





CopyRight 2009-2020 © All Rights Reserved.版权所有: 中国海关未经授权禁止复制或建立镜像

基于知识图谱和检索增强生成技术的加贸企业智慧监管模型研究
作者:黄孙杰 李珺 邢军 张慧昕 吴佳明
黄孙杰 李珺 邢军 张慧昕 吴佳明
黄孙杰 1 李 珺 1 邢 军 1 张慧昕 1 * 吴佳明 2
摘 要 加工贸易作为我国对外贸易的重要组成部分,面临供应链复杂度高、政策动态性强、企业监管难度高等挑战。本研究提出一种基于知识图谱(Knowledge Graphs)与检索增强生成(Retrieval-Augmented Generation,RAG)技术的企业分析模型,通过构建多维度企业知识图谱,结合Embedding模型与检索增强算法,实现监管因素的动态挖掘与智能预警,为海关监管提供可解释性强、响应迅速的支持方案。
关键词 知识图谱;图数据库;检索增强生成;Embedding模型
Research on Intelligent Supervision Model for Processing Trade Enterprises Based on Knowledge Graphs and Hybrid Retrieval-Augmented Generation
HUANG Sun-Jie 1 LI Jun 1 XING Jun 1 ZHANG Hui-Xin 1* WU Jia-Ming 2
Abstract Processing trade central to China’s foreign trade faces challenges stemming from complex supply chains, volatile policy environments, and hidden corporate credit risks. This paper presents a KG-RAG-based risk-analysis framework that combines a multi-dimensional corporate knowledge graphs with hybrid retrieval-augmented generation. By integrating embedding models and retrieval-augmentation algorithms, the framework enables dynamic identification and intelligent early-warning of processing-trade risks, offering customs authorities a highly interpretable, rapid-response decision-support tool.
Keywords knowledge graphs; graph database; retrieval-augmented generation; embedding mode
加工贸易在我国对外贸易中占有重要地位,与一般贸易相比,具有“两头在外”,即“原料从外进,产品在外销”的特征,具体包括来料加工、进料加工等形式。新形势下,海关对加工贸易企业的监管方式面临多重挑战:一是企业备案信息、报关单数据、征信数据存储于不同业务系统,需要快速关联分析。二是动态数据更新周期较长,企业经营范围、实际控制人等信息变更后,动态数据更新应具有及时性。三是企业填报信息文本较长,且存在同义词、口语化表述等非结构化数据特征,语义理解复杂。
近年来,知识图谱技术通过整合多源异构数据构建语义网络,为企业因素关联分析提供了新路径,而检索增强生成(Retrieval-Augmented Generation,RAG)技术则能动态融合外部知识提升推理精度。本研究针对加工贸易企业监管,结合知识图谱的多源数据整合能力与RAG的动态知识更新优势,并且融合Embedding模型、BM25算法模型等检索技术,构建了面向加工贸易企业的智能分析模型,为海关智能化监管提供实践参考。
1 关键技术
1.1 知识图谱和图数据库
知识图谱(Knowledge Graphs)是一种基于图结构的知识表示方法,通过实体(Entity)、关系(Relation)和属性(Property)构建语义网络,以可视化方式实现对现实世界复杂关联的结构化建模。其中,实体表示现实世界的对象,通过唯一标识符区分不同概念;关系是定义实体间的语义连接,支持方向性与权重属性;属性是描述实体或关系的特征。知识图谱通常被描述为一个以实体为节点,以关系为边的多关系图,每条边都被描绘成一个三元组(头部实体,关系,尾部实体),表示两个实体之间的关系[1-3]。
图数据库(Graph Database),是一种以图结构为核心的数据存储与管理系统,专门用于存储、管理和查询高度关联数据,是知识图谱的基础设施,其核心以图论为理论基础,通过节点(Node/Vertex)、边(Edge/Relationship)和属性(Property)构建数据模型,直接映射实体间的复杂关系。
知识图谱与图数据库互为支撑、协同演进,知识图谱作为语义网络的应用层,通过实体、关系及属性的结构化建模,将现实世界的复杂关联转化为可计算的图结构,其构建过程依赖图数据库的存储与计算能力。图数据库作为底层基础设施,以节点、边为核心数据模型,提供高效的图遍历查询、动态关系挖掘及灵活的模式扩展功能。
