





CopyRight 2009-2020 © All Rights Reserved.版权所有: 中国海关未经授权禁止复制或建立镜像

基于知识图谱和大语言模型的危险化学品通关智能监测模型研究与应用
作者:李珺 李萱 王霄天 黄孙杰 李俊杰 林文静
李珺 李萱 王霄天 黄孙杰 李俊杰 林文静
李 珺 1 李 萱 1 王霄天 1 黄孙杰 1 * 李俊杰 2 林文静 3
摘 要 为进一步防范危险化学品在报关申报过程中出现的错报、漏报及可能造成的监管盲区和安全隐患,构建了一种融合知识图谱与大语言模型的智能监测与预警模型。该模型应用依托海量的海关报关单数据,构建高质量样本库,整合语义识别、参数规则筛选与条件概率建模,形成多层级、多维度的风险判断机制,实现对危险属性的精准量化与实时预警。在技术架构上,该模型应用引入商品中心的知识图谱,结合大模型推理能力,增强语义解析深度与成分逻辑推断准确性。算法通过成分匹配与归一化概率融合评估潜在风险,并设有高频自动分析机制,实现对高风险申报记录的动态识别与即时提示。实践结果显示,该模型应用日均处理数据逾万条,预警命中率显著优于人工审核,显著提升了查验效率与申报质量。本研究为口岸智慧监管、危险化学品合规审查及数字通关提供了可推广、可复制的技术参考。
关键词 危险化学品;错报漏报;知识图谱;大语言模型;智能查验
Research and Application of an Intelligen Monitoring Model for in the Customs Clearance of Hazardous Chemicals Based on Knowledge Graphs and Large Language Models
LI Jun 1 LI Xuan 1 WANG Xiao-Tian 1 HUANG Sun-Jie 1* LI Jun-Jie 2 LIN Wen-Jing 3
Abstract To address the regulatory blind spots and safety risks caused by misreporting and underreporting of hazardous chemicals during customs declarations, this paper develops an intelligent detection and early warning model that integrates knowledge graphs with large language models (LLM). Leveraging massive customs declaration data, the system builds a high-quality sample database and incorporates semantic recognition, parameter-based rule filtering, and conditional probability modeling to develop a multi-level, multi-dimensional risk assessment framework. The architecture centers on a commodity-driven knowledge graph, enhanced by the reasoning capabilities of LLMs to improve the depth of semantic parsing and the