





CopyRight 2009-2020 © All Rights Reserved.版权所有: 中国海关未经授权禁止复制或建立镜像

视觉大模型在口岸杂草识别中的应用
作者:季晓飞 薛华杰 江锦海 程云辉 黄小水 姚伟华
季晓飞 薛华杰 江锦海 程云辉 黄小水 姚伟华
季晓飞 1 薛华杰 1 江锦海 1 程云辉 2 黄小水 3 姚伟华 2
摘 要 目前,大量的杂草智能识别软件工具能够识别园林花卉类等常见杂草,但无法满足口岸杂草监测、普查和疫情防控识别的专业需求。本研究通过“视觉大模型基座+任务头”的模型架构,借助开源视觉大模型基座获取杂草图像表征向量,设计多层全连接网络模型作为分类任务头识别上海口岸216种常见、重点关注和检疫性杂草及其同属近似种。实验对比了基于不同开源视觉大模型基座以及不同单物种最低样本量数据集的识别效果,并引入基于AdaptFormer框架的参数高效微调方法提升识别准确率,实现训练参数效率与性能之间的均衡。在单物种最低样本量为100~3000时,模型的top1识别准确率为90.49%~94.43%,top5识别准确率为98.84%~99.27%,可满足口岸杂草识别应用需求。
关键词 大模型;杂草识别;深度学习
Research on the Application of Large Vision Models in Weed Identification at Ports
JI Xiao-Fei1 XUE Hua-Jie1 JIANG Jin-Hai1
CHENG Yun-Hui2 HUANG Xiao-Shui3 YAO Wei-Hua2
Abstract While a large number of intelligent weed identification software tools exist for recognizing common plants such as ornamental and garden flora, they fall short of meeting the specialized requirements of weed monitoring, weed surveys and epidemic prevention and control identification at ports. This study adopted a “large vision models backbone + task head” architecture that employs large open-source vision models to extract image representation vectors of weeds, and a multi-layer fully connected neural network was designed as the classification task head to identify 216 weed species at Shanghai port, including common varieties, species of special concern, quarantine-targeted weeds, and their congeneric relatives. The experimental evaluation compared the recognition performance based on different open-source large vision models backbones and datasets with varying minimum sample sizes per