1.2 检索增强生成技术
RAG是一种结合信息检索技术与大语言模型(Large Language Model,LLM)的创新框架,旨在通过动态引入外部知识库提升生成内容的准确性与可靠性。其核心流程分为三个阶段:检索阶段,利用嵌入模型将用户查询转换为向量,从向量数据库中筛选出语义最相关的文本片段;增强阶段,将检索结果与原始查询拼接为上下文提示,通过提示工程引导LLM理解任务;生成阶段,基于增强后的上下文,由LLM输出融合外部知识的自然语言响应[4]。
RAG在一定程度上解决了LLM的“幻觉问题”和“知识固化”等缺陷,相较于传统微调,RAG无需调整模型参数即可实现知识更新,且支持多模态数据融合与细粒度权限控制,在智能客服、内容创作、企业知识管理等场景中展现出显著优势[5]。
1.3 Embedding模型
Embedding模型是一种将高维、离散或非结构化数据映射到低维连续向量空间的技术,这些向量能够捕捉数据之间的语义、结构等关系。模型将输入的数据表示成一个连续的数值空间中的点,从而把原本难以直接处理的符号数据,转换成计算机能理解和操作的向量形式的数值,语义相似的单词在向量空间中距离更近。从技术演进看,Embedding模型经历了从静态词嵌入到动态上下文相关模型,再到多模态融合的发展历程,逐步实现跨语言、跨模态的语义对齐[6-8]。
Embedding模型是RAG相似检索召回的关键一环,直接影响到信息检索的效果和生成文本的质量。它能够帮助系统快速准确地检索到与查询文本相似的文档或段落,从而增强生成模型的回答能力和准确性[9]。
1.4 BM25算法模型
BM25(Best Matching 25)是一种基于概率检索框架的经典信息检索算法[10],通过词频饱和控制和网页长度归一化优化传统TF-IDF算法的不足,BM25算法的基本公式如下:
式中,Score(D,Q)是文档D与查询Q的相关性得分,qi是查询中的第i个词,f(qi,D)是词qi在文档D中的频率,IDF(qi)是词qi的逆文档频率,|D|是文档D的长度,avgdl是所有文档的平均长度,k1和b是可调的参数,通常k1在1.2~2之间,b通常设为0.75。
BM25通过平衡精确匹配与长文本惩罚,显著提升搜索引擎相关性排序效果,常被用于估计文档与用户查询之间的相关性,在处理长文本和短查询时效果较好。
2 模型构建
本研究构建了知识图谱,通过Neo4j存储企业、商品、政策等多实体关系,为关联分析提供结构化基础;引入RAG技术,当加工贸易企业的监管信息数据更新时,实时调整查询策略。基于BM25算法和Embedding模型,优化企业填报的长文本信息识别,捕捉同义表述的语义关联,扩展检索范围,为模型优化自然语言理解、提高查询精准性方面提供支撑。最终,将检索结果输入大模型,生成包含风险等级、关联企业的全结构化分析报告,实现从数据关联到风险研判的闭环。
2.1 模型架构
基于以上技术,本研究针对加工贸易企业构建了一套基于知识图谱和RAG,并且融合了BM25和Embedding模型的智慧监管模型,模型基本架构如图1所示。该架构通过分层技术协同,既保留了BM25的精确匹配能力,又强化了Embedding的语义理解优势,通过RAG实现动态知识融合,利用大模型的生成能力向用户反馈结论,在响应时间与召回率间取得平衡。
2.2 构建知识图谱
本模型数据来源为某直属海关收到的报关单数据,选用Neo4j图数据库构建加工贸易企业知识图谱,从企业数据中抽取实体作为节点,属性一致的建立关联关系形成边,构建图数据库。基本过程如下:
(1)从企业数据(报关单、备案清单、企业征信等)中抽取核心实体,其中,企业实体包括企业名称、注册地、信用等级、经营范围等;贸易实体包括商品编码、进出口时间、货值、贸易伙伴等。
采用Neo4j图数据库构建多层级知识网络,其中,企业节点(Enterprise)中属性包含注册地址、成立时间、行业分类等;商品节点(Commodity)中关联HS编码、商品描述、监管条件等。
形成的知识图谱如图2所示。
2.3 BM25+Embedding混合算法分析
BM25基于词频统计,擅长精确匹配信息关键词(如企业名称、法人),精准召回问答实体;Embedding通过。
本模型综合两算法优势,将BM25得分与语义Embedding的余弦相似度加权融合,BM25负责精确匹配初筛(召回Top-100候选),Embedding进行语义精排(Top-10重排序),综合提升召回率与精度。在用户输入指令后,BM25通道会精准拦截关键词,并进行分词处理,倒排索引检索匹配文档中相同关键词。同时,Embedding通道捕捉语义扩展内容,对分词切片向量编码找到余弦相似的文档。在知识图谱中召回符合关键词的实体节点,并沿节点→边→节点遍历查询,检测符合指令内容的标签。
2.4 RAG动态检索和大模型提取
通过BM25与Embedding混合检索获取的候选内容,需经过结构化重组与语义增强后输入大模型,最终生成符合用户需求的答案。本模型设计了多阶段Prompt引导模型生成结构化回答,如:
page_content”: [
“XXX有限公司的法人代表是谁?”,
“XXX有限公司的注册地址在哪里?”,
“XXX有限公司的注册资金多少?”,
“XXX有限公司的主营业务是什么?”,
“XXX有限公司的实际控股人是谁?”,
“哪家公司的法人代表是XXX?”
