. 无线互联科技, 2024, 21(19): 32-36.
[8] 杨华, 汪俊雄, 沈浩, 等. 基于Attention-DBNet算法的文本检测方法[J]. 中南民族大学学报(自然科学版), 2024, 43(5): 674-682.
[9] 李有春, 汤春俊, 梁加凯, 等. 无人机输电线路巡检照片号牌文字识别方法[J]. 无线电工程, 2024, 54(6): 1560-1568.
第一作者:孟庆铎(1983—),男,汉族,吉林通化人,硕士,高级工程师,主要从事海关信息化系统开发工作,E-mail: 179797156@qq.com
1. 全国海关信息中心(全国海关电子通关中心) 北京 100005
2. 北京中海通科技有限公司 北京 100023
1. National Information Center of GACC (General Administration of Customs of China), Beijing 100005
2. China CUSLINK Co., Ltd., Beijing 100023
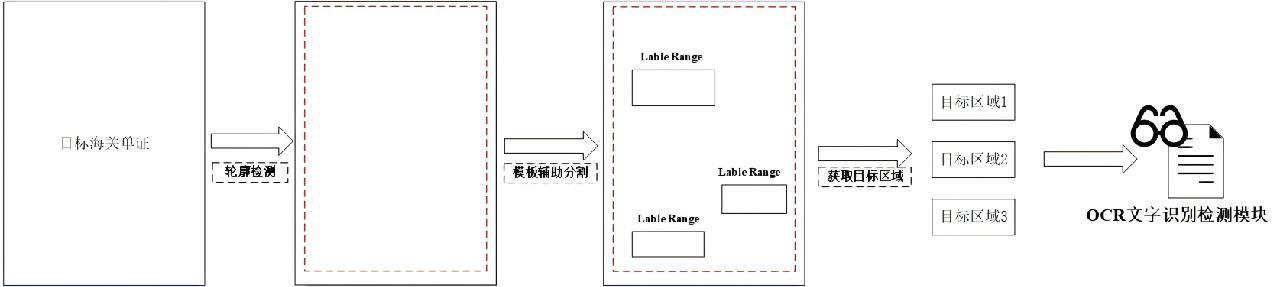
图2 基于形态学搜索模板匹配方法示意图
Fig.2 Schematic diagram of template matching method based on morphological search

图3 GTC训练策略
Fig.3 GTC training strategy
图4 蒸馏训练策略
Fig.4 Distillation training strategy
表2 不同模型的实验结果对比
Table 2 Comparison of experimental results of different models
模型 | 字段错误率 (%) | 推理时间 (s) |
NRTR | 85.07 | 8.42 |
SVTR | 86.67 | 1.51 |
MLKD-SVTR | 28.34 | 1.25 |
第7卷 增刊
2025年7月
网络安全 / Cyber Security
基于AI技术的海关网络内生情报生成
技术与应用研究
范絮妍 1 石 宇 1 * 陶君茹 1 相 森 1
摘 要 在海关数字化转型背景下,海关广域网面临复杂的网络攻击挑战,传统安全防护在信息协同、数据适配及技术检测层面还存在优化空间。本研究提出“三级协同智能防御体系”,通过口岸边缘探针、直属海关安全节点、海关总署智能安全区域的分层架构,构建基于海关网络内生情报的智能防御架构,涵盖边缘探针层实时流量检测与低级特征提取、直属节点层特征富化与初筛打标、总署核心层借助大语言模型和注意力机制聚合全局情报并生成标准化防御策略,实现高效全网同步,为智慧海关建设提供高实时性、低资源消耗的安全解决方案。
关键词 海关广域网;情报;智能防御架构;大语言模型;注意力机制
Research on AI-Based Endogenous Intelligence Generation Technology and Its Application
in Customs Networks
FAN Xu- Y an 1 SHI Yu 1* TAO Jun- R u 1 XIANG Sen 1
Abstract In the context of customs digital transformation, the customs wide-area network (WAN) faces challenges from complex cyberattacks, with traditional security protection showing insufficient adaptability in information collaboration, data adaptation, and technical detection. This paper proposes a “three-tier collaborative intelligent defense system”. Through a hierarchical architecture consisting of port perimeter probes, regional customs security nodes, and customs general administration intelligent security zones, an intelligent defense framework based on endogenous intelligence is constructed. This framework covers real-time traffic detection and low-level feature extraction at the edge probe layer, feature enrichment and preliminary screening/tagging at the regional sub-node layer, and the aggregation of global intelligence and generation of standardized defense strategies at the general administration core layer via large language models and attention mechanisms, achieving efficient network-wide synchronization. It provides a highly real-time and low-resource-consumption security solution for Smart Customs construction.
Keywords customs wide-area network (WAN); intelligence; intelligent defense architecture; large language model; attention mechanism
第一作者:范絮妍(1982—),女,汉族,河北保定人,硕士,高级工程师,主要从事网络安全和数据安全相关工作,E-mail: 31958712@qq.com
通信作者:石宇(1978—),男,汉族,北京人,硕士,高级工程师,主要从事网络安全、保密安全工作,E-mail: shiyuw@sohu.com
1. 全国海关信息中心(全国海关电子通关中心) 北京 100005