species. By integrating parameter-efficient fine-tuning via AdaptFormer, we achieve an optimal balance between model performance and training efficiency. When the minimum sample size per species ranged from 100 to 3000, the model achieves a top-1 identification accuracy of 90.49%-94.43% and a top-5 identification accuracy of 98.84%-99.27%, meeting application requirements for weed identification at ports.
Keywords large model; weed identification; deep learning
基金项目:海关总署科研项目(2024HK217)
第一作者:季晓飞(1976—),男,汉族,江苏南通人,博士,正高级工程师,主要从事海关信息化工作,E-mail: ji_xiaofei@customs.gov.cn
1. 上海海关 上海 210135
2. 上海亿通国际股份有限公司 上海 201203
3. 上海交通大学 上海 200025
1. Shanghai Customs, Shanghai 210135
2. Shanghai E&P International INC, Shanghai 201203
3. Shanghai Jiao Tong University, Shanghai 200025
杂草的准确识别是进出境口岸开展疫情监测、普查及防控工作的前提和基础。传统识别方法以人工鉴定为主,不仅耗时耗力,而且对鉴定人员的专业水平和实践经验要求较高。
深度学习是常用的杂草图像识别技术,众多学者在此领域展开了深入探索,取得了一系列具有价值的研究成果,但仍存在一些需要进一步研究的问题[1-2]。一方面,深度学习模型的训练高度依赖大规模的标注数据集,而构建高质量的杂草图像标注数据集需要耗费大量的人力、物力和时间,且数据标注的准确性和一致性难以保证。不同标注人员对杂草特征的理解和判断可能存在差异,这会影响数据集的质量,进而影响模型的训练效果。另一方面,杂草的生长环境复杂多样,不同环境因素如光照、湿度、土壤条件等会导致杂草外观发生变化,增加了图像识别分类的难度。在野外环境中,杂草可能会受到遮挡、病虫害等影响,使得获取的图像特征不完整,从而降低模型的识别准确率。此外,现有的深度学习模型在小样本杂草分类任务上表现欠佳,对于一些样本数量较少的杂草种类,模型难以学习到足够的特征来进行准确分类。
近年来,大模型的能力涌现给杂草识别带来了新的思路。视觉大模型的发展主要围绕自监督学习和视觉变换器(Vision Transformer,ViT)展开,旨在构建具有强泛化能力的视觉主干网络[3]。语言—图像预对比训练(Contrastive Language–Image Pretraining,CLIP)通过对比学习同时训练图像和文本编码器,将图像和文本映射到共享的嵌入空间[4]。该方法在图像分类、跨模态检索等任务中表现出色,尤其在零样本学习场景中展现了强大的泛化能力。无标签自蒸馏(Self-DIstillation with NO Labels,DINO)采用自监督的方式训练ViT模型,通过教师—学生网络结构进行无标签的自我蒸馏学习[5]。该方法在ImageNet上实现了80.1%的top1准确率,且在语义分割等任务中展现出良好的特征迁移能力。作为DINO的升级版本,DINOv2在架构、损失函数和优化技术上进行了改进,并在更大规模的数据集(1.42亿张图像)上进行自监督训练[6]。该模型无需微调即可在多个下游任务中达到或超过行业标准,展现出更强的泛化性能。国内研究机构也陆续发布开源视觉语言大模型,包括InternVL、Qwen-VL、CogVLM等,均在多项图文多模态标准测试中获得高分,堪比GPT-4o、Gemini等国际视觉大模型[7-13]。