accuracy of component inference. The algorithm evaluates potential risks by matching chemical components and fusing normalized probability scores. It also features a high-frequency automated analysis mechanism to dynamically identify high-risk declaration records and issue real-time alerts. Empirical results demonstrate that the model processes over 10,000 declarations on a daily basis, with a warning accuracy significantly higher than that of manual inspection. This approach greatly improves inspection efficiency and declaration quality, offering a scalable and replicable technical solution for intelligent port supervision, hazardous chemicals compliance reviews, and digital customs clearance operations.
Keywords hazardous chemicals; misreporting and underreporting; knowledge graphs; large language model; intelligent inspection
基金项目:深圳海关科研项目(2025SZHK005,2024SZHK001)
第一作者:李珺(1981—),女,汉族,湖南涟源人,硕士,高级工程师,主要从事海关信息化研究工作,E-mail: 43776023@qq.com
通信作者:黄孙杰(1987—),男,汉族,广东湛江人,本科,高级工程师,主要从事海关信息化研究工作,E-mail: 199619162@qq.com
1. 深圳海关信息中心 深圳 518083
2. 深圳大学 深圳 518000
3. 深圳市检验检疫科学研究院 深圳 518000
1. Shenzhen Customs Information Centre, Shenzhen 518083
2. Shenzhen University, Shenzhen 518000
3. Shenzhen Academy of Inspection and Quarantine, Shenzhen 518000
中国口岸科学技术
近年来,深圳逐渐发展为我国危险化学品的重要进出口口岸,进口危险化学品原材料数量大、种类多。危险化学品申报不规范会在一定程度上增加安全生产事故的风险,也会给口岸安全管理带来挑战。在实际业务中,企业本应对涉及危险化学品的货物进行如实、准确申报,但由于业务人员对相关知识掌握程度不一,或企业在填报过程中存在理解偏差,可能会出现危险化学品误报为普通货物的情形,这不仅将提升查验难度,还可能对货物安全性和合规性产生一定影响。因此,建立一套科学的危险化学品识别与概率模型,有助于提升查验环节的精准度与工作效率,为口岸安全管理提供有力技术支持。