1. National Information Center of GACC (General Administration of Customs of China), Beijing 100005
在数字化时代,威胁情报作为防范网络攻击、先发制敌的重要信息,已成为网络安全防御体系的核心要素。随着智慧海关建设中人工智能、大数据、云平台等新技术的广泛应用,海关网络面临日益复杂的网络攻击挑战。全国海关以“核心节点+直属节点”的星型广域网架构,支撑着日均4 TB跨节点数据处理的复杂业务系统,但渗透测试显示,海关网络安全防护在协同防御、数据治理与技术应用层面还存在可优化空间,主要涉及网络防御基础与情报共享优化、情报生成的数据质量优化、情报生成的技术手段提升等方面。
本文提出“三级协同智能防御体系”,通过口岸边缘探针、直属海关安全节点、海关总署智能安全中枢的分层架构,构建全网协同机制以破解情报共享壁垒,建立内生情报生成机制以优化数据质量,融合大语言模型强化复杂威胁检测能力,形成“采集-研判-聚合”闭环,提升跨广域网威胁检测与响应效率,满足海关网络安全的特定防护需求。
1 威胁情报相关研究现状
近年来,威胁情报研究在理论框架与技术应用上持续深化,但其在复杂行业场景中的适配性仍面临挑战。
1.1 现有研究要点与理论进展
1.1.1 概念体系与分层架构
威胁情报的核心内涵围绕证据化知识生产展开,Gartner提出的决策支持型定义[1]与信息论视角下的价值转化模型[2],共同构建了其理论基石。分类体系则形成“战略-运营-战术-技术”的四级框架[3],其中技术情报(如攻击IP、文件哈希等失陷指标)直接服务于实时检测,而战略情报为宏观安全决策提供支撑。这种层次化架构为情报的差异化管理提供了方法论,但在行业垂直场景中仍需针对性适配。
1.1.2 数据生态与标准化建设
数据源覆盖开源社区、商业平台与组织内部日志,其异构性推动了国内外标准的发展。例如,我国的GB/T 36643—2018《信息安全技术 网络安全威胁信息格式规范》,以及国外的结构化威胁信息表达式(Structured Threat Information Expression,STIX)与情报信息的可信自动化交换(Automated Exchange of Trusted Information,TAXII)[4]。这些标准基于信息共享理论,解决了跨系统的数据互操作问题,但对行业特殊数据的语义解析仍存在空白,导致标准化成果难以深度融入业务场景。
1.1.3 技术演进与分析范式
传统规则引擎与机器学习方法在已知威胁检测中表现稳定,但面对高级持续性威胁时,仍会因为依赖人工特征工程而暴露泛化能力不足的缺陷。深度学习技术如循环神经网络(Recurrent Neural Network,RNN)及其变体长短期记忆神经网络(Long Short-Term Memory Neural Network,LSTM)、卷积神经网络(Convolutional Neural Network,CNN))通过自动化特征提取提升了非结构化数据处理能力,而大语言模型,如基于Transformer的双向编码器表征(Bidirectional Encoder Representations from Transformers,BERT)与生成式预训练Transformer-4(Generative Pretrained Transformer 4,GPT-4)的涌现,更是在威胁报告生成、多语言情报融合等任务中展现出上下文理解优势[5-7]。然而,现有技术多聚焦通用网络环境,对海关星型广域网中业务系统深度交互等特殊场景的适配性研究仍显匮乏。
1.1.4 应用理论与框架
威胁情报的应用体系融合了应急响应理论、态势感知理论与信息可视化理论,形成从检测预警到决策响应的闭环。但在海关等具有强业务依赖性的领域,现有框架尚未解决业务逻辑与安全规则的深度耦合问题。
1.2 现有研究局限与行业痛点
尽管通用技术体系日臻完善,但行业垂直场景的特异性挑战却逐渐凸显。
(1)数据供给与需求错配:现有研究多依赖外部情报源,对内生威胁数据(如内部流量异常、业务系统操作日志)的挖掘机制缺失。以海关为例,外部情报难以精准映射其内网中“直属节点间信任链滥用”“跨节点数据摆渡”等有的风险场景,导致情报落地时出现“场景语义断层”。
(2)模型能力与复杂场景脱节:主流分析模型(如小规模机器学习模型)在处理海关广域网日均4 TB跨节点流量时,因上下文关联能力不足,难以捕捉跨关区攻击的长周期隐蔽特征。而大语言模型的行业适配研究仍处于起步阶段,其在海关业务术语理解、攻击路径推演等任务中的实用性尚未得到验证。
(3)协同机制与架构特性不兼容:STIX/TAXII等标准虽解决了格式统一问题,但未针对海关星型架构的“核心节点-直属节点”层级特征设计差异化共享策略。实际运行中,直属节点间情报共享存在“核心节点负载过高”与“隶属海关数据上报滞后”的双重矛盾,导致全局威胁响应效率低下。
1.3 本研究的价值与创新路径
针对上述局限,本文聚焦海关网络安全的场景特异性需求,探索构建“数据-模型-协同”三级优化体系,具体而言:(1)内生数据增强:设计基于业务日志与流量特征的内生情报生成机制,解决外部情报“场景不匹配”问题;(2)分层智能研判:引入轻量化大语言模型与联邦学习框架,在海关总署核心节点实现跨直属节点攻击链的深度关联分析;(3)分级协同架构:依据海关组织架构,构建“口岸边缘探针-直属海关安全节点-总署智能安全中枢”的三级情报流转机制,平衡数据处理效率与全局安全态势感知能力。
通过上述创新,本文旨在为海关网络安全提供“架构适配型”解决方案,更期望为垂直行业威胁情报研究提供“业务-安全深度融合”的方法论参考。
2 基于内生情报的智能防御架构设计
基于海关网络安全防护体系,以及海关星型广域网“核心节点+直属节点”的集权特性及垂直管理需求,本研究采用以总署核心节点为中心的分层协同智能防御架构,兼顾技术可行性与安全效能。
该架构设计充分考量海关网络中心化通信本质,避免去中心化模式下全连接链路爆炸与策略碎片化问题,通过总署核心节点整合所有直属节点资产、信任链及攻击数据,构建覆盖跨直属节点跳板攻击的统一威胁模型。同时,依托核心节点集中承载大模型算力,直属节点执行区域特征提取和初筛任务无需重复部署大模型,边缘探针仅执行轻量检测,较去中心化架构降低90%边缘资源消耗。
在此框架下,防御体系由口岸边缘探针、直属海关安全节点、总署智能安全中枢三级构成:边缘探针实时采集网络流量与系统日志,提取轻量级威胁特征;直属节点完成区域级特征富化与初筛打标;总署中枢通过大模型聚合全局情报并生成标准化策略,经星型网络实现全网同步。三级架构层层递进、协同联动,形成“检测-研判-响应”闭环,架构设计图如图1所示。
