





CopyRight 2009-2020 © All Rights Reserved.版权所有: 中国海关未经授权禁止复制或建立镜像

RAG及AI编码技术在海关知识库平台中的应用与优化
作者:卓梁雨 万振龙 马超凡
卓梁雨 万振龙 马超凡
卓梁雨 1 万振龙 1 马超凡 2
摘 要 本研究面向海关知识库平台服务场景,梳理了检索增强生成(Retrieval-Augmented Generation,RAG)及人工智能(Artificial Intelligence,AI)编码技术在知识向量化、问答检索与证据生成中的应用现状,并结合平台运行实践提炼可进一步改进的方向。基于此,本研究提出以“文档处理+多路召回+结果控制”的综合优化方案,详细阐述结构化信息补全、切片层级管理、内容标签提取与知识分库等处理措施,以及多路检索与用户确认的闭环机制,并在实施层面应用AI编码技术提升工程实现效率。应用实践表明,该方案能够显著提升命中率与回答质量,为海关知识服务场景下RAG落地与AI编码辅助应用提供可复用的方法路径。
关键词 检索增强生成;海关知识库平台;人工智能编码;文档处理;多路召回
Research on the Application and Optimization of Retrieval-Augmented Generation and AI Coding Technology in the Customs Knowledge Base Platform
ZHUO Liang-Yu 1 WAN Zhen-Long 1 MA Chao-Fan 2
Abstract This study focuses on the knowledge service scenarios of a Customs Knowledge Base Platform. It reviews the current application status of retrieval-augmented generation (RAG) and AI coding technologies in areas such as knowledge vectorization, question-answering retrieval, and evidence generation. Based on platform operational practices, areas for further improvement are identified. We propose an integrated optimization scheme combining document governance, query rewriting and clarification, multi-path recall, and result control. The scheme adds structured metadata, hierarchical chunking, tag extraction with a lightweight model, and knowledge partitioning, and integrates hybrid retrieval with user-confirmed regeneration. At the implementation level, AI coding technology is applied to enhance engineering efficiency. Practical application shows improved hit rate and answer quality, providing a reusable path for RAG deployment and AI-coding-assisted knowledge services within customs domains.
Keywords Retrieval-Augmented Generation (RAG); customs knowledge base platform; AI coding; document governance; multi-path retrieval
第一作者:卓梁雨(1995—),女,汉族,福建宁德人,硕士,中级工程师,主要从事大数据、人工智能方向信息化工作,E-mail: zhuoliangyu@mail.customs.gov.cn
1. 全国海关信息中心 北京 100005
2. 交通运输部路网监测与应急处置中心 北京 100029