基于以上研究基础,本研究探索采用视觉大模型技术构建高效、准确的杂草图像分类模型,为口岸杂草识别提供技术支撑。
1 模型架构
本文采用的模型架构图如图1所示。
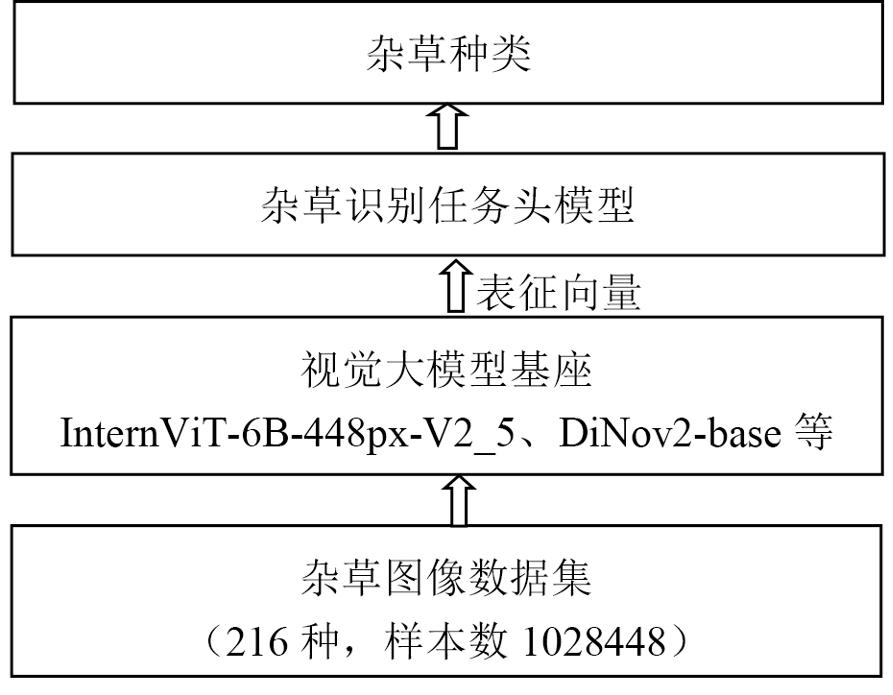
图1 基于视觉大模型的杂草识别模型
Fig.1 Weed identification model based on large vision models
视觉大模型基座作为整个架构的核心,负责对输入的杂草图像进行特征提取。其接受图像文件作为输入,图像经预处理后分辨率统一为224×224,通过一系列复杂的神经网络层进行计算和处理,输出图像表征向量。该向量是对杂草图像的一种高维抽象表示,包含了图像中丰富的图像信息和特征信息。不同的大模型在网络结构、参数数量、计算方式等方面存在差异,这些差异会直接影响到图像表征向量的维度和特征表达能力。在实际应用中,选择合适的大模型对于提取准确有效的杂草图像特征至关重要。本研究选用InternViT-6B-448px-V2_5(以下简称InternViT-6B)、DINOv2-base作为基座,其输出的杂草图像表征向量维度分别为3200和768。
任务头则是连接在大模型之后,专门用于完成杂草图像分类任务的模块。它以大模型输出的图像表征向量作为输入,通过一系列的全连接层、激活函数以及分类器等组件,对图像的类别进行预测。任务头的设计紧密围绕杂草图像分类任务的特点和需求,通过对图像表征向量的进一步处理和分析,将其映射到具体的杂草类别上。本研究使用多层全连接神经网络模型作为任务头分类模型,相关参数见表1。
表1 任务头模型参数
Table 1 Parameters of task head model
参数名 | 参数值 |
输入层 | 1×图像表征向量维度 |
全连接层各层节点数 | 1024-2048-4096-2048-1024-512-256 |
全连接层激活函数 | ReLU |
输出层节点数 | 1×杂草种类 |
输出层激活函数 | softmax |
模型损失函数 | 交叉熵 (categorical_crossentropy) |
模型优化函数 | adam |
模型评价指标 | 准确率 |
批量值 | 64 |
在设计任务头模型时,需要考虑多个因素。例如,全连接层的层数和节点数量会影响任务头对图像特征的学习和表达能力,适当增加全连接层的层数和节点数量可以提高模型的拟合能力,但也可能导致过拟合问题;激活函数的选择会影响模型的非线性表达能力,常用的激活函数如ReLU、Sigmoid等具有不同的特性,需要根据具体情况进行选择;分类器的设计则直接决定了模型对杂草类别的预测方式,常见的分类器如Softmax分类器,通过计算每个类别对应的概率,选择概率最大的类别作为预测结果,实现对杂草图像的分类。
2 数据集
本研究的训练数据集涉及杂草图片数据来源广泛,涵盖了实地拍摄、网络资源库等多个渠道,充分反映了光照、自然遮挡等干扰因素,以及不同的拍摄者、拍摄设备和拍摄风格等人为因素对杂草图片形态的影响。
根据口岸杂草检疫需求,本研究对数据集进行了针对性的处理和筛选。将部分种级杂草数据作为重点关注识别样本,这些样本对于海关在杂草监测、普查、疫情防控等实际业务中具有重要意义。将与重点关注种在同属下的其他种数据作为同属近似种识别数据纳入数据集的构建中,以增加数据的多样性和模型的泛化能力。数据集包含了87属216种杂草,基本覆盖了上海口岸常见、重点关注和检疫性杂草及其近似种,样本总数共1028448张,见表2。