口岸边缘探针处于整个架构的最底层,是网络安全监测的“哨所”。它们分布在直属海关和隶属海关网络的各个边缘位置和关键网络节点,实时监测网络流量的每一个细微变化以及主机节点的每个系统运行动作。其主要功能是对网络流量和系统日志等数据源进行实时检测,一旦发现潜在威胁,如异常的流量波动、可疑的连接请求等,便立即收集相关的原始告警信息,并抽取出轻量级告警向量。这些信息包含了网络活动的基本数据,是后续威胁分析的重要依据。
直属海关安全节点位于架构的中间层级,起着承上启下的作用。它接收来自口岸边缘探针上报的原始告警信息,并对这些信息进行深入的处理和分析。一方面,直属海关安全节点运用先进的特征提取技术,从原始告警信息中挖掘出关键的特征信息,如源IP地址的熵值、流量脉冲的时间间隔、协议分布情况,以及攻击类型、置信度、攻击范围等高级特征。通过对这些特征的综合分析,能够更全面、准确地描述告警所涉及的潜在威胁。另一方面,直属海关安全节点会根据预设的规则和模型,对告警进行初筛打标。对于置信度较高的告警,依据攻击类型从预设的标签集合中选取对应的标签进行标记;对于置信度较低的告警,则标记为“未知威胁”,以便后续进一步分析。经过这样的处理,直属海关安全节点将原始告警信息转化为更具价值的打标告警数据,为总署核心层的深度分析提供了更有针对性的信息。
总署智能安全中枢作为架构的最高层级,承担着对全局情报进行综合分析和决策的重任。它汇聚了来自各个直属海关安全节点的打标告警数据,并利用强大的大模型进行深度聚合分析。首先,总署核心层将各直属节点的告警特征向量进行拼接,形成一个综合的特征向量,为后续的深度分析提供全面的数据基础。接着,将综合特征向量输入到大型语言模型(Large language model,LLM)中进行推理,挖掘其中隐藏的关联和模式,生成更高级别的特征表示。然后,利用注意力机制(Attention)对大模型的输出结果和外部威胁情报进行加权融合,得到最终的全局情报,如攻击类型、攻击阶段、目标资产、影响范围、攻击者画像等。同时,总署智能安全中枢还将分析结果转化为多维度的标准化威胁指标,并根据这些指标生成相应的防御策略。这些防御策略通过高效的通信机制,迅速同步到全网各个节点,实现对海关网络安全的统一指挥和协调防御[8-10]。
通过这种三级协同的架构设计,口岸边缘探针负责实时采集原始数据,直属海关安全节点进行初步分析和筛选,总署智能安全中枢进行深度聚合和决策,各层级各司其职、协同合作,形成了一个高效的情报生成、研判和协同防御机制,为海关网络安全提供坚实的保障。
3 三级情报生成机制
3.1 边缘探针层
3.1.1 功能定位
边缘探针层在整个情报生成体系中扮演着基础数据采集和初步处理的关键角色。它从网络流量、系统日志等多种数据源实时采集原始告警信息,这些数据源如同网络安全的“感知触角”,全面捕捉网络运行过程中的各类异常情况。同时,边缘探针层还承担着低级特征提取的任务,通过提取基础特征,为后续的初步过滤和分析提供支持。
3.1.2 特征提取
边缘探针层提取的低级特征向量F由多个关键要素构成,包括攻击时间、源IP、目的IP、端口、协议、攻击类型、告警级别、告警设备类型、告警设备IP等。
3.1.3 输出
边缘探针层的输出是包含低级特征F的原始告警数据。这些数据虽然经过了初步的特征提取,但仍然保留了大量的原始信息,为后续直属节点的进一步处理提供了丰富的素材。
3.2 直属节点层
3.2.1 功能定位
直属节点层处于情报生成的中间层级,一方面,它在边缘探针提取的低级特征基础上进一步补充高级特征,使对告警的描述更加全面和深入;另一方面,它对告警进行初步分类和打标,为总署核心层的深度分析和决策提供更具针对性的信息。
3.2.2 特征富化
直属节点层提取的高级特征向量Vi涵盖了多个维度,向量Vi并非仅描述源IP和目的IP对的二元关系,而是从“行为模式、时空分布、协议特征、攻击意图”等多个维度富化情报,为大模型提供多维上下文。以下为向量Vi的关键特征:
(1)源IP熵值是通过计算源IP地址在时间窗口内的分布随机性(熵值),量化其异常性。例如:熵值>2.0表示IP频繁变动(可能为代理或僵尸网络),正常业务IP熵值通常<1.5。模型输入价值:帮助大模型区分正常用户与攻击者,识别分布式扫描或跳板攻击(如IP轮换策略)。
(2)目的IP段标识目标资产所属网段(如数据库服务器网段),攻击范围描述受影响的直属节点数量。例如:“目的IP段=100.*.1.0/24,100.*.2.0/24,100.*.3.0/24”,且“攻击范围= 3个直属节点”,横向移动意图。 模型输入价值:指导大模型聚焦关键资产,关联跨直属接单攻击链(如从直属节点A经核心节点跨域跳转到直属节点B/C的渗透路径)。
(3)协议特征包括协议类型、加密参数异常(如传输层安全协议(Transport Layer Security,TLS)扩展字段异常);流量统计涵盖流量脉冲、连接频率等。例如:“协议特征=异常TLS扩展”+“流量统计>5σ”,表明加密通信伪装与突发攻击。模型输入价值:识别协议层漏洞利用行为(如CVE-2023-12345对应的远程桌面(Remote Desktop Protocl,RDP)漏洞),区分分布式拒绝服务(Distributed Denial of Service,DDoS)攻击与业务高峰。
(4)地理位置解析源IP归属地,时间特征分析攻击行为的时间规律(如高频短时连接)。 例如:“地理位置= CountryX(非白名单地区)”+“时间特征= UTC非工作时间”,增强攻击意图判断。模型输入价值:结合地缘政治情报提升攻击者画像的准确性。
(5)攻击上下文关联历史日志与拓扑信息(如目标资产业务重要性),置信度综合模型预测与规则匹配结果。 例如:“攻击上下文=数据库服务器+10 min内跨3个直属节点访问”,置信度= 0.94(高可信)。模型输入价值:为大模型提供语义化标签(如“横向移动-执行阶段”),支撑标准化威胁指标生成。
Vi向量的设计突破传统以IP对为核心的单一维度分析,通过行为特征量化(熵值、流量统计)、语义标签富化(攻击类型、上下文)、时空关联(地理位置、时间戳)等多维度信息,为大模型提供“可计算、可关联、可解释”的输入。Vi向量通过“时空-行为-语义”的多维特征拼接,使大模型既能够动态构建攻击链,又能量化威胁等级,基于“置信度”和“业务影响评分”,优先处置高风险事件。
3.2.3 初筛打标
直属节点层根据预设的打标规则对告警进行初步分类和标记。当告警的置信度大于某一参考值时,认为对攻击类型的判断较为可靠,根据攻击类型从预设的标签集合中选取对应的标签进行标记;若置信度小于等于参考值时,则将其标记为“未知威胁”,以便后续进一步分析和处理。
3.2.4 输出
直属节点层的输出是包含高级特征向量Vi的打标告警数据。这些数据经过了特征富化和初筛打标处理,相比边缘探针层的原始告警数据更简洁、明确,且包含了更多有价值的信息。
3.3 总署核心层
3.3.1 功能定位
总署核心层作为情报生成的最高层级,基于各直属节点上报的告警特征向量,利用强大的大模型进行深度聚合分析,生成全面、准确的全局情报。同时,将分析结果转化为多维度的标准化威胁指标,并生成相应的防御策略,实现对海关网络安全的统一指挥和协调防御。