1. National Information Center of GACC (General Administration of Customs of China), Beijing 100005
2. Highway Monitoring and Emergency Response Center, Ministry of Transport of the P.R.China, Beijing 100029

1 RAG及AI编码技术在海关知识库平台中的应用现状
1.1 海关知识库平台的建设背景
海关知识库平台聚焦知识碎片化、智能化应用水平等方面,统筹海关全领域知识管理。平台总体架构大致分为数据采集、知识存储与索引、知识全生命周期管理、知识应用服务4个层级,主要技术包括数据治理、混合检索、向量索引与高效召回、证据重排与片段融合、可控生成与引用回溯等。为满足智能化知识服务需求,平台核心问答服务采用检索增强生成(Retrieval-Augmented Generation,RAG)技术的“检索+生成”建模思路,根据不同的业务逻辑编写不同的文档切片等文档处理代码逻辑,通过离线构建知识索引与在线检索生成耦合,实现可追溯、可验证、可更新的回答能力。
1.2 RAG及AI编码技术概述
RAG是一种将信息检索系统与生成式模型耦合的知识密集型问答范式,通过在生成阶段引入外部证据来约束模型输出,实现“可追溯、可验证、可更新”的知识回答。RAG通常由离线的知识构建与在线的检索生成两部分组成:离线侧对文档进行清洗、切分、向量化并建立索引,在线侧根据用户问题检索候选证据,再将证据与问题拼接输入生成模型完成回答[1-2]。与纯参数式大模型相比,RAG将知识外置并支持版本管理,能够在政策更新频繁的业务环境中快速迭代知识、降低模型维护成本,同时满足合规审计与结果可解释的要求。
具体流程可概括为“文档处理—索引构建—多路检索—重排融合—生成与引用”,如图1所示。在处理阶段,需要进行去噪、去重、结构化元数据抽取与段落切片;在索引阶段,通常同时构建稀疏检索与稠密检索索引,稀疏侧以BM25等概率相关模型提供关键词精确匹配能力[3],稠密侧基于双塔或晚交互检索器(如DPR[4]、ColBERT[5])获得语义相似度,并借助FAISS等向量库实现高效召回[6]。在线检索环节通过混合召回扩大覆盖面,再使用交叉编码器或学习排序模型对候选证据重排,结合规则过滤与片段聚合形成最终证据集。生成阶段采用指令化提示将证据与问题组织为可溯源输入,输出回答并附带引用,形成“检索—生成—可追溯”的闭环。
人工智能(Artificial Intelligence,AI)编码技术,指利用AI(特别是大型语言模型)自动或辅助生成、补全、优化程序代码的技术,是人工智能与软件工程领域交叉的重要研究方向。该技术核心在于使机器能理解自然语言描述或部分代码上下文,并生成符合语法与功能需求的高质量代码。其应用范畴已从早期的代码补全,扩展到包括代码翻译、修复、测试生成及漏洞检测等多个软件工程任务[7-9]。
1.3 RAG及AI编码技术在海关知识库平台中的应用
在海关知识库平台中,专家经验、政策文件、操作指引与典型案例等知识数据以结构化字段附加文档附件的形式沉淀。平台将文档附件按照固定长度切片策略进行切片并向量化,构建统一向量库;用户提问时,系统通过向量检索召回相关文档切片,并将切片与问题一起送入大模型生成答案,实现政策文件解读、业务操作咨询等方面的智能问答。
在实际运行中,平台检索召回环节的效能仍面临多方面挑战,主要体现在查询覆盖、结果准度与信息完整性上。这些现象与当前数据处理和召回机制的限制有关:一方面,知识的结构化信息在向量化过程中存在丢失,且固定切片方式破坏了上下文连贯性;另一方面,文档缺乏细粒度标签,检索主要依赖单一路径的向量匹配,难以引入关键词、业务领域等多元信号进行优化。以上因素共同影响了检索结果的精度与覆盖范围,进而制约了生成回答的整体质量。除此之外,目前文档处理等环节采用的人工编码方式,在应对文档切分等处理逻辑复杂多变的情况下,有一定的效率提升空间。
2 RAG及AI编码技术优化措施及效果
为提升海关知识库平台RAG应用的检索精度、召回覆盖度与问答可控性,本研究围绕文档处理、多路召回、结果控制等关键环节提出优化方案,并给出流程化实施路径。通过结构化信息补全、层级切片、内容标签管理、知识分库等处理措施,结合混合检索与用户确认机制,形成从知识入库到答案生成的整体优化框架。在实施层面,引入AI编码自动生成文档切分逻辑与结果控制相关代码,以降低工程实现成本并提升迭代效率。
2.1 通过文档处理提升检索精度
2.1.1 结构化信息补全