当前,海关信息化系统已经实现了电子报关和货物追踪功能,但在智能化、自动化方面,特别是在风险评估、预警机制和数据分析的深度与广度上还有提升空间。为提升企业申报质量,本研究提出了面向企业的危险化学品AI智能识别服务。一方面,该服务可避免企业将普通货物误申报为危险化学品,从而减少不必要的查验,提高通关效率;另一方面,能及时提醒并引导企业纠正漏报危险化学品的情况,提高申报准确性,避免因错报、漏报导致的处罚和整改。上述措施将对优化危险化学品进出口贸易的营商环境产生积极影响。
1 技术路线与模型应用架构
本研究致力于构建一个融合知识图谱[2]与大语言模型的智能化模型应用,旨在精准识别报关单中潜在的危险化学品错报、漏报现象,从而系统性提升口岸的风险识别效率与准确性,为口岸危险化学品的安全管理提供坚实的技术支撑。
1.1 技术架构与整体流程
1.1.1 技术架构
本模型应用采用分层架构设计,主要包括数据层、知识图谱层、大语言模型层、业务逻辑层和应用层,各层之间相互协作,共同完成危险化学品错报、漏报现象的识别任务。各层之间的关系如图1所示。
图1 模型应用架构分层设计示意图
Fig.1 Schematic diagram of the layered architecture for model application
1.1.2 整体流程
本模型应用的整体业务流程开始于企业端的报关单数据录入,风险预警的触达与处置,形成一个闭环的智能监管与服务流程。如图2所示,具体流程描述如下:
图2 模型应用流程图
Fig.2 Workflow of the model application
(1)数据采集与预处理:系统实时接收企业申报的报关单数据,随后进行自动化清洗和标准化处理,提取品名、成分、规格等关键字段。
(2)智能解析与风险初判:大语言模型对申报文本进行深度语义解析,识别化学品名称、别名及潜在属性。同时,业务逻辑层调用知识图谱进行初步的实体链接和规则匹配,例如将商品编码与高风险类别进行比对。
(3)多维风险评估:系统结合大模型解析结果、知识图谱关联分析以及样本库概率模型,对错报、漏报的可能性进行量化打分,生成综合风险概率。
(4)结果反馈与应用:对于识别出的高风险申报,系统在企业提交前即时弹出风险提示,解释风险原因(如成分“乙酸乙酯”为危险化学品,请确认是否已申报),并引导企业用户修正申报信息。同时,对于企业坚持提交或系统判定为极高风险的申报,系统会自动标记并向海关查验人员推送查验风险预警,并且所有处理记录将被存入系统后台,用于模型迭代和宏观风险态势分析。
1.2 模型核心功能
本模型应用旨在实现危险化学品智能报关对企服务,核心功能包括以下几个方面:首先,能对报关单文本信息进行智能解析。通过自然3]处理技术对申报信息分词、词性标注和命名实体4],提取危险化学品相关的关键要素,规范化处理模糊或不规范的表述。其次,基于知识图谱执行危险化学品的匹配与核验,识别企业申报的品名与标准危险品信息之间的差异判断潜在的漏报情形并给出相应提示。第三,运用多维风险评估模型对报关单进行风险分析,计算错报、漏报的概率,并根据结果将商品划分为高、中、低不同风险等级;对于高风险商品实时发出预警信息,强化风险管控能力。除此之外,为帮助企业提高申报质量,本模型应用还提供智能辅助功能,自动识别申报错误并给出修改建议。最后,本模型应用集成了危险化学品相关法律法规和标准规范供企业查询学习,增强企业合规意识,同时基于历史查验数据和评估结果进行统计分析与可视化,生成多维度报表,为企业优化申报策略提供数据支撑。
2 智能模型设计与实现