表2 数据集种数及样本数
Table 2 Number of species and samples in the dataset
种类 | 种数 (种) | 样本数 (张) |
重点关注种 | 135 | 283162 |
同属近似种 | 81 | 745286 |
合计 | 216 | 1028448 |
为了使模型能够更好地学习和泛化,将数据集各类别按9∶1比例划分训练集和测试集。训练集用于模型的参数学习和优化,通过大量的样本数据让模型逐渐掌握杂草图像的特征和分类规律。测试集则用于评估模型的性能,在模型训练完成后,使用测试集对模型进行测试,以客观地衡量模型在未知数据上的分类准确性和泛化能力。
3 建模实验
为了深入研究和优化杂草图像分类模型的性能,本研究基于前文所述模型架构进行了一系列建模实验。这些实验从不同的角度出发,对模型的各个关键要素进行了探索和分析,以找到最适合杂草图像识别任务的模型配置和参数设置,从而提高模型的准确性、泛化能力和稳定性。
3.1 不同大模型基座的对比
本实验选择的开源视觉大模型基座分别为InternViT-6B和DINOv2-base,以探究不同基座模型对杂草图像分类性能的影响。InternViT-6B采用了视觉Transformer架构,在大规模数据上进行预训练,具备强大的特征提取能力,尤其擅长捕捉图像中的全局特征和复杂语义信息。DINOv2-base 同样基于Transformer架构,通过自监督学习方式进行训练,能够学习到丰富的图像特征表示,在多种计算机视觉任务中表现出色。
实验分别将杂草图像数据输入作为图像特征提取器的InternViT-6B和DINOv2-base,获取图像表征向量。然后,将这些向量输入到相同结构的分类任务头模型中,预测输出杂草种类。通过该实验,可初步评估杂草识别场景下,两个基座模型的适配优劣性。识别结果见表3。
表3 基于不同视觉大模型基座的杂草识别情况
Table 3 Weed identification performance using different large vision models foundations
模型 | 表征向量维度 | (%) | (%) |
InternViT-6B | 3200 | 72.20 | 69.10 |
DINOv2-base | 768 | 87.48 | 84.17 |
由表3可知,总体上DINOv2-base模型表现优于InternViT-6B模型。无论是在训练集上的最优准确率(87.48%对比72.2%),还是在测试集上的准确率(84.17%对比69.1%),DINOv2-base模型的准确率都明显更高。
杂草图像的表征向量维度与最终模型的预测性能并非简单的正相关关系。InternViT-6B的表征向量维度为3200,高于768的DINOv2-base的表征向量维度,但它的模型的预测准确率却低于DINOv2-base。
DINOv2-base相比InternViT-6B模型在训练集上能获取更高的预测准确率,表明DINOv2-base模型对杂草训练数据的拟合能力更强,能够更好地挖掘杂草图像数据中的图像信息和特征信息。测试集的预测效果可反映模型的泛化能力,即对新数据的预测能力。DINOv2-base模型的测试集准确率高于InternViT-6B,说明DINOv2-base模型在面对未见过的数据时,能够更准确地进行预测,具有更好的泛化性能。
3.2 不同单物种最低样本量数据集的对比