3.3.2 大模型情报统合算法
(1)特征拼接。总署核心层首先将直属节点上报的告警特征向量Vi按时间窗口(如5 min)排序并拼接为全局特征矩阵V,公式为:V=V1⊕V2⊕⋯⊕V44。其中,每个向量Vi包含字段:[时间戳, 攻击类型, 协议特征, 攻击范围, ...]。
(2)大模型推理。在基础模型方面,采用预训练的Transformer架构,如GPT-3.5,借助迁移学习技术,将通用语言模型适配到特定的威胁分析任务中,为后续分析奠定基础。在微调数据方面,以海关历史攻击日志、高级持续性威胁(Advanced Persistent Threat,APT )组织行为模式以及协议漏洞特征库作为微调数据,使模型在预训练的基础上进一步学习并掌握威胁分析领域的专业知识,从而提升模型在该领域的准确性与适应性。在嵌入层方面,将向量Vi中的数值与分类特征映射为高维向量,赋予数据元素更丰富的语义表达,使其能够更好地被模型理解与处理。在上下文编码方面,通过多头自注意力机制,深入挖掘跨直属节点向量Vi的潜在关联。在外部威胁情报(Cyber Threat Intelligence,CTI)注入方面,引入 MITRE ATT&CK 标签,如 T1210.001,作为提示词(Prompt),引导模型生成标准化战术标签。这种外部知识的注入,不仅丰富了模型的知识库,还使得模型的输出更具标准化与规范化,便于安全人员进行统一的分析与决策。在输出方面,模型最终生成中间特征表示H,其中包含攻击阶段、TTPs(战术、技术与过程)等语义化信息,这些信息以结构化的形式呈现,为后续的威胁评估与响应提供了关键依据,可表示为:H = LLM(V)。
(3)Attention加权。在情报分析中,为了充分发挥CTI与模型推理结果的优势,实现对高相关性威胁情报的精准聚焦,采用注意力加权融合方法。其核心在于通过合理计算权重,将不同来源的信息进行有效整合,提升威胁情报的质量与可用性。
通过计算每个向量Vi与外部CTI之间的关联程度,来衡量它们的相似度。基于相似度评分,为每个向量Vi分配注意力权重。通过这种方式,与外部CTI关联度越高的向量Vi,其对应的注意力权重越大。得到最终的全局威胁情报Tglobal,公式为:Tglobal = Attention(H,CTI)。其中,Attention机制通过计算不同特征向量和外部威胁情报的权重来突出关键信息。
3.3.3 标准化威胁指标
总署核心层输出的标准化威胁指标是一个包含丰富信息的多维度数据结构,包括攻击类型、攻击阶段、目标资产、影响范围、业务影响评分、攻击者画像、攻击工具、攻击意图、置信度、可信度来源、响应策略建议等。例如,攻击类型明确是DDoS攻击、SQL注入攻击等;攻击阶段指出是探测阶段、攻击执行阶段等;目标资产确定是数据库服务器、网络设备等;影响范围说明是子网、整个网络节点等;业务影响评分通过量化分数评估对业务的影响程度;攻击者画像包含地理位置、所属组织等信息;攻击工具列出如Mimikatz、PsExec等;攻击意图明确是数据窃取、系统破坏等;置信度表示对威胁判断的可靠程度;可信度来源说明是模型预测、历史数据对比等;响应策略建议给出阻断源IP、隔离受影响资产等操作建议。
3.3.4 输出
总署核心层的输出包括全局情报和防御策略。全局情报是包含多维标准化威胁指标的综合信息,全面、准确地描述了网络面临的威胁情况,为海关网络安全决策提供了重要依据。防御策略则是根据威胁指标生成的具体操作指令,用于指导全网节点进行安全防御。
4 三级情报协同案例推演
4.1 事件检测
(1)边缘探针威胁探测。边缘探针层借助轻量化特征向量F,对网络流量进行实时监测。该向量F包含诸如攻击时间、源IP、目的IP、端口、协议、攻击类型、告警级别、告警设备类型及告警设备IP等9类关键特征。通过此向量,能够实时检测到异常RDP流量。相较于传统全流量采集需存储完整数据包的方式,向量 F 的数据量被显著压缩。
(2)直属节点富化威胁特征并打标。直属节点层负责对告警进行深度富化处理,生成高级特征向量Vi。以某次告警分析为例,对源 IP“192.*.*.45”进行分析,经计算其历史活跃度熵值预测为2.1(正常范围预计在0.5~1.5),由此可推断该IP疑似为可疑代理 IP;目的IP“10.*.*.7”属于数据库服务器专用网段,该网段通常不在RDP服务授权范围内;通过关联日志预测,发现该IP在10 min内尝试连接3个关区,符合横向移动特征;同时,RDP 协议流量中携带非常规加密参数(如TLS1.3未启用扩展字段)。
基于上述分析,通过初筛打标(置信度预计为0.91),将其标记为“APT横向移动-高置信”,并上传精简后的向量Vi。此方案预计可避免传输冗余数据,使得跨域通信带宽大幅减少。
4.2 情报聚合
总署核心层利用三级协同机制构建全局威胁动态画像。具体如下:
(1)多直属节点特征拼接。将直属节点的向量Vi依据时间戳进行排序,并拼接为综合特征V,随后输入大语言模型(LLM)进行推理。例如,直属节点A的Vi显示攻击类型为横向移动、目的IP段指向数据库服务器;直属节点B的Vi包含协议特征为异常 TLS 扩展、地理位置为CountryX。经LLM推理,可关联生成攻击链,即 APT GroupX 利用 RDP 漏洞横向渗透至数据库服务器。
(2)注意力加权融合。引入外部CTI,匹配关于APTGroupX的威胁情报标签,经计算直属节点A与B的注意力权重分别预计为0.67和0.63。
(3)生成标准化威胁指标。该指标涵盖攻击类型、攻击阶段、目标资产、影响范围、业务影响评分、攻击者概况、置信度、置信来源以及响应建议等内容。
(4)规则生成优化。依据向量Vi中的协议特征与目的IP段,预计生成精准防御规则,如“阻断CountryX至数据库网段(10.*.*.0/24)的RDP流量”。
4.3 全网响应
总署核心层通过三级协同通道达成秒级阻断的目标。具体过程为:(1)策略同步。基于向量Vi中的“攻击范围=跨3个直属节点”,仅向涉事节点(直属节点A/B/C)下发规则,同步时间预计为秒级。(2)攻击拦截。边缘探针依据向量 F 中的“协议= RDP”和“目的 IP = 10.*.*.7”进行精准拦截,预计阻断率可达 100%。综上所述,本研究提出的三级情报协同机制,在数据处理、威胁检测与响应等方面展现出优势,为提升网络安全防护水平提供有效的解决方案。
5 三级情报机制实施路线图
5.1 总署核心层构建全局智能中枢
部署高性能计算集群,满足直属节点5 min数据窗口处理时效≤10 s,构建统一威胁数据中台,集成历史攻击日志(留存≥3年)、资产基线库及国家级CTI接口。基于海关APT攻击链数据微调大模型,强化跨直属节点行为关联与TTPs解析能力,季度更新攻击特征库。定义威胁指标映射规范,将ATT&CK框架适配至海关业务场景(如T1078.003映射为“特权账户异常越权”),自动化生成防御指令(如阻断高熵值IP访问)。建立双向通信通道,上行数据压缩率≥80%,下行策略延迟≤30 s。