为确保大语言模型在海关危险化学品这一专业领域的判断的准确性与可靠性,本研究引入了知[5]作为关键的辅助技术,用于提供结构化的领域知识、增强模型推理能力,并对数据进行有效治理。本章将系统性地介绍知识图谱如何与大语言模型深度融合,协同提升危险化学品申报风险的智能预警能力。
2.1 知识图谱驱动的数据治理与清洗
数据质量是模型性能的基础。本研究首先对报关单商品数据(含20项关键字段)进行了系统性数据治理与清洗。通过数据源可靠性评估、随机抽样以及多源数据比对交叉验证等措施,确保数据的可用性与一致性。针对异常值,设定阈值进行识别、清除或修正,并编写自动化清洗脚本以提高效率。此外,根据业务需求构建主题数据表,并设计了定时更新机制,保证数据时效性。这些数据治理步骤为知识图谱的构建提供了高质量的数据基础。
2.2 知识图谱支撑的样本库构建与管理
为有效支撑大语言模型对危险化学品概率的判断与优化,本研究建立了完善的“确危样本库”和“非危样本库”。其中,“确危样本库”基于已申报为危险化学品的报关单数据,“非危样本库”则结合正面/负面参数表,从未申报危险化学品记录中筛[6]。两类样本库均经过标准化标注,确保数据表述的规范性与一致性。
在构建正面参数表时,本研究涉及1597条危险化学品检验检疫名称及其对应检验检疫编码。并参考了国内外危险化学品分类标准和监管要求,包括 联合国《关于危险货物运输的建议书 规章范本》( United Nations Recommendations on the Transport of Dangerous Goods Model Regulations,TDG)以及我国最新版《危险化学品目录》等权-8],这些标准涵盖了2828条危险化学品名称及其对应的CAS号。再结合行业实践经验,筛选出与危险化学品高度相关的报关商品编码范围。通过将这些结构化的标准数据构建成知识图谱的一部分,可以更高效地管理和更新样本库,并为大语言模型提供动态、可靠的外部知识源,从而全面保障样本库的高质量与高可靠。
2.3 知识图谱与大语言模型的深度融合
本模型应用的核心在于构建一个以商品为中心的多维实体知识图谱,将商品编码、化学成分、危险等级以及物理化学性质(如闪点、沸点、毒性等)通过节点和边关联起来,形成结构化的领域知识体系。知识图谱为大语言模型提供事实性约束和领域逻辑支撑,使其强大的自然语言理解能力得以精准应用于领域知识的解析与处理。
在处理申报数据时,大语言模型首先负责对申报文本进行初步解析[9],识别出化学品名称、别名等关键信息。随后,知识图谱介入,提供丰富的领域知识和逻辑关系,用于成分推理、上下文理解与语义消歧,有效解决了大语言模型在专业领域可能存在的“幻觉”和歧10]。通过这种深度融合机制,明显优化了商品属性解析的准确性和完整性,为危险化学品风险评估提供了可靠高效的技术支撑。如图3所示,展示了知识图谱的一个实例。
2.4 知识图谱增强的大模型推理
为提升模型应用智能推理能力,本研究引入知识图谱增强的大语言模型推11]。在解析申报文本时,大语言模型不仅利用其自身的语义理解能力,还能实时查询和调用知识图谱中的结构化信息(如危险等级、理化属性、常见用途等),从而获得更强的逻辑推理和事实核查能力,显著提升判断的准确性和专业性。具体流程是:
大语言模型解析:利用大模型的文本理解能力,从商品要素描述中提取出化学成分列表。
知识图谱关联与增强:根据提取的成分,在危险化学品知识图谱中进行匹配和关联查询,获取这些成分的结构化危12]。
大模型融合推理:大语言模型结合原始文本信息和从知识图谱中获取的增强信息,综合分析并推理出商品中潜在的高危化学成分,并支持基于图谱关系的多步推理。