海关知识库平台中的知识数据通常由结构化字段与文档附件共同组成,前期仅对文档附件切片向量化,导致标题、文号、业务条线等关键结构化信息未进入检索链路。因此,建立结构化字段与文档附件的强关联关系,是提升检索精度的基础。具体做法是以知识数据的结构化字段为主索引,在入库阶段将文档附件与其所属结构化记录绑定,同时将知识数据的标题、文号、发布部门、适用业务条线、生效时间、监管属性等结构化信息写入文档切片的元数据,形成统一的“文档—切片—字段”元数据模型,保证检索时可按结构化字段精确定位,并为后续引用溯源提供结构化依据。
结构化信息能够为检索提供高置信度的过滤与排序关键词。一方面,标题、文号等字段具有强唯一性,可精准定位法规与公告等文档;另一方面,业务条线、监管方式等字段可作为检索先验约束,降低跨领域干扰。在检索阶段先基于结构化字段做规则过滤,如限定条线、监管方式或时效范围,再进入向量召回;在重排阶段将结构化匹配分数与语义分数融合,形成可解释的综合排序。这样既减少候选集合规模,也提高首轮命中率和答案可信度。
2.1.2 上下文管理
前期平台使用的固定长度切片策略导致出现上下文割裂现象,长条款与跨段落条件被拆分到不同的切片中,为解决该问题,平台对切片策略进行优化,建立与业务语义一致的切片边界。平台对8000字以内的短文档采用全文分段策略,保持原段落结构并保留标题层级;对超过8000字的长文档采用父子分段策略,以章节为父块、段落为子块建立层级关系,并在向量库中保存父块与子块的双向索引;对于专项调优场景,可依据业务逻辑进行定制切片,例如按流程节点、表单字段或条款编号切分。为保证切片策略落地一致性,借助AI编码自动生成切片规则与父子块映射实现代码,支持快速调整与复用[10-11]。
分层切片能够在保证召回粒度的同时降低上下文割裂的发生概率,从而保证检索的完整性。一方面,当子块被召回时,可根据父块关系自动扩展相邻段落,形成更完整的证据上下文用于生成阶段,避免模型仅基于孤立片段作答,特别是对于跨段落引用的条款,通过父块级别补全可避免遗漏关键上下文信息。另一方面,父块提供宏观语义框架,子块提供细粒度证据,有助于检索阶段先定位章节再定位具体条款。
2.1.3 内容标签提取
海关知识库平台中的文档规模庞大,在未经过标签提取等数据处理的情况下,文档不具备细粒度的内容标签,因而在检索时不易缩小查询范围。为此引入轻量级生成模型,使用生成模型+提示词的方式对文档进行自动化内容标签提取。标签提取规则提示词包括:(1)标签需简洁明了,以短语形式呈现,如“跨境电商报关”“关税税率”,避免冗长描述;(2)优先提取文档独有关键词,如海关专属法规名称、特殊监管模式术语,此类标签标识性强,需重点保留;(3)禁止生成无用标签,如“海关相关”“业务文档”等无法缩小检索范围的泛化表述;(4)按海关业务条线定向提取标签,确保标签与条线强关联;(5)为每个文档生成多个核心标签,不超过5个。生成的内容标签按业务条线存入独立标签库,并与文档元数据绑定形成映射关系。
高质量标签库能够缩小检索候选集合并提升召回精准度。标签是介于结构化字段与文本语义之间的“半结构化信号”,可实现快速过滤与业务领域聚焦。同时,标签与文档元数据绑定后,作为混合检索的强约束,在同义表达、术语变体场景下能够发挥稳定检索效果。内容标签后续还可作为权限控制与敏感内容过滤的依据,提升安全性。
2.1.4 知识分库
海关知识库平台的数据普遍带有知识分类标签,依据知识分类构建多个RAG知识分库,用户提问时可选择对应的知识类别,仅在指定分库中进行检索。
知识分库能够显著缩小检索范围与降低跨领域噪声,同时便于对分库进行权限隔离管理,从而提升检索精度与回答一致性,减少跨库误召回。
2.2 通过多路召回扩大召回覆盖面
前期平台仅依赖向量相似度进行单路召回,缺乏关键词和内容标签等互补信号。为提高召回覆盖度,将单一召回链路扩充为“内容标签匹配召回+结构化关键词召回+向量召回”的三路并行召回机制。召回路径一为内容标签匹配召回,使用用户查询中提取的标签匹配文档标签库,先匹配到文档标签,再从具有匹配标签的文档集合中召回相关文档切片;路径二为结构化关键词召回,基于从用户查询中提取的检索词,精准检索文档元数据中的标题、文号等结构化字段,获取高相关切片;路径三为向量召回,将完整问题向量化后在知识向量库中检索相似问答案例切片,补充语义相似但关键词不一致的内容。三个路径结果在召回规模、相似度阈值与权重上进行差异化配置,经过去重、权重融合与重排,形成最终候选证据集,并在生成阶段强制引用来源以保证可追溯性。