5.2 直属节点构建区域智能中枢
5.2.1 边缘探针接入与管理
部署轻量级探针管理平台,支持辖区内500+探针设备(如网络流量探针、主机日志探针)的集中配置(如攻击时间窗口阈值、端口监测范围)与状态监控(如实时显示探针在线率、数据采集延迟)。另外,制定边缘探针数据上报规范,要求原始告警数据包含9项低级特征(攻击时间、源IP/目的IP等),并通过HTTPS加密传输(TLS 1.3协议,证书每季度更新)。
5.2.2 特征富化与初筛能力构建
建议统一研发直属海关本地化特征计算模块。例如,源IP熵值计算:基于滑动窗口(1 h)实时计算IP地址变更频率,熵值>2.0触发“可疑IP轮换”标记;攻击范围识别:通过受害IP和攻击IP所在地址段,自动关联受影响直属节点数量,跨3个以上关区访问标记为“横向移动预警”。构建区域规则库,包含300 +初筛规则(如“非工作时间(22 :00—6:00)数据库端口连接数>100次,置信度0.85”),对告警信息进行置信度初筛,并可同步总署核心节点推送的动态更新规则。
5.2.3 资源配置
建议采用64核/256GB服务器集群,容器化部署保障弹性,存储30 d数据用于溯源,归档保存数据至少180 d备查。
5.3 实施保障
建议由海关总署发布威胁情报特征相关字典,统一字段定义与编码规则。可进行分阶段验证,例如,试点阶段(6个月):选取复杂度高、中、低不同关区典型代表3~5个,验证跨层协同的威胁情报生成效果;推广阶段(12个月):完成全国海关部署(探针覆盖率≥90%),威胁检测覆盖率提升至95%以上,形成“边缘-区域-全局”协同防御闭环。
6 结语
本研究围绕海关广域网安全问题,研究构建三级威胁情报协同机制,预期将有效提升攻击检测和溯源效率、降低分支节点资源消耗,保障海关业务的稳定运行,为智慧海关建设奠定坚实基础。未来,本研究将进一步研发海关专用情报大模型,使其能更好地处理海关复杂业务数据,更精准地识别威胁,提高情报分析的准确性和智能化水平。
参考文献
[1]张玲. 对主流网络威胁情报标准应用的比较研究[J]. 信息安全与通信保密, 2022(7): 25-32.
[2]何发镁, 刘润时, 贾赛男, 等. 网络威胁情报分析框架研究和实现[J]. 燕山大学学报, 2024, 48(4): 369-375.
[3]王旭仁,魏欣欣,王媛媛, 等. 网络威胁情报实体识别研究综述[J]. 信息安全学报, 2024, 9(6): 74-97.
[4]梁浩然. 车联网边端环境中的威胁感知与位置隐私保护技术研究[D]. 上海: 上海交通大学, 2021.
[5]蔡鑫鹏, 贾正望, 刘华军. 基于雷达测量的用于炮位侦察的Transformer网络[J]. 南京理工大学学报, 2021, 45(2): 189-196.
[6]朱玥. 大语言模型赋能网络威胁情报分析场景、风险和发展路径[J]. 情报杂志, 2024, 44(4): 1-6.
[7]池亚平, 吴冰, 徐子涵. 大语言模型在威胁情报生成方面的研究进展[J]. 信息安全研究, 2024, 10(11): 1028-1024.
[8]赖清楠, 金建栋, 周昌令. 基于大语言模型的网络威胁情报知识图谱构建技术研究[J]. 通信学报, 2024, 45(Z2): 33-42.
[9]宋恒嘉, 胡志锋, 郑轶等. 基于网络安全的威胁情报系统设计与实现[J]. 网络安全技术与应用, 2025, (2): 1-2.
[10]邹希, 殷悦, 张潮,等. 水利部网络威胁情报中心研究与应用[J]. 水利信息化, 2024, (6): 55-60.
图1 海关网络安全分层协同智能防御框架设计
Fig.1 Design of customs cybersecurity hierarchical collaborative intelligent defense framework
研究
第7卷 增刊
2025年7月
Cyber Security / 网络安全
基于微隔离技术的数据中心云网络安全研究
徐春利 1 刘 鲲 1 * 孟庆晨 1 刘 烨 1
摘 要 随着网络技术的快速发展,微隔离技术作为一种新兴的安全防护手段,受到了广泛关注。微隔离技术对于缩小攻击面、数据中心内部流量的可视化管理方面具有诸多优势。本文通过分析当下数据中心云网络中面临的安全风险,从工作原理、技术优势和实现路线几方面入手,研究基于流量行为分析网络内部精细化隔离技术,给出了基于微隔离技术的数据中心零信任方案,为海关网络安全防护架构更新提供借鉴与参考。
关键词 微隔离;零信任;数据中心;云安全
Research on Data Center Cloud Network Security Based on Micro-Segmentation Technology
XU Chun-Li 1 LIU Kun 1* MENG Qing-Chen 1 LIU Ye 1
Abstract With the rapid development of network technologies, micro-segmentation technology has garnered widespread attention as an emerging security protection method. This technology demonstrates significant advantages in reducing attack surfaces and enabling visual management of internal data center traffic. By analyzing current security risks in cloud-based data center networks, this paper investigates refined internal network isolation techniques based on traffic behavior analysis from perspectives of working principles, technical strengths, and implementation approaches. A zero-trust framework for data centers utilizing micro-segmentation is proposed, offering reference for updating security architectures in core local area networks of customs systems.