模型通过大语言模型解析申报文本,提取化学成分后与知识图谱进13],识别命中高危危险化学品成分(如乙酸乙酯、二氯甲烷等),结合成分含量和历史样本,计算其涉危概率。随后,融合商品编码、商品名称等字段风险得分,采用归一化方法得出综合风险值。当综合概率超过阈值或命中多个高危成分时,系统触发高风险预警。这种方法利用大模型灵活的文本解析能力和知识图谱的“校准”功能,实现了危险化学品申报风险的自动14],提升查验准确性与效率。如图4所示,展示了应用大模型成分分析的样例。
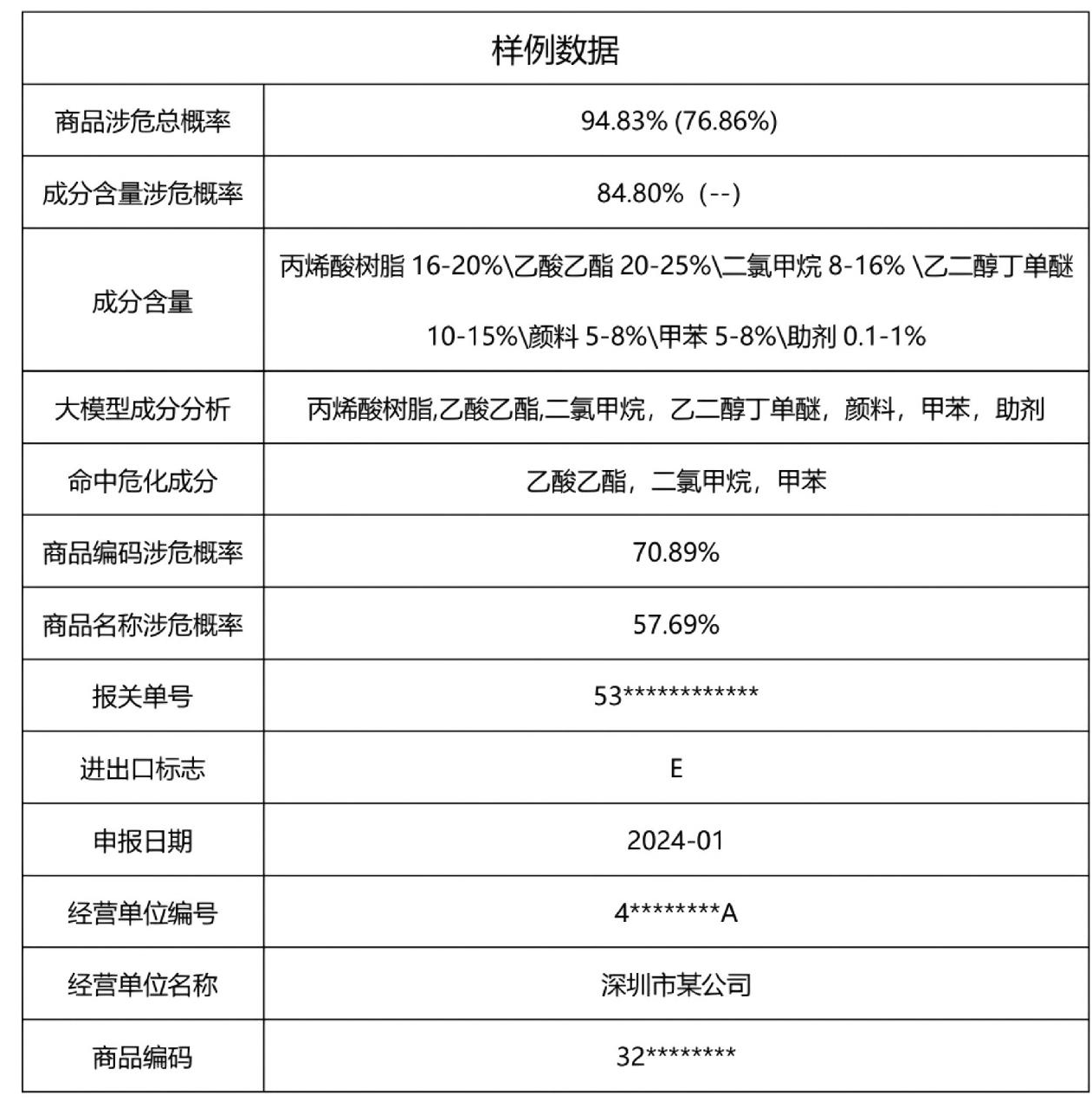
图4 应用大模型进行成分分析的样例
Fig.4 Sample component analysis using LLMs
2.5 危险概率建模与风险智能判别
2.5.1 成分匹配逻辑与概率计算
针对商品成分字段,模型优先执行完整成分匹配,若命中样本库,则直接计算确危概率 P11与非危概率P10。当存在多个匹配项时,模型取最大确危概率Pmax1 P_{max1}Pmax1与最小非危概率Pmax0 P_{max0}Pmax0,以兼顾判断准确性与敏感性。
若商品成分命中多个成分库中的成分,则选取其中概率最大的值作为该成分对应的确危概率,即Pmax1= max{Pi1};从保守角度考虑,取最小非危概率以增加风险评估的敏感性,即Pmax0= min{Pi0}。
2.5.2 总概率计算方法
本模型应用对各字段的确危与非危概率分别相乘,得到总确危概率 Pall1P_{all1}Pall1 与非危概率 Pall0P_{all0}Pall0,进而通过归一化公式如下:
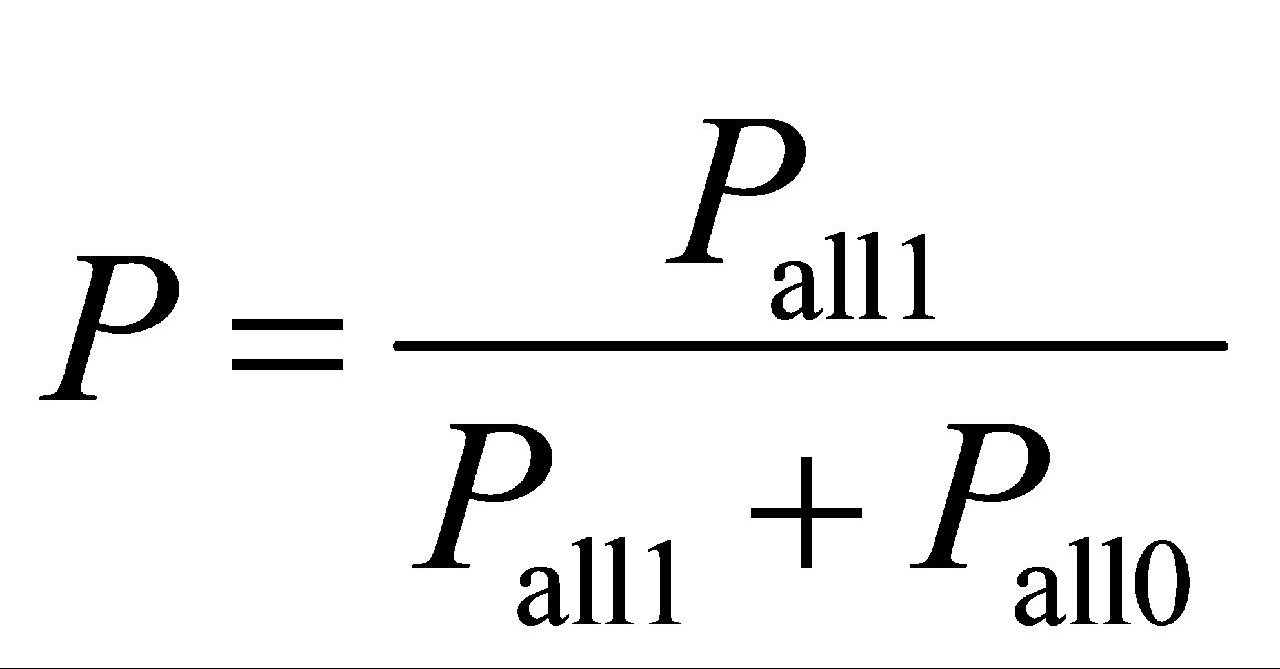
该模型通过计算 Pall1(商品为“危险”时各指标的联合概率)与 Pall0(商品为“非危险”时各指标的联合概率)之比,求得商品属于危险化学品的综合概率。此方法充分挖掘和量化多维字段信息,有效提升风险识别的科学性和准确度。为确保结果的实时性,系统设置每小时自动运行分析任务,处理新报关单数据。结合规则库与知识图谱,该模型能够自动识别成分差异、危险等级偏差等风险特征,智能判断申报异常,并通过实时监测模块及时向用户推送预警,为海关监管提供强有力的决策支持。
3 应用实践
本研究提出并实践了一种以知识图谱技术为核心、大语言模型为辅助的智能风险分析模型。该模型依托知识图谱构建领域知识体系,结合大语言模型的自然语言处理能力,应用于进出口报关单数据的自动化分析。该模型每小时自动分析前一小时内的所有报关单信息,日均处理量稳定超过12000条,平均每小时处理约500条。在实际应用过程中,模型仅筛选输出危险概率超过设定阈值的高风险记录,测试期间每日平均推送3~5条可能存在错报或漏报的预警信息。与传统模式下查验人员每小时需人工逐一审阅超过100条报关单,并研判危险化学品错报、漏报的方式相比,模型显著提高了审核效率,缓解了一线查验人员的工作压力,同时有效降低了对非危险化学品的误判概率。
通过近一年历史数据的训练,模型具备了对申报信息中成分描述模糊、属性表达矛盾或商品分类异常情况的精准识别能力,累计输出高风险预警提示629条,其中准确提示记录598条,提示准确率达到95.1%。进一步的实践统计发现,已有5条模型预警的记录被查发确认为重大错报案件,充分验证了模型在识别关键风险点方面的有效性。综合评估表明,该模型在实现高处理吞吐量的同时,具备较高的精准识别能力,误报率明显低于传统规则引擎或人工筛查方式。该模型利用成分语义推理和知识图谱风险关联技术,有效识别并捕捉描述模糊、分类异常的危险化学品申报行为,为口岸风险防控提供了强大的技术支撑,有力推进了海关风险管理向智能化、精细化方向发展。
4 结论