为了研究数据集中样本数量对模型性能的影响,设定了多个单物种最低样本量阈值,从而得到多个不同的数据集。具体来说,分别设置单物种最低样本量阈值为100、500、1000、1500、2000、3000,根据这些阈值对原始数据集进行筛选,保证每个类别的样本数都不低于相应的阈值,得到6个不同的数据集,见表4。
表4 不同单物种最低样本量下的数据集
Table 4 Dataset statistics with varying minimum sample
size per species
单物种最低样本数 (张) | 杂草种数 (种数+同属近似种数) | 总样本数 |
100 | 216 (135+81) | 1028448 |
500 | 189 (117+72) | 1021817 |
1000 | 168 (102+66) | 1006231 |
1500 | 140 (76+64) | 972072 |
2000 | 115 (58+57) | 927556 |
3000 | 85 (35+50) | 855040 |
实验中,对于每个数据集都使用基座大模型提取样本图像表征向量,并连接相同结构的分类任务头模型进行训练和预测评估,即对6个不同的数据集均使用DINOv2-base作为基座大模型连接相同的分类任务头模型进行训练,并评估模型在测试集上的top1及top5准确率,对比结果如图2所示。
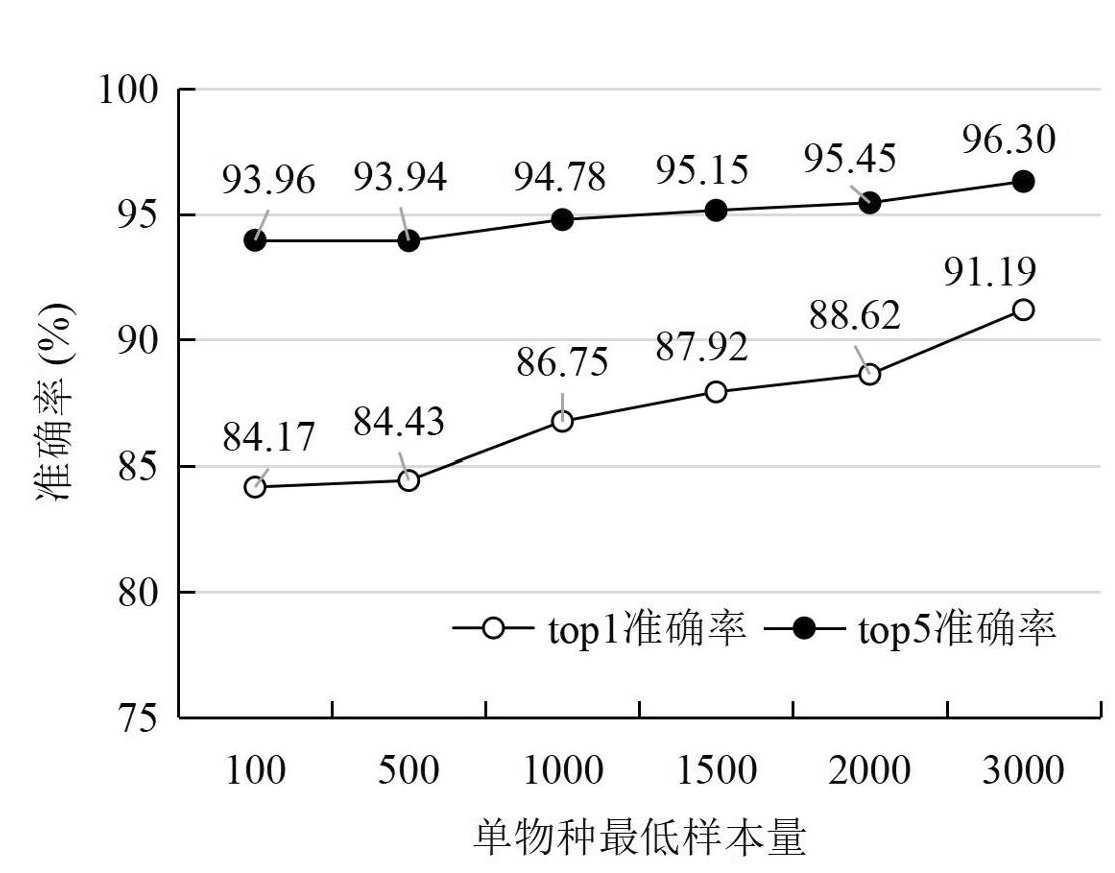
图2 各类单物种最低样本量数据集的测试集预测结果
Fig.2 Prediction results on test datasets with varying minimum sample sizes per species
随着数据集单物种最低样本量的增加,模型在各数据集上的准确率都呈上升趋势,其中top1准确率从类最低样本数100时的84.17%上升至3000时的91.19%,top5准确率同样从93.96%上升至96.3%。这表明更多的类别样本数有助于模型更好地学习和拟合相应的类别特征,且与中国科学院植物研究所研发的植物物种识别模型79.3%的top1识别准确率和91.0%的top5识别准确率相比,均有一定的提升[14]。
在各个数据集的验证中,测试集的top5准确率均高于top1准确率,且提升幅度较大,说明模型在进行多类别预测时给出多个候选预测结果,命中正确类别的可能性更高。
当最低样本数从1000增加至3000时,top1准确率的提升幅度大于top5准确率,表明随着样本数的不断增加,模型预测单一类别的效果提升更明显。
随着单物种最低样本量的增加,模型预测标签种数逐渐减少,从100时的216降至3000时的85。在样本数有限的情况下,为了保证模型性能,可减少种别数量,以集中数据特征,提高模型对主要类别的学习效果。当种数减少时,模型可能更容易聚焦于主要种,减少了种别之间的混淆,从而提高了预测准确率。这也说明在数据集中时,种别之间的样本分布可能存在不均衡的情况,适当调整种别数量有助于优化模型性能。
3.3 参数高效微调方法
为进一步提高识别准确率,本研究基于AdaptFormer 框架的参数高效微调方法(Parameter-Efficient Fine-Tuning,PEFT)[15],对DINOv2-Base 预训练模型进行适配,以实现高效的下游视觉任务处理。整体架构由三部分协同构成:冻结的 DINOv2 主干网络、插入式可训练的 AdaptFormer 模块以及自定义的任务头(Classification Head),如图3所示。
DINOv2-Base模型是一个预训练的图像表征模型,由 12 层Transformer Encoder搭建而成,具备卓越的图像特征提取能力。在整体架构中,该主干网络参数保持冻结状态,旨在降低训练过程中的计算与存储开销。