多路召回能够兼顾精确匹配与语义泛化。标签与关键词路径提供高精度过滤,向量路径提供语义扩展与同义召回,三路融合可显著减少单一路径的盲区。在业务领域知识密集且术语差异显著的场景中,多路召回能够提升长尾问题的覆盖率,同时避免仅靠向量相似度带来的语义漂移。通过对不同路径赋权与重排,系统可在召回覆盖与精度之间取得平衡,提升复杂问题与跨条线问题的命中率,降低因召回不足导致的“无相关信息”反馈,并为结果控制提供更稳定的证据基础。多路召回还能支撑不同问题类型的路由策略,例如事实类优先关键词召回、流程类优先标签召回、解释类优先向量召回。长期来看,多路召回为检索系统提供了可监控、可调参的处理抓手。
2.3 通过结果控制优化生成回答可控性
海关知识库平台覆盖多业务领域,同一问题在不同领域下可能存在不同答案,系统即便召回完整,也可能导致结果排序与生成失配,为此,引入“用户确认—再检索—重生成”的结果控制机制提升答案可控性。用户输入需查询问题,通过上述召回、生成阶段生成回答后,在答案下方列出所有关联文档,含文档ID、名称、摘要等详细信息,用户可单选或多选文档,确认选择后触发重新生成流程,具体如下:(1)系统接收用户勾选的一个或多个文档信息;(2)进行针对性检索,仅从这些文档中提取相关内容切片,无需再次执行多路召回;(3)模型基于所选文档切片生成精准匹配答案,强制携带来源,从而降低误答风险。结果控制机制引入人工可信反馈,形成“人机协同”的检索闭环。结果控制流程的接口编排与校验逻辑通过AI编码生成模板化代码,加速上线与策略迭代。通过用户对文档范围的确认,系统将不确定性转移为可控选择,显著降低误召回导致的错误回答,并提高答案的业务可解释性。用户选择行为后续还可沉淀为训练样本和质量信号,用于重排策略与内容标签的持续优化,从而形成可迭代的质量提升机制。在高风险问题上可设置强制确认环节,以降低合规风险,形成可追溯的责任链条,提升合规透明度。
3 应用效果
综合上述优化措施,平台问答流程优化为“文档处理—多路召回—重排—结果控制”四步。用户提问后,系统先通过标签与关键词缩小范围,再以向量检索覆盖语义相似内容,经重排形成高质量证据集,最终生成可追溯答案。文档处理引入AI编码技术,实现海关法规等文档的自动切片,提升预处理效率;针对复杂问题,可在父子切片层级扩展上下文,并通过AI生成的结果控制机制引导用户确认证据来源,增强回答稳定性。各项优化从数据质量、检索策略、交互控制三方面协同提升检索精度。
本研究选取海关知识库平台关税条线下1549份文档以及由业务专家提供的350个问答对作为评测集。评测使用Qwen3-4B模型作为内容标签提取模型,DeepSeek-R1-671B模型为基础生成模型,使用Qwen3-32B模型对照350个标准答案进行打分,从准确性、完整性、逻辑性、语言表达四维度评价,其中准确性40分、完整性30分、逻辑性15分、语言表达15分;准确性侧重法规一致性与核心数据准确性,完整性关注要点覆盖与关键步骤/依据/指标不遗漏,逻辑性考察业务逻辑与结构清晰度,语言表达要求术语规范、无歧义。对350个问题分别使用优化前后的RAG方案生成答案,综合评分由77.71提升至93.08,提升幅度显著。从工程实现角度看,AI编码在关键模块开发中的辅助应用,有效缩短了系统迭代周期,为优化方案的快速验证与部署提供了技术支撑,这验证了本研究论述的优化方案对检索质量与回答可信度的提升作用。
4 结语
本研究针对海关知识库平台RAG应用,从文档处理、多路召回及结果控制三方面提出优化方案。通过结构化信息补全、层级切片、标签化处理与知识分库,结合混合检索与可控生成机制,构建“入库—检索—生成—校验”闭环流程,显著提升检索命中率与答案质量。实施中引入AI编码技术,实现文档处理自动代码生成,大幅提高工程效率,为海关知识服务系统提供可复用的技术路径。该方案强调“以检索质量驱动生成质量”,突出标签化与结构化字段对RAG可靠性的提升作用,同时通过结果控制增强可解释性与风险可控性,具备良好工程可行性。
尽管该方案已取得成效,未来仍需进一步优化:一是利用AI编码构建全流程反馈与日志分析机制,记录知识全生命周期日志,实现“反馈—分析—优化”闭环运营;二是引入意图分类与个性化检索,按问题类型及用户画像实现精准服务;三是探索RAG与知识图谱深度融合,通过实体关系约束与规则增强提升推理能力,并建立评测基准实现持续评估。后续可借助AI编码自动生成图谱构建、规则映射与查询优化等代码逻辑,提升系统自动化与可维护水平。
参考文献
[1] Lewis P, Perez E, Piktus A, et al. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks[J]. Advances in Neural Information Processing Systems, 2020, 33: 9459-9474.