]
用户在输入端提出基于企业信息的监管要素查询的prompt,模型将引入结构化问答内容,对算法给出的查询内容进行系统整合并给出回答。例如,提问:“XX地区地址相近、主营业务相近的企业有哪些?”回答:“根据您提供的信息,以下是XX地区地址相近、主营业务相似的企业。这些企业主营业务相似,且可能在同一地点注册或在同一产业园内经营。”同时,根据反馈数据生成统计表,见表1。
3 应用实践
采用本模型,对某直属海关2023年1月—2024年6月的加工贸易企业监管数据,包含10万条企业备案信息、50万条报关单记录及2000条历史风险案例进行评估。评价指标采用误检率(错误识别为风险企业的比例)、召回率(正确识别的风险企业占实际风险企业的比例)及平均响应时间(从用户提问到生成答案的时间)。如表2所示,相比单一知识图谱检索和传统规则库匹配,本模型采用的技术方案召回率均有提升,误检率均有下降。其中,与传统方法相比,本模型在主营业务异常识别任务中,误检率从22%降至9%,召回率从65%提升至92%,企业监管的智能化、便利程度有较大提升。
表2 模型应用实践结果对比
Table 2 Experimental results
技术方案 | 召回率 (%) | 误检率 (%) | 响应时间 (s) |
传统规则库 | 65 | 22 | 2.1 |
单一知识图谱 | 78 | 18 | 3.5 |
RAG+知识图谱 | 92 | 9 | 4.2 |
4 结语
本研究针对加工贸易企业监管信息分析中存在的数据孤岛、语义理解难等问题,探索构建了“知识图谱+RAG”的智能分析框架。通过Neo4j图数据库实现企业、商品、政策的多维度关联建模,结合BM25与Embedding的混合检索算法,在关键信息召回率与响应速度间取得平衡。实践结果表明,该模型能有效识别企业地址变更、主营业务异常等信息,监管效能明显提升。未来可通过引入动态图计算与多模态数据融合,进一步提升监管要素分析的深度与广度,为海关智慧监管提供更有力的技术支撑。
参考文献
[1]张明韬, 杨国利, 白晓颖. 基于嵌入模型的知识图谱准确性评估[J/OL]. 软件学报, (2025-01-21)[2025-08-07]. https://doi.org/10.13328/j.cnki.jos.007403.
[2]李术, 雒伟群. 一种基于知识图谱的西藏考古文物语义检索系统设计[J]. 中国科技信息, 2025(12): 47-49.
[3]吕晓斌, 黄浩森, 周鑫, 等. 融合知识图谱与对比学习的企业风险小样本鲁棒识别方法[J].计算机应用, 2024, 44(S2): 55-60.
[4]李晴慧, 丁合. 编辑出版学视角下学术知识库的RAG构建研究——以岭南武术为例[J].武术研究, 2025, 10(6): 11-14.
[5]柴晨, 梁莹, 冯蕊. 基于文本挖掘的交通工程专业学科交叉本研贯通课程群建设[J]. 高等工程教育研究, 2025(4): 79-81+130.
[6]樊小帅, 李卓卿, 张效华, 等. 基于大模型与知识图谱增强型RAG的钢铁行业标准问答系统[J/OL]. 冶金自动化, (2025-01-15)[2025-08-07]. https://link.cnki.net/urlid/11.2067.TF.20250627.0956.002.
[7]邸晓丽, 王莉. 大语言模型置信度驱动的交互式知识图谱补全方法[J/OL]. 计算机工程与应用, (2025-01-12)[2025-08-07]. https: //link.cnki.net/urlid/11.2127.TP.20250620.1435.003.
[8]赵广宇, 段永康, 耿骞, 等. 基于LLM数据增强和对比学习的政务相似问题检索研究[J/OL]. 数据分析与知识发现, (2025-01-18)[2025-08-07]. https://link.cnki.net/urlid/10.1478.G2.20250701.1501.006.
[9]刘俊伟,钱昱辰, 周泽宇, 等. 基于大模型和检索增强生成技术的军事知识问答系统研究与应用[C]//中国指挥与控制学会. 第十三届中国指挥控制大会论文集(下册), 杭州智元研究院有限公司, 2025: 598-604.