AdaptFormer模块是提升参数利用效率的关键组件,其由图3中的Down、Relu、Up和S等组成,被并行嵌入至每个Transformer层的前馈子网络(Feed-Forward Network,FFN)中。具体而言,AdaptFormer模块首先对中间特征维度进行压缩,将其降至较低维度(如64维),此操作有效减少了后续计算量与参数数量。接着,经过线性变换将压缩后的特征还原至原始维度,并通过缩放因子(如0.1)对输出进行调控,实现与主干特征的有机融合。这种设计在大幅降低参数数量的同时,巧妙增强了模型对下游任务的适应能力,使模型能够在有限参数调整下快速适配新任务。
分类头采用增强型多层感知机结构,其核心功能是将输入的图像特征(如768维CLS token)精准映射至高维隐藏空间。在此过程中,特征首先经过线性变换实现维度提升,随后通过非线性激活函数引入非线性因素,增强模型的表达能力,再经Dropout正则化防止过拟合,最终输出至最终分类层,完成下游任务的预测功能。
在参数分布方面,DINOv2-Base Backbone 包含约 85.7 M 参数,占据总模型参数的 97%,可训练部分仅涵盖AdaptFormer模块(约1.19 M,占比 1.4%)和任务头(约0.8~1.0 M,占比 1.1%)。因此,在整体训练过程中,仅需更新2%~3% 的参数,为大规模视觉模型的快速适配提供了可行方案。
本研究将图像数据集按照 ImageNet 格式随机分配为训练集(80%)、验证集(10%)和测试集(10%)。在具体设置中,仍然按照每类图像样本的最小数量(100、500、1000、1500、2000、3000)构建不同规模的数据子集,并评估模型在测试集上的top1及top5准确率,结果如图4所示。
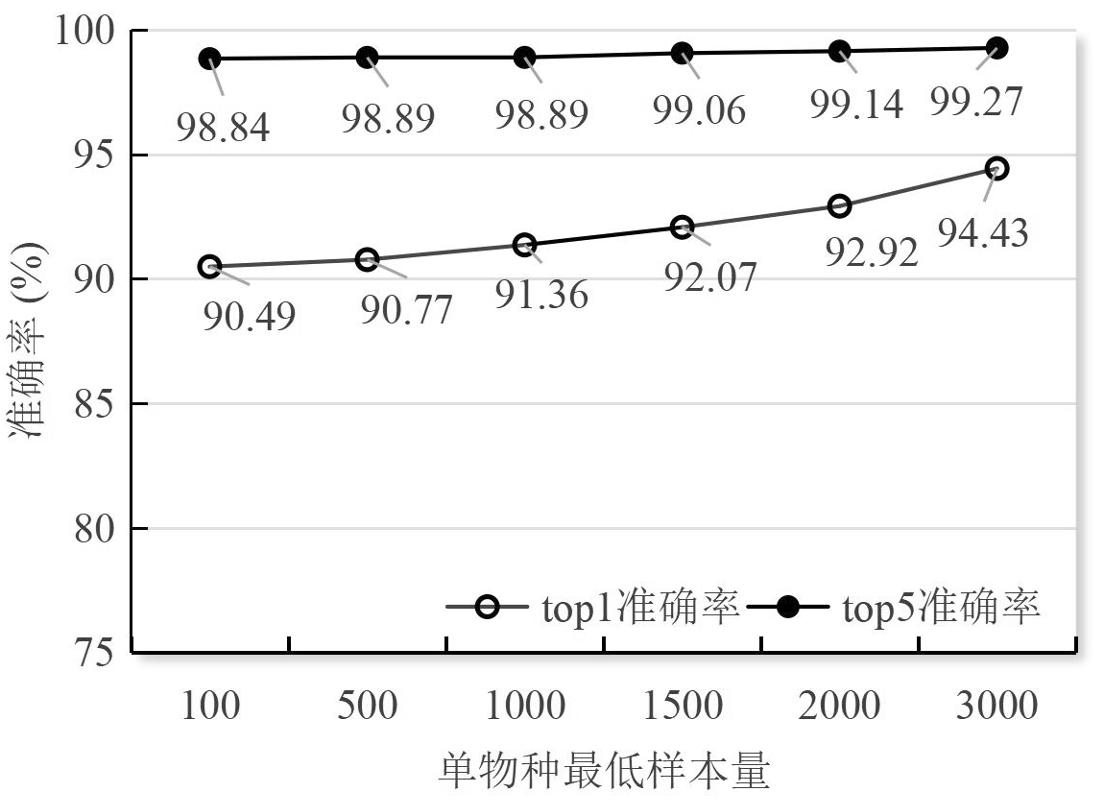
图4 各类单物种最低样本量数据集的测试集预测结果(PEFT)
Fig.4 Prediction results across datasets with varying minimum sample sizes per species (PEFT)
随着每类图像数量的逐步增加,模型的性能同样呈现出显著提升趋势,其中top1准确率从类最低样本数100时的90.49%上升至3000时的94.43%,分别比未经过微调的提高了6.32和3.24个百分点;top5准确率从98.84%上升至99.27%,分别比未经过微调的提高了4.92和2.97个百分点。
这一结果充分表明模型具有较高的类别覆盖能力与预测鲁棒性,能够在复杂多变的图像分类任务中准确识别目标类别,有效避免误判情况的发生,同时验证了在参数效率与性能之间可以实现良好平衡。尽管仅对极少部分参数进行微调,模型在多种数据规模设置下均能保持稳定的表现,充分体现了参数高效微调方法在视觉表示学习领域的可行性与实用性。该方法为视觉大模型在不同资源条件下的快速适配与高效应用提供了新的思路与解决方案,有望推动视觉大模型在更多实际场景中的广泛应用。
4 结语
本研究探索了视觉大模型在口岸杂草检疫领域的应用,系统分析了国内外视觉大模型应用于口岸杂草检疫领域的可行性,针对口岸杂草监测、普查和疫情防控识别的专业需求构建了一个包含87属216种、共计1028448个样本的大规模杂草图像数据集,创新性地采用大模型结合任务头的方式构建杂草图像分类模型,并通过基于 AdaptFormer框架的参数高效微调方法取得了较好的性能。
通过构建大规模数据集、设计合理的模型架构、利用有限的训练资源,实现了对上海口岸216种常见、重点关注和检疫性杂草及其同属近似种的精准识别。经在上海部分口岸试点应用,该模型可满足辅助现场关员识别杂草的需求。该方法也可推广应用于农业生产、生态保护、林业资源管理等领域。
参考文献