本研究围绕危险化学品通关过程中可能存在的错报、漏报问题,构建了一种融合知识图谱与大语言模型的智能化实时监测算法。模型应用通过整合数据治理、样本库管理、商品属性识别、条件概率建模与风险评估等关键模块,实现了对报关单中危险化学品信息的自动解析、精准识别与智能预警。应用实践表明,模型能够在高通量条件下保持较高的风险识别准确率,显著减轻人工审核负担,并帮助企业提高申报合规性,促进海关风险管理与服务水平的协同提升。
下一步,本研究将集中在进一步优化模型的准确性和泛化能力上,将继续扩大样本库规模,引入更多类型的危险化学品数据,以提高模型对各种复杂情况的适应性。此外,笔者还将关注模型的实际应用效果,持续收集用户反馈,不断调整和优化系统,确保其在实际操作中更加稳定、高效。
参考文献
[1] Du W, Wang X, Zhu Q, et al. CPBA-CLIM: An entity-relation extraction model for ontology-based knowledge graph construction in hazardous chemical incident management.[J]. Science Progress, 2024, 107(1): 2. DOI: 368504241235510-368504241235510.
[2]唐晓晟, 程琳雅, 张春红, 等. 大语言模型在学科知识图谱自动化构建上的应用[J]. 北京邮电大学学报(社会科学版), 2024, 26(1): 125-136.
[3]孙伟, 李一, 马永强. 基于自然语言处理技术的知识图谱构造方法研究[J]. 集宁师范学院学报, 2023, 45(5): 94-97.
[4]程思嘉. 基于改进深度学习算法的危废库火灾智能识别方法[J]. 安全、健康和环境, 2022, 22(9): 12-16.
[5] Lan Y, He S, Liu K, Zhao J. Knowledge Reasoning via Jointly Modeling Knowledge Graphs and Soft Rules[J]. Applied Sciences, 2023, 13(19): 10660. DOI: 10.3390/app131910660.
[6] Zheng X, Wang B, Zhao Y, et al. A knowledge graph method for hazardous chemical management: ontology design and entity identification[J]. Neurocomputing, 2021, 430: 104-111.
[7]宗健, 刘庆. 危险货物和危险化学品辨析[J]. 中国海关, 2024(12): 56.
[8]于晓, 管晓倩, 万敏. 《危险化学品目录 (2015版)》中部分具有同分异构体条目危险性分类的研究[J]. 职业卫生与应急救援, 2024, 42(3): 403-406.
[9]秦小林,古徐,李弟诚,等.大语言模型综述与展望[J].计算机应用, 2025, 45(3): 685-696.
[10]吴信东,黄满宗,卜晨阳. BEKO:大语言模型与知识图谱的双向增强[J].计算机学报, 2025, 48(7): 1572-1588.
[11]张学飞,张丽萍,闫盛,等. 知识图谱与大语言模型协同的个性化学习推荐[J].计算机应用, 2025, 45(3): 773-784.
[12]徐涌鑫, 赵俊峰, 王亚沙, 等. 时序知识图谱表示学习[J]. 计算机科学, 2022, 49(9): 162-171.