Keywords micro-segmentation; zero-trust; data center; cloud security
云化数据中心的基础架构正在经历重要变革,虚拟机、容器等工作负载随时可能进行克隆复制、扩缩容、漂移或消亡,云数据中心75%的网络流量[1]源自内部工作负载间的东西向连接,而东西向流量的管理缺失,使攻击者在网络内的横向移动和恶意代码的内部传播几乎无阻碍,正所谓“单点突破、整网暴露”[2],给云数据中心、业务应用和数据带来了严峻的安全风险,而微隔离技术可以有效地解决这一安全风险。
1 微隔离技术概述
隔离技术是早期基础且核心的安全手段之一。然而,随着虚拟化技术的广泛应用,传统隔离技术无法适应现代数据中心内部需要,在此背景下微隔离技术应运而生。
微隔离技术(Micro-Segmentation),亦称为逻辑分段或基于身份的分段,是一种网络安全策略,其核心理念是将安全控制从传统的边界保护扩展到数据中心的每个工作负载,实现独立的流量管理和访问控制[3]。相比传统的基于虚拟局域网(Virtual Local Area Network,VLAN)、子网或端口的隔离方法,微隔离通过属性标签动态生成策略,并支持实时适应,即使某一节点被攻破,攻击也无法在网络内部横向传播。这一技术特别适用于动态资源丰富的云环境,通过基于零信任架构的最小权限策略保护东西向流量安全。微隔离技术与传统网络控制手段的区别见表1。
2 微隔离技术的优势
2.1 提升网络安全防护能力
微隔离技术通过工作负载级别的分段和精细化控制,提升了云数据中心的安全防护水平,包括以下几个途径:(1)攻击面最小化[4],是指微隔离通过对每个工作负载进行独立的流量控制和限制,阻止攻击者在网络内快速扩散,即使攻击者攻破某一区域,也难以突破更严格受控的微分段边界;(2)对抗多阶段攻击,是指微隔离有效应对横向攻击,抑制数据劫持过程中横向侧移的行为,建立多层阻隔环境;(3)细粒度访问控制,是指与传统的基于VLAN的粗粒度隔离不同,微隔离支持基于身份、标签等多维属性的精细策略,使策略更具针对性。
2.2 动态适应云环境
云环境下的工作负载(如虚拟机、容器、Serverless)动态性强,传统的静态安全策略难以随之变化。微隔离技术通过动态生成和管理策略,实现对云环境的良好适应性,主要优势体现如下:(1)自动跟随迁移,即当工作负载在虚拟化环境中克隆、迁移或扩展时,微隔离的安全策略能够自适应地随迁生效;(2)支持动态计算场景[5],在面对快速变化的Serverless或容器化负载时,微隔离技术通过容器网络接口(Container Network Interface,CNI)插件,将策略直接绑定到Pod或资源标签,从而避免因动态实例生成无策略保护;(3)弹性扩展能力,在流量剧增或多个资源副本新增时,微隔离不会因为扩展而丧失策略一致性,在横向扩展的同时提供全过程安全保障。
2.3 降低管理复杂度
通过标签化管理和分组功能,微隔离简化了复杂的网段规划和策略编写过程。例如,管理者可以为工作负载打上“生产”“开发”等标签,从而大幅减少冗余策略数量,降低管理成本和人为错误带来的风险。传统网络安全,如静态防火墙或访问控制列表(Access Control Lists,ACL)需依赖人工配置,策略一旦复杂,容易产生错误。
微隔离的标签化和可视化管理显著降低了管理难度:(1)基于标签的策略管理,每个虚拟机或容器可以通过属性标签进行分类和分组,例如“生产环境”“开发环境”等,从而简化策略的定义和更新。(2)基于精简的策略规模,传统网络中每个流之间的访问控制需维护独立策略,而微隔离通过标签关联显著减少了单流对应策略数量。例如,一个拥有数百个虚拟机的应用集群只需一个标签策略即可进行全域定义,从而降低人工工作量。(3)基于冲突检测和策略优化,即通过自动化工具和人工智能(Artificial Intelligence,AI)辅助,微隔离系统可以快速检测潜在的策略冲突,并根据实际流量调整策略,有效避免人为设置的冲突。
2.4 合规与审计效率提升
随着数据保护法规逐步严格化,微隔离技术提供了有效的合规解决方案:(1)最小权限验证,即通过基于身份白名单的访问控制,微隔离满足等保2.0中对最小权限原则的要求[6];(2)流量可视化审计,即微隔离系统能够生成清晰的数据流拓扑图,并提供详细的访问日志记录(如工作负载间的访问时间、身份、协议),方便快速响应审计需求;(3)动态合规管理,即当法规要求变更或数据中心资源重新部署时,微隔离可通过标签策略自动调整策略,同时保持合规性和高效性能。
3 微隔离技术的实现路线
微隔离技术的实现路线多种多样,主要包括虚拟化技术、云原生网络插件、软件代理等路线。
3.1 虚拟化技术路线
通过Hypervisor(如VMware ESXi)和虚拟交换机(vSwitch)实现的虚拟化方案,具有良好的动态策略跟随能力。例如,基于VMware NSX实施的虚拟化微隔离可以适配虚拟机的迁移和动态扩展,在不引入额外硬件的情况下实现细粒度分段控制,适用于单一私有云环境,不适用多云异构环境、容器网络环境[7]。
3.2 云原生网络插件
基于云原生的网络架构中,容器网络接口(Container Network Interface,CNI)与扩展伯克利数据包过滤器(extended Berkeley Packet Filter,eBPF)技术通过协同机制构建了高效、灵活的网络方案。CNI作为容器平台的标准化接口,定义了容器运行时与网络插件间的交互协议,通过JSON配置文件动态加载插件链,实现网络命名空间管理、虚拟接口配置及IP地址分配等核心功能。例如,Flannel采用VXLAN隧道构建Overlay网络,而Calico基于BGP协议实现Underlay直连,二者均遵循CNI规范,通过插件链协同支持多网络方案。CNI的IPAM(IP地址管理)模块(如host-local)负责动态分配Pod IP,确保集群内地址唯一性,并通过NetworkPolicy实现Pod间访问控制。
eBPF技术则通过内核可编程机制革新了传统网络处理方式。其核心在于将安全验证的沙箱程序注入Linux内核事件(如网络包处理、系统调用),绕过传统协议栈直接在内核层执行策略。例如,Cilium利用eBPF替代kube-proxy和iptables,在XDP(eXpress Data Path)层实现微秒级网络策略匹配,并通过BPF映射(Maps)与用户态高效交互,吞吐量较iptables提升5倍。eBPF的验证器(Verifier)通过静态分析确保代码安全性,避免内存越界或死循环,而JIT编译器将字节码转为原生指令以降低性能损耗。此外,eBPF支持在流量控制(TC)入口/出口、套接字操作等关键节点挂载程序。例如,Calico通过eBPF在Pod的veth设备上实现策略执行,直接过滤流量而无需依赖iptables规则链。