[1] NOOR M H M, IGE A O. A survey on state-of-the-art deep learning applications and challenges[EB/OL]. arXiv: 2403.17561, 2024. [2024-03-26]. https://arxiv.org/abs/2403.17561.
[2] 樊云阁, 吕玉辉, 韩红旗. 基于情境感知注意机制的出租车需求深度学习预测模型[J]. 计算机应用与软件, 2023, 40(7): 41-49.
[3] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16x16 words: transformers for image recognition at scale[EB/OL]. arXiv: 2010.11929, 2020. [2020-10-29]. https://arxiv.org/abs/2010.11929.
[4] ALEC R, KIM J W, HALLACY C, et al. Learning transferable visual models from natural language supervision[C]//International conference on machine learning, 2021: 8748-8763.
[5] CARON M, TOUVRON H, Misra I, et al. Emerging properties in self-supervised vision transformers[C]//Proceedings of the IEEE/CVF international conference on computer vision, 2021: 9650-9660.
[6] OQUAB M, DARCET T, MOUTAKANNI T, et al. DINOv2: learning robust visual features without supervision[EB/OL]. arXiv: 2304.07193, 2023. [2023-04-14]. https://arxiv.org/abs/2304.07193.
[7] CHEN Z, WU J, WANG W, et al. InternVL: Scaling up vision foundation models and aligning for generic visual-linguistic tasks[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024: 24185-24198.
[8] CHEN Z, WANG W, CAO Y, et al. Expanding performance boundaries of open-source multimodal models with model, data, and test-time Scaling[EB/OL]. arXiv: 2412.05271, 2024. [2024-12-06]. https://arxiv.org/abs/2412.05271.
[9] WANG P, BAI S, Tan S, et al. Qwen2-VL: Enhancing vision-language model’s perception of the world at any resolution[EB/OL]. arXiv:2409.12191, 2024. [2024-09-18]. https://arxiv.org/abs/ 2409.12191.