[13]冯拓宇, 李伟平, 郭庆浪, 等. 大语言模型增强的知识图谱问答研究进展综述[J]. 计算机科学与探索, 2024, 18(11): 2887-2900.
[14]周珏斐. 《全球化学品统一分类和标签制度》中加和法不适用时的混合物分类[J]. 肥料与健康, 2023, 50(3): 69-73+76.
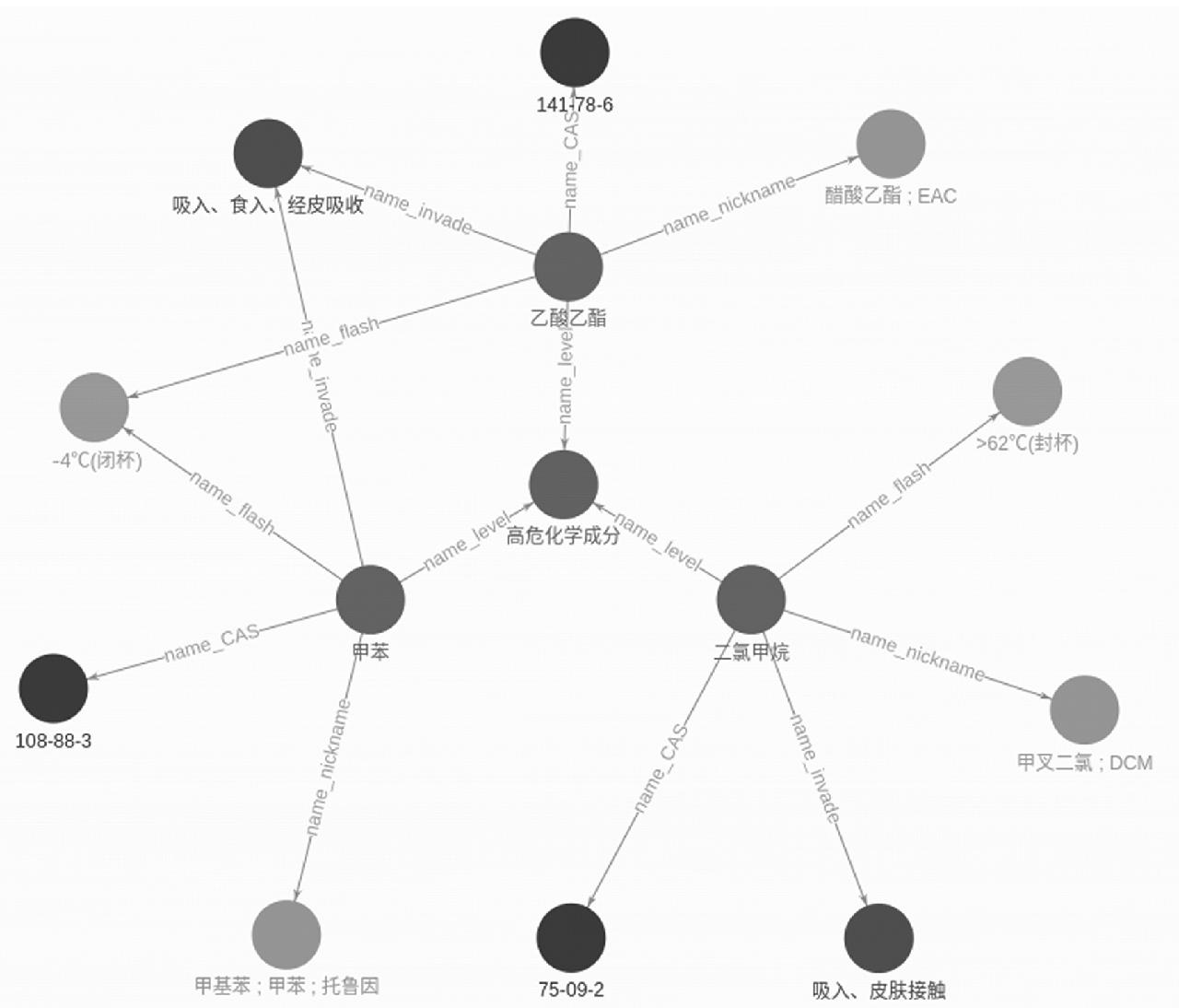
图3 危险化学品知识图谱示例
Fig.3 Sample knowledge graph of hazardous chemicals