[10]游新冬, 张旭, 吕学强, 等. 面向实体搜索的大语言模型测试评估技术[J]. 宇航计测技术, 2024, 44(6): 1-13.
基金项目:深圳海关科研项目(2025SZHK005,2024SZHK001)
第一作者:黄孙杰(1987—),男,汉族,广东湛江人,本科,高级工程师,主要从事海关信息化工作,E-mail: 199619162@qq.com
通信作者:张慧昕(1999—),男,汉族,黑龙江哈尔滨人,本科,主要从事海关信息化工作,E-mail: 1595445302@qq.com
1. 深圳海关信息中心 深圳 518083
2. 河南科技大学 洛阳 471000
1. Shenzhen Customs Information Center, Shenzhen 518083
2. Henan University of Science and Technology, Luoyang 471000
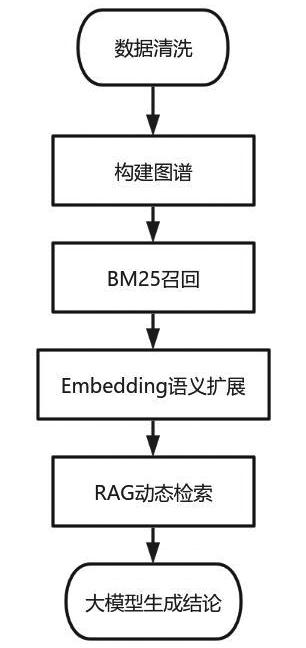
图1 智慧监管模型架构图
Fig.1 Model architecture diagram
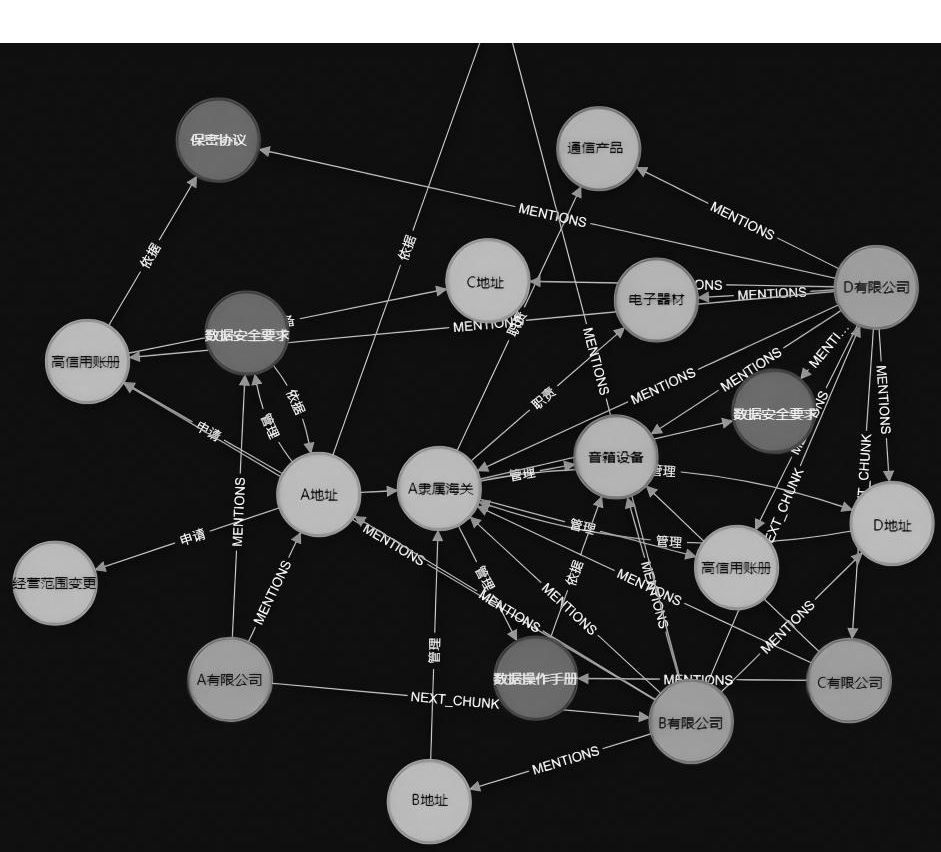
图2 加工贸易企业知识图谱
Fig.2 Knowledge graphs of processing trade enterprises
表1 查询结果统计表
Table 1 Query result statistics table
企业名称 | 注册地址 | 主营业务 |
XA有限公司 | 深圳市XX地区1号A栋201室 | 电子产品、通信器材 |
YB有限公司 | 深圳市XX地区1号A栋201室 | 电信器材、机电设备 |
ZC有限公司 | 深圳市XX地区1号A栋201室 | 音响设备、照相器材、仪器仪表 |