[10] BAI S, CHEN K, LIU X, et al. Qwen2.5-VL technical report[EB/OL]. arXiv: 2502.13923, 2025. [2025-02-19]. https://arxiv.org/abs/2502.13923.
[11] WANG W, LV Q,YU W, et al. CogVLM: visual expert for pretrained language models[C]//Advances in Neural Information Processing Systems 37, 2024: 121475-121499.
[12] HONG W, WANG W, DING M, et al. CogVLM2: visual language models for image and video understanding[EB/OL]. arXiv: 2408.16500, 2024. [2024-08-29]. https://arxiv.org/abs/2408.16500.
[13] TEAM G, ANIL R, BORGEAUD S, et al. Gemini: A family of highly capable multimodal models[EB/OL]. arXiv:2312.11805, 2023. [2023-12-19]. https://arxiv.org/abs/2312.11805.
[14] XIE G, XUAN J, LIU B, et al. FlowerMate 2.0: identifying plants in China with artificial intelligence[J/OL]. The Innovation, 2024, 5(4), 100636. https://www.cell.com/the-innovation/fulltext/S2666-6758(24)00074-2.
[15] CHEN S, GE C, TONG Z, et al. AdaptFormer: Adapting Vision Transformers for Scalable Visual Recognition [J]. Advances in Neural Information Processing Systems, 2022, 35: 16664-16678.
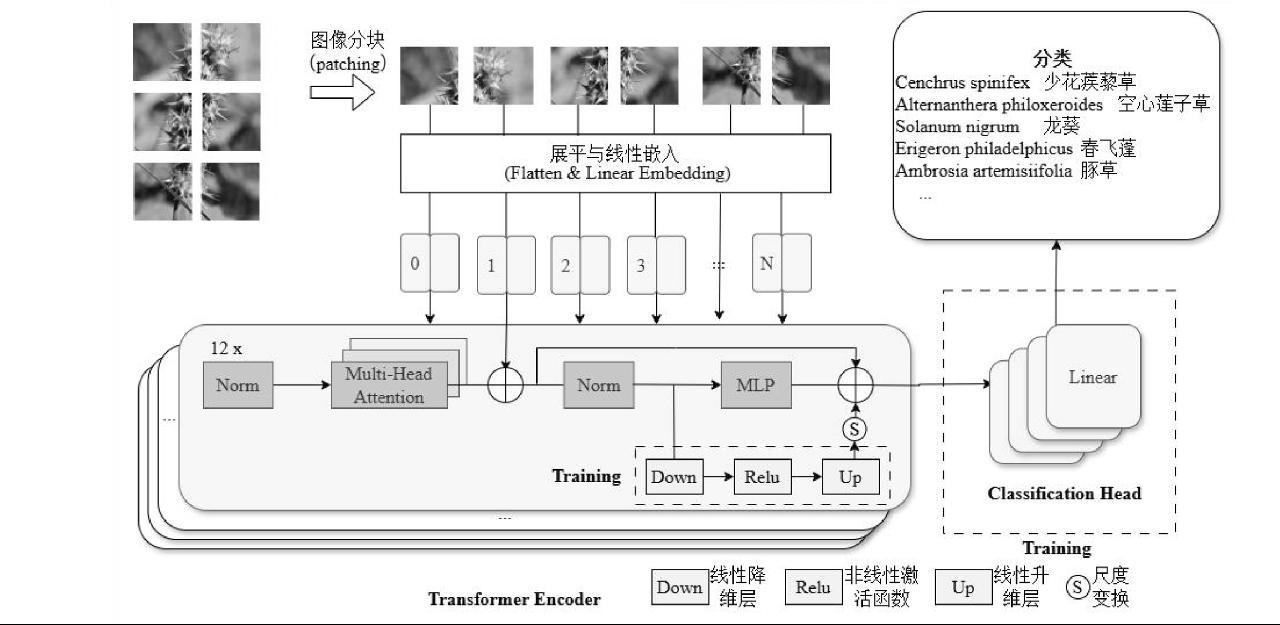
图3 基于 AdaptFormer 框架的参数高效微调方法
Fig.3 The parameter-efficient fine-tuning method based on the AdaptFormer framework