二者的深度融合体现在Cilium这类CNI插件中:一方面,eBPF替代kube-proxy实现Service的IPVS规则动态更新,减少50%的CPU开销;另一方面,通过Cluster Mesh技术实现多Kubernetes集群的Pod直连通信,支持跨云环境下的服务发现与负载均衡。在安全层面,eBPF程序可在数据链路层实施身份认证(如绑定SPIFFE ID),结合NetworkPolicy实现基于TLS SNI的精细化流量控制。然而,该方案对Linux内核版本(≥4.9)存在依赖,且在虚拟化架构(如VM多租户隔离)及多云混合网络中需结合SR-IOV或智能网卡硬件卸载技术扩展适应性。总体而言,这种方案天然适配服务网格(Service Mesh)和微服务架构需求,但不适应虚拟化架构、私有云、多云混合架构等环境。
3.3 纯软件代理路线
在主机/容器内部署轻量级Agent,通过用户态/内核态拦截流量。支持混合多云环境统一管控、容器网络等混合异构环境,可兼容多种操作系统。
3.4 技术路线对比
微隔离技术路线对比见表2。
4 微隔离系统的部署架构和关键技术
微隔离技术是在零信任背景下快速成为主流运用的一项分段和访问控制技术。微隔离安全平台(以下简称“微隔离系统”)是一套支持跨平台、混合环境部署的内网流量管理系统,提供用户终端到工作负载间及工作负载间的流量可视化和访问控制能力。相较传统的安全域隔离,微隔离通过将内部网络划分为更加精细的微网段,实现东西向流量精细化控制,可通过统一平台实现用户到业务及工作负载之间的零信任访问控制。
4.1 部署架构
微隔离系统由控制平面的微隔离管理中心和数据平面的工作负载主机代理两大组件构成,其部署架构如图1所示。
(1)微隔离管理中心。微隔离管理中心策略的决策点,也是系统的管理控制台,是根据来自工作负载主机代理的资产上下文信息持续进行策略计算,并生成策略下发给工作负载,进而由策略执行点完成策略更新及执行。
(2)工作负载主机代理是工作负载侧的策略执行点,安装于物理机、虚拟机工作负载的操作系统上或容器平台的Node节点上,持续监控工作负载的上下文和运行时的统计信息,并将这些信息不断传送给微隔离管理中心。同时,该组件还会接收微隔离管理中心下发、更新的安全策略,并控制操作系统主机防火墙程序执行策略。
4.2 关键技术
4.2.1 工作负载标签化管理
工作负载标签化管理是指基于多维属性标签,刻画工作负载业务角色、标定工作负载资产身份的管理设计。标签化是实现基于业务的互访流量可视化、面向业务的访问控制和自适应策略计算的基础能力。
4.2.2 业务连接可视化分析
业务连接可视化分析,是将系统学习到的工作负载连接信息,结合其业务角色及用户身份进行统计分析,并利用可视化技术对分析结果进行抽象和梳理,从而以图形化形式为管理者呈现易于理解的东西向流量访问模型。业务连接可视化分析主要解决管理者对数据中心东西向流量不可视、无感知的难题,同时也是进一步确定流量基线、部署访问控制策略的依据。
4.2.3 东西向流量精细访控
东西向流量精细访控是指利用微隔离系统的策略功能,基于“最小特权”原则,对用户终端到工作负载间、工作负载间的东西向流量实现了基于身份的白名单访问控制。基于身份标签制定访问控制策略,一方面可实现安全策略面向业务、访控策略与基础设施解耦的零信任访控模式;另一方面,使得管理者能够使用更加接近自然语言的描述方式定制策略,并大幅减少了策略的数量规模,降低系统运算量及性能开销。
5 微隔离技术面临的挑战与发展方向
5.1 主要挑战
5.1.1 异构环境兼容性不足
云计算从单一环境向混合云、多云、边缘计算场景扩展,异构性成为微隔离实施的主要阻碍[2]。不同平台的软件定义网络(Software Defined Net- work,SDN)能力、不同的通信协议栈均无法统一,这导致策略生成与执行存在明显的碎片化现象。此外,传统数据中心与新型基础设施的融合部署时,还需要适配遗留系统例如Windows Server老版本、大型机等,进一步加大了统一实施的难度。
5.1.2 攻击面的动态扩展
随着远程办公、自带设备(Bring Your Own Device,BYOD)的普及[9-10],设备数量与种类快速增加,部分接入设备缺乏规范化管理,这给微隔离部署带来潜在威胁。攻击者可通过未被完全隔离的设备绕过微隔离策略发起攻击。此外,数据中心的东西向流量增多形成的“流量压力”会进一步放大策略执行点的工作负担,这要求策略应能够兼顾更大规模的攻击面。近年来,一些知名的勒索软件攻击(如WannaCry、Petyad等)层出不穷,由于平面网络架构和访问策略覆盖不足,核心资源暴露面大幅增加,而内部东西向流量激增,防火墙和策略执行点性能遭遇极大压力,部分流量甚至绕过ACL和IDS检测。勒索蠕虫用于扫描并攻击内部东西向流量,利用SMB协议在数据中心高速横向传播。
5.1.3 误配置风险
人工配置微隔离策略可能导致误配置风险。据统计,80%的数据中心安全事故由于人为失误引发。在大规模部署中,人工错误的影响会被放大,同时纠正错误也将进一步耗费资源。例如,据中国专业IT社区CSDN 2023年9月文章显示,某人工智能研究团队在GitHub上发布大量开源培训数据时,意外暴露了38 TB的额外私人数据,其中还包括机密信息、私钥、密码和较多的内部数据。而这一切的源头,仅是一个配置错误的共享访问签名(SAS)令牌。
5.2 未来发展方向
5.2.1 与零信任深度融合
零信任架构强调“永不信任、始终验证”,而微隔离技术可以作为实现零信任环境的一项基础支撑[11],未来需进一步强化微隔离系统与持续身份验证和最小权限原则的结合,通过动态授权限制横向攻击的“爆炸半径”。
5.2.2 AI驱动的动态策略优化
未来微隔离技术可通过结合人工智能与机器学习强化策略制定效率。例如,利用用户行为分析和威胁情报实时检测工作负载间的异常通信行为,并基于分析结果自动生成、调整策略。这不仅可以降低人为介入的机会,避免误配置,还能对高级威胁(如隐蔽攻击、数据泄露)提供更加快速的响应。
5.2.3 改进用户可操作性和策略可视性
为降低策略制定与维护的复杂性,未来微隔离系统需要着重优化用户的操作体验。例如,通过改进策略管理界面,利用自然语言查询技术(Natural Language Query,NLQ)生成策略,帮助管理员理解复杂问题。此外,进一步借助图形化分析工具提升流量基线分析和异常检测的可操作性。
5.2.4 边缘计算与物联网场景扩展
随着物联网设备和边缘计算的发展,微隔离技术需要适应超轻量设备的资源限制与动态接入的特点,例如通过结合边缘网关控制实现分布式访问隔离[10]。另外,还需要进一步探索适配特殊网络协议,如消息队列遥测传输(Message Queuing Telemetry Transport,MQTT)、受限应用协议(The Constrained Application Protocol,CoAP)的策略生成和执行机制,拓展应用场景。
6 微隔离技术在海关网络中的部署路径建议
随着海关信息化的发展,网络逐步演变为“传统网络+多朵云”的多活数据中心架构,同时存在生产环境、开发环境和联调测试环境等多种应用场景。在这种复杂环境下,微隔离技术作为细粒度、安全策略的重要支撑,能够为海关网络提供更加精细化的东西向流量控制与零信任安全保障。海关网络可选择适当的产品进行微隔离策略部署,以达到消除东西向流量的管理缺失安全隐患的目的。以下是针对海关网络的微隔离部署演进建议。
6.1 混合网络架构的安全规划
6.1.1 统一安全治理思路