[2] Gao Y, Xiong Y, Gao X, et al. Retrieval-Augmented Generation for Large Language Models: A Survey[EB/OL]. (2024-3-27) [2026-01-19]. https://arxiv.org/abs/2312.10997.
[3] Robertson S, Zaragoza H. The Probabilistic Relevance Framework: BM25 and Beyond[J]. Foundations and Trends in Information Retrieval, 2009, 3(4): 333-389.
[4] Karpukhin V, Oğuz B, Min S, et al. Dense Passage Retrieval for Open-Domain Question Answering[EB/OL]. (2020-09-30) [2026-01-19]. https://arxiv.org/abs/2004.04906.
[5] Khattab O, Zaharia M. ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT[EB/OL]. (2020-06-04) [2026-01-19]. https://arxiv.org/abs/2004.12832.
[6] Johnson J, Douze M, Jégou H. Billion-scale similarity search with GPUs[J]. IEEE Transactions on Parallel and Distributed Systems, 2021, 32(3): 605-618.
[7] Chen M, Tworek J, Jun H, et al. Evaluating Large Language Models Trained on Code[EB/OL]. (2021-07-14) [2026-01-19]. https://arxiv.org/abs/2107.03374.
[8] Nijkamp E, Pang B, Hayashi H, et al. CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis[EB/OL]. (2023-02-27) [2026-01-19]. https://arxiv.org/abs/ 2203.13474.
[9] StarAI Labs. StarCoder: may the source be with you![EB/OL]. (2025-10-15) [2026-01-19]. https://www.starai.com/StarCoder/source-paper.
[10] Roziere B, Chandak V, Tazi N, et al. Code Llama: Open Foundation Models for Code[EB/OL]. (2024-01-31) [2026-01-19]. https://arxiv.org/abs/2308.12950.
[11] Wang Y, Le H, Han D, et al. CodeT5+: Open Code Large Language Models for Code Understanding and Generation[EB/OL]. (2023-05-20) [2026-01-19]. https://arxiv.org/abs/2305.07922.
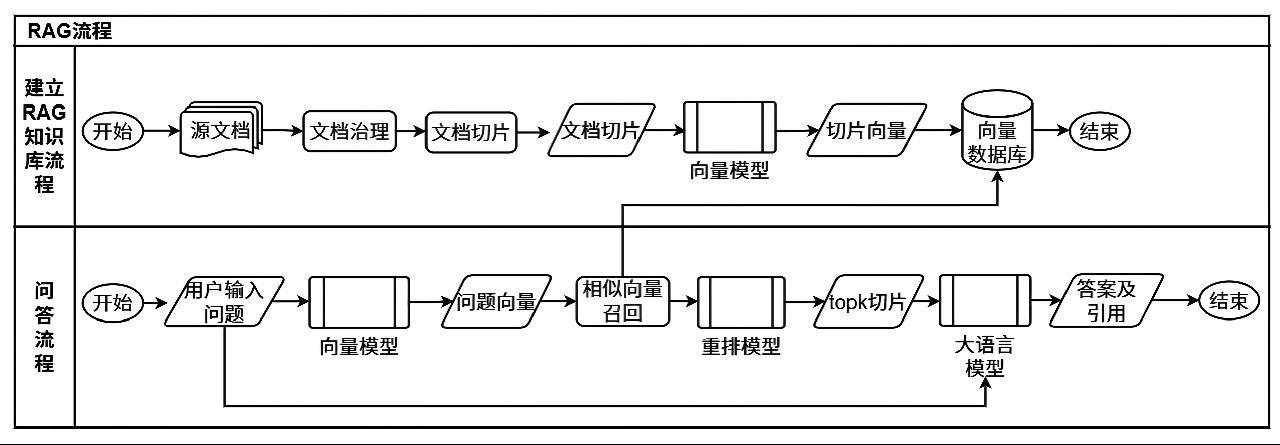
图1 RAG流程示意图
Fig.1 Schematic diagram of the RAG process
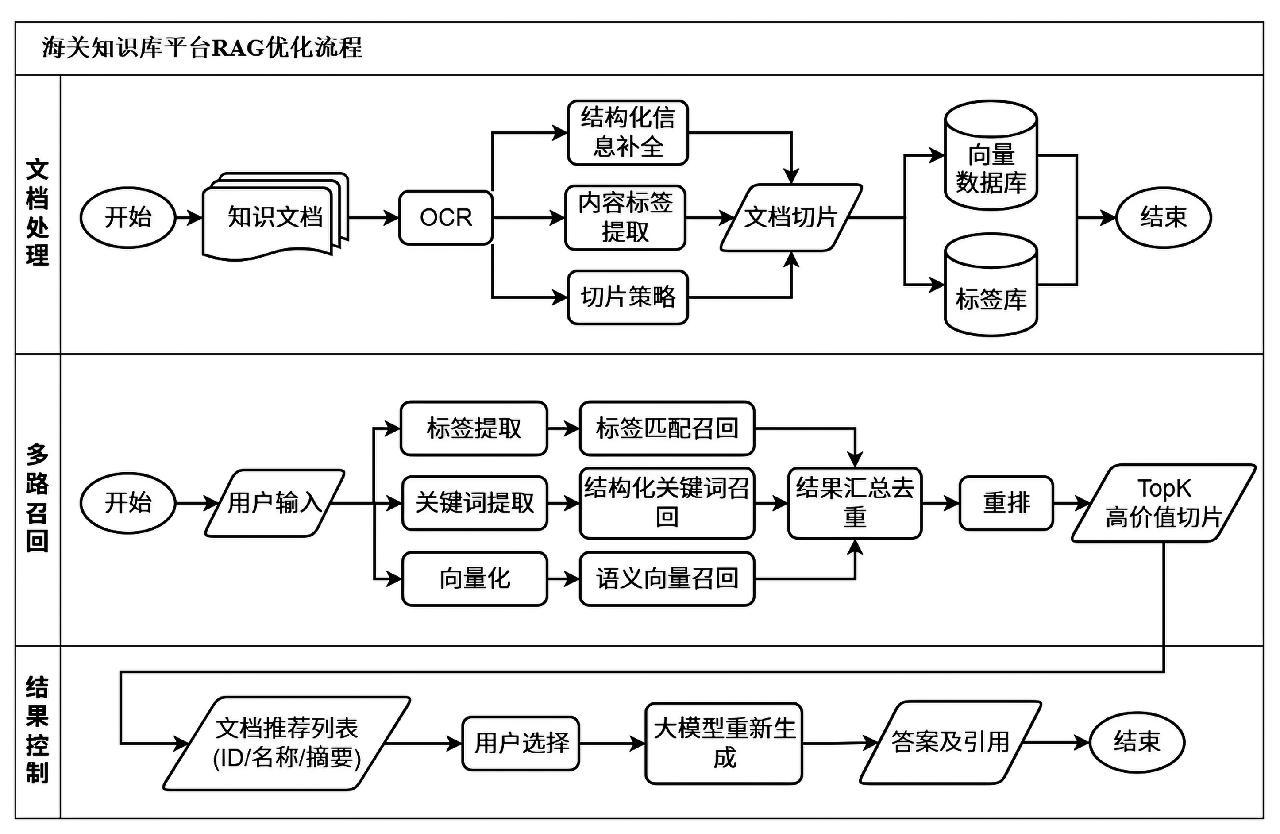
图2 海关知识库平台RAG优化流程示意图
Fig.2 Schematic diagram of the RAG optimization process for the Customs Knowledge Base Platform