在多活数据中心环境和云环境中,构建统一的安全管理平台,通过集中式策略管理和分布式策略执行实现全网协同管控。对于生产、开发和测试环境,应制定差异化的安全策略,如生产环境要求更高的访问控制和策略更新频率,而开发和测试环境则可适当降低防控门槛,为业务创新提供弹性支持。
6.1.2 传统网络与云网络的无缝接入
对于存在传统网络的局域网和云网络边缘环境,建议在现有基础设施中引入轻量级代理部署微隔离能力,做到策略统一下发,确保各类网络节点均处于统一策略管理之下。
6.2 部署路径方案
6.2.1 分层隔离与统一策略下发
在海关网络中,可以对不同业务领域、应用环境进行分级隔离。部署时,首先基于工作负载标签化管理,实现细粒度的身份和角色划分;其次设定基于身份白名单的访问控制政策。统一管理中心负责策略的全局计算与更新,下发至各微隔离代理上,从而达到跨平台、跨环境联动的安全防护。
6.2.2 规划评估与试点部署
对海关网络的现有架构、数据流走向和关键节点进行全面评估,确定策略执行点的位置(如服务器、工作负载主机、边界网关等)。步骤上,先在非核心业务进行试点部署,积累经验和数据后再逐步推广。顺序上,可采用急用先上、核心数据系统优先、新上线系统严格执行、存量系统逐步部署的原则。
6.2.3 生产环境的重点保障
对于生产环境,需重点保障实时可视化审计机制,通过监控和日志追踪,不断优化细粒度隔离策略;通过检查阻断日志分析问题根源,主动收集业务部门反馈,快速识别并响应异常情况,确保问题能被即时发现和处理。
6.2.4 微隔离产品部署注意事项
微隔离产品与国产操作系统的兼容性适配,对于不同的安全接口需重构微隔离策略引擎,以兼容统信系统的DDE框架和麒麟系统的UKUI组件。需采用适度级别微隔离策略,一是防止过度隔离导致业务中断,同时降低策略维护的复杂度;二是能够降低国产化设备的性能损耗与资源占用,保证业务处理速度。部署参考流程图如图2所示。
由于需要在内部网络中利用微隔离系统实现精细化的隔离控制,需要明确按照部署流程图予以实施并对关键节点提高注意力,防止策略配置失误后导致业务中断的事故。因此,本文给出图2作为海关网络微隔离部署中的参考流程,在最大程度上保证在提高内网安全防御能力的同时,力求对业务连续性不产生影响。
7 结语
微隔离技术通过逻辑隔离与动态策略机制,为云数据中心网络安全提供了从“粗放式防护”向“精细化管控”转型的关键路径。研究表明,基于标签的细粒度访问控制能够显著降低横向攻击风险。然而,微隔离技术的规模化部署仍需解决多厂商环境兼容性、策略冲突检测与低延迟流量处理等瓶颈。未来研究需进一步探索智能化策略生成、跨平台协同防护等。微隔离技术作为零信任架构的基石,其持续演进将推动云数据中心网络安全从“被动防御”迈向“主动免疫”,为数字时代关键基础设施提供长效保障。
参考文献
[1] Matt Hathaway. Microsegmentation Needs to Isolate All Lateral Movement–Including Service Account Abuse[DB/OL]. (2023-04-10) https://cloudsecurityalliance.org/blog/2023/04/10/microsegmentation-needs-to-isolate-all-lateral-movement-including-service-account-abuse.
[2] 李富宇. 基于分布式微隔离的云计算安全研究[J]. 辽宁大学学报(自然科学版), 2018, 45(1): 19-22.
[3] 王树太, 吴庆, 王振. 私有云安全云管平台关键技术与应用研究[J]. 信息安全与通信保密, 2021(5): 85-93.
[4] NIST Special Publication 800-207. Zero Trust Architec- ture[S]. Maryland: National Institute of Standards and Technology. 2020.
[5] 叶挺. 大数据平台安全架构体系研究与应用[D]. 杭州: 浙江工业大学, 2019.
[6] GB/T 22239—2019. 信息安全技术 网络安全等级保护基本要求[S]. 北京: 中国标准出版社, 2019.
[7] 游益锋. 面向虚拟化环境的微隔离技术的研究[D]. 西安: 电子科技大学, 2019.
[8] 黄竹刚,匡大虎. eBPF云原生安全:原理与实践[M]. 机械工业出版社, 2024: 36-90.
[9] 钟国新, 刘璐豪, 王辉鹏, 等. 自适应主机微隔离安全策略自动生成方法研究[J]. 自动化技术与应用, 2021, 40(12): 54-57.
[10] 李坤, 郝艳. 基于边缘计算的智能微隔离技术[J]. 电子技术与软件工程, 2021(24): 249-251.
[11] 管纪伟, 朱凌君, 张文勇. 基于零信任的公有云微隔离安全研究[J]. 电信工程技术与标准化, 2021, 34(12): 46-56.
第一作者:徐春利(1978—),男,汉族,北京人,本科,工程师,主要从事网络、通信安全相关工作,E-mail: xucl@mail.customs.gov.cn
通信作者:刘鲲(1977—),男,汉族,辽宁彰武人,硕士,高级工程师,主要从事网络、通信安全相关工作,E-mail: liukun@mail.customs.gov.cn
1. 全国海关信息中心(全国海关电子通关中心) 北京 100005
1. National Information Center of GACC (General Administration of Customs of China), Beijing 100005
表1 微隔离技术与传统网络控制手段的区别
Table 1 Differences between micro-segmentation and traditional network control approaches
比较维度 | 微隔离技术 | 传统网络控制手段 |
防护范围 | 工作负载级隔离 (Pod/容器/虚拟机), 东西向流量控制 | 依赖外围防火墙, 以网络边界为中心 |
信任模型 | 零信任架构, 所有流量需显式授权 | 默认信任内部网络 |
策略粒度 | 基于身份、标签的细粒度策略 | 基于区域/VLAN的粗粒度策略 |
动态性 | 实时自适应策略 (算法驱动动态调整) | 静态策略, 人工维护 |
表2 微隔离技术路线对比
Table 2 Comparison of micro-segmentation technical routes
路线 | 性能损耗 | 跨平台能力 | 典型场景 |
虚拟化技术 | ≤5% | 单一虚拟化平台 | 私有云/VMware环境 |
云原生网络插件 | ≤2% (采用eBPF技术)[8] | 容器专属 | Kubernetes/服务网格 |
纯软件代理 | ≤3% | 全平台支持 | 混合多云/容器网络/遗留系统 |
图1 微隔离系统架构图
Fig.1 System architecture diagram of micro-segmentation
图2 微隔离部署流程图
Fig.2 Deployment flowchart of micro-segmentation